168大数据
标题: 数据仓库之数据模型 [打印本页]
作者: 168主编 时间: 2019-3-29 18:39
标题: 数据仓库之数据模型
本帖最后由 168主编 于 2020-3-12 17:14 编辑
关于数据仓库的概念,这里不再累赘。先看下面的图(数据仓库建设的7个主要环节):
本文,主要针对第三块数据仓库模型设计来讨论交流,尤其是互联网行业。
一、关于数据仓库数据模型
1. 数据仓库数据模型是指使用实体、属性及其关系对企业运营和逻辑规则进行统一的定义、编码和命名;是业务人员和开发人员之间沟通的一套语言。
2. 数据仓库数据模型的作用:
- 统一企业的数据视图;
- 定义业务部门对于数据信息的需求;
- 是构建数据仓库原子层的基础;
- 支持数据仓库的发展规划;
- 初始化业务数据的归属;
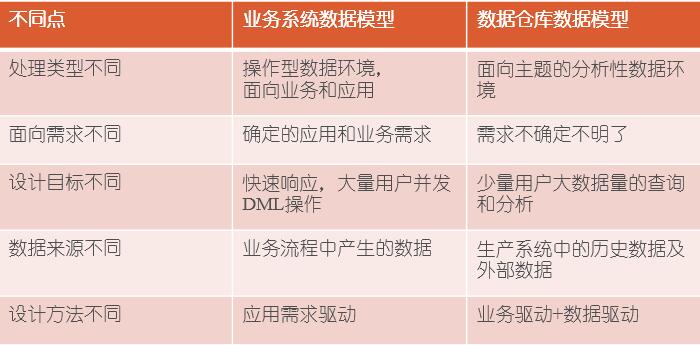
3. 数据仓库数据模型与业务系统数据模型设计的区别:
4. 数据仓库数据模型设计的先后次序
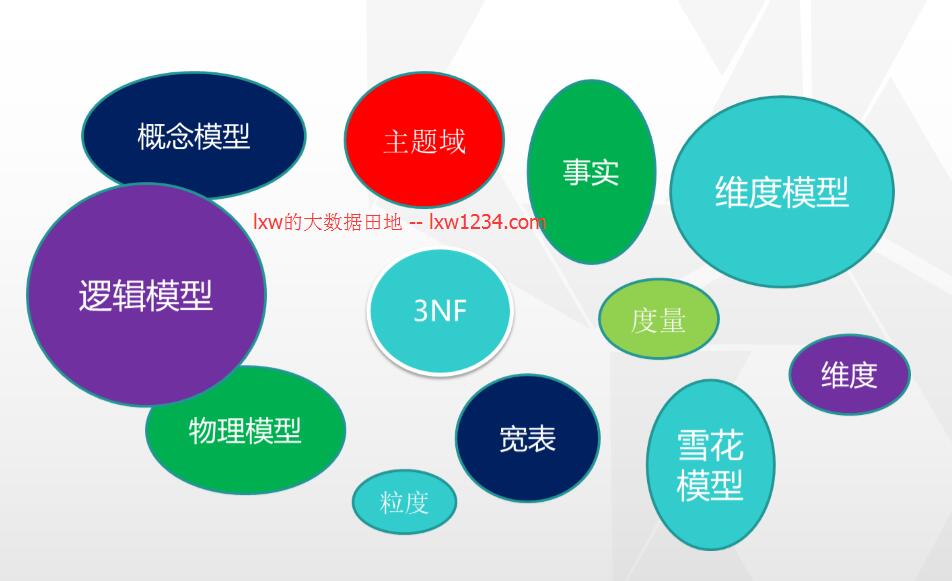
