168大数据
标题: 【经典】SAP Hana学习笔记 [打印本页]
作者: 168主编 时间: 2016-1-27 22:07
标题: 【经典】SAP Hana学习笔记
本帖最后由 168主编 于 2016-1-27 22:15 编辑
本文内容主要整理自《内存数据管理》第二版,以及书中提到的参考文献。很多图片也是论文截图,或对照书中图片重新绘制。顺便说一句,这部书内容很好,提供了内存数据库从学术到业务实践的全貌介绍,但明显隐藏了许多细节,而且中文翻译错误有点多。
内存数据库为什么内存计算(数据库)是趋势? 需要极高并发事务
1)磁盘容纳全部数据,内存缓存热点:MySQL
2)内存处理并发事务,磁盘容纳历史数据:OceanBase,Hana
3)主备复制强一致,只有内存数据库可以做到
实时分析的商业价值:
1)对于核心决策者:快速报表,等于快速决策,等于利润(金融,零售)
2)对于一线员工:快速充分利用大数据帮助工作(销售人员、医生)
3)对于公司:节省IT、财务方面的硬件和人力资源
现有分析系统的问题:
1)数据聚合,不及时,不精确,灵活度低
2)导入hadoop,延时高,浪费资源
3)应用层计算,浪费资源,带宽受限
内存数据库需要解决三个主要问题
- 内存容量有限
- 即使100G-1T级别的内存服务器,仍然小于许多大型业务的数据量
- 内存很大一部分需要用于临时计算(Join、排序等)
- 高效利用多核CPU
- 内存的IO能力远高于磁盘,CPU更容易成为资源瓶颈(传统数据库中,CPU优化不好会被其它瓶颈掩盖)
- 操作系统的任务调度造成大量上下文切换开销
- 容灾
解决内存容量问题轻量级压缩 字典压缩是Hana的默认压缩方案,机制比较简单,简单提供一张图片说明。字典压缩的好处不仅在于节省内存空间,更在于可以充分利用CPU的向量运算能力,后面的内容会具体说明。
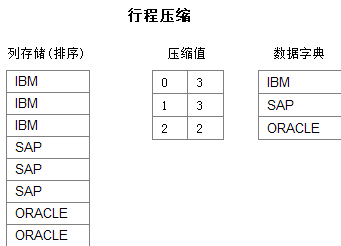
行程压缩(RLE)是针对排序列的字典压缩优化,由于连续出现大量相同值,该算法使用相同值的重复次数替代重复的记录。另外,行程编码扫描一个值,相当于扫描了连续的多个值,这样能够进一步节省CPU的计算开销。
数据老化 HANA将数据按照其业务声明周期分为主动和被动两类,即常驻内存数据,以及仅持久化到磁盘(SSD)两类。这个设定的基础是,SAP认为许多企业会存储仅10年的数据,然而绝大部分数据都不再需要更新或用于实时查询。老化策略可以由应用程序定义,例如Hana为SQL建表语句提供了如下扩展
CREATE TABLE lead{
id INT,
name VARCHAR(100),
description TEST,
priority INT,
create_at DATETIME,
origin INT,
result_reason INT,
status INT,
unpdated_at DATETIME),
AGING :=(
status == 4|5 &&
updated_at < SUBSTR_YEAR(Time.now, 1)
);
该建表语句定义的老化策略(AGING部分)是,若订单最后更新时间已经超过1年,且订单处于接收或拒绝状态,则该行数据可以老化处理。这样内存只需要存储未完成(或完成时间在一年以内)的订单。被动数据将不再被普通的SQL语句扫描。应用程序可以在SQL中加入特殊标识,强制要求数据库扫描被动数据。这种特殊SQL请求,可能更新部分被动数据,使其不再满足老化策略,那么被动数据会转化为主动数据。
本质上来说Hana的老化机制,类似于传统数据库依靠DBA手动进行水平分表和数据迁移或存档,不同在于,它将许