- 概念模型设计(业务模型):界定系统边界;确定主要的主题域及其内容;
- 逻辑模型设计:维度建模方法(事实表、维度表);以星型和雪花型来组织数据;
- 物理模型设计:将数据仓库的逻辑模型物理化到数据库的过程;
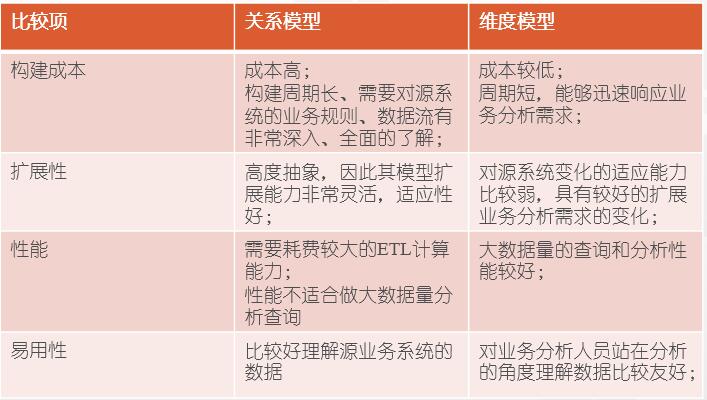
二、关于维度模型和关系模型
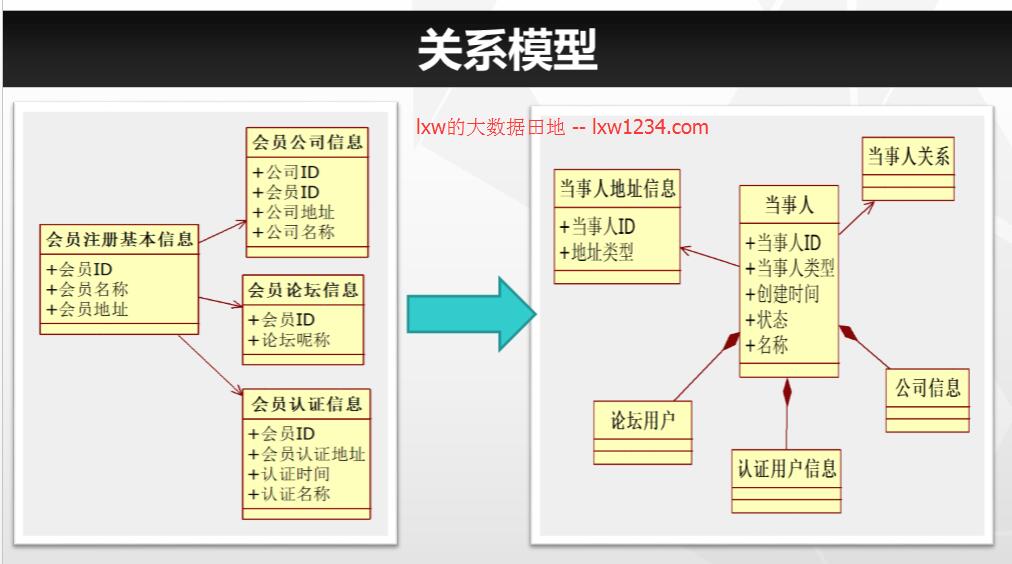
关系建模又叫ER建模,是数据仓库之父Inmon推崇的,其从全企业的高度设计一个3NF模型的方法,用实体加关系描述的数据模型描述企业业务架构,在范式理论上符合3NF,其是站在企业角度进行面向主题的抽象,而不是针对某个具体业务流程的,它更多是面向数据的整合和一致性治理,正如Inmon所希望达到的“single version of the truth”。
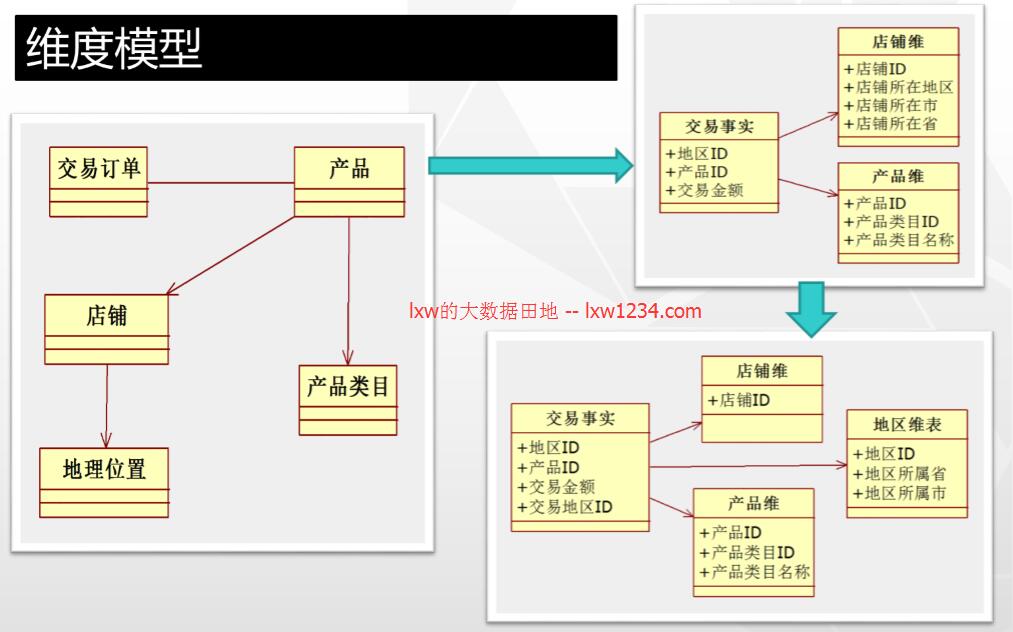
维度模型则是数据仓库领域另一位大师Ralph Kimball 所倡导的。维度建模以分析决策的需求为出发点构建模型,一般有较好的大规模复杂查询的响应性能,更直接面向业务,典型的代表是我们比较熟知的星形模型,以及在一些特殊场景下适用的雪花模型。
两者的主要区别在于灵活性和性能方面。
另外,关系模型要求数据以最细粒度存在,而多维模型则以轻粒度汇总数据存在。
(记得十年前,某大型保险公司实施EDW项目,采用的就是关系模型,由IBM专门的团队负责建模,好家伙)。
在我看来,如果不是实施业务相对成熟的EDW,大多数据仓库均会采用维度模型建模;
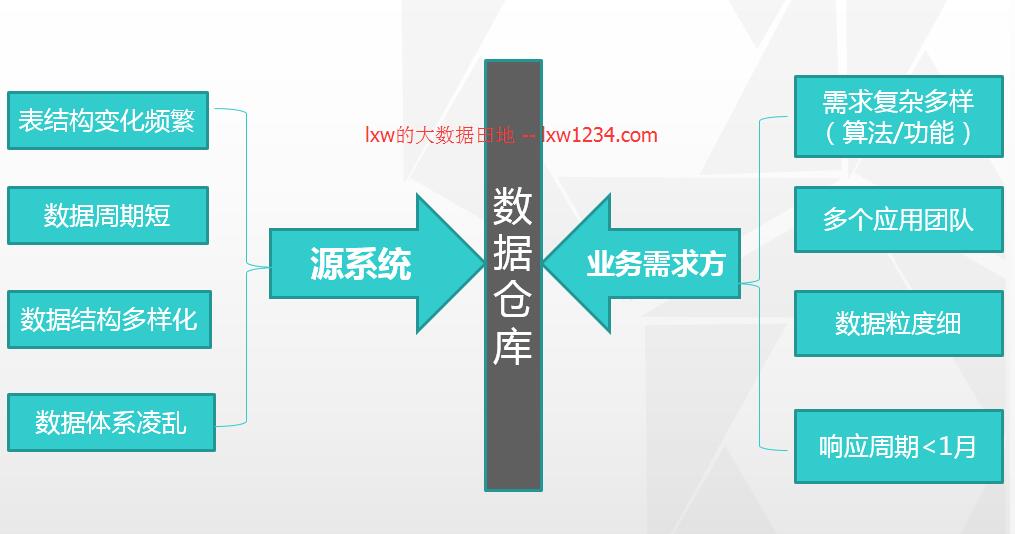
三、互联网数据仓库数据模型1. 互联网数据仓库的现实状况
2. 我们的模型方法选择
在我们的数据仓库中,除了各个主题域下的维度模型,还存在一些宽表模型。所谓宽表模型,是基于维度模型的扩展,采用退化维度的方式,将不同维度的度量放入数据表的不同的列中;它更易于理解,具有更高的查询效率;易于模型扩展;
事实证明,在海量数据环境下,对业务查询的支撑,宽表在性能和易用性方面,都达到了比较理想的效果。
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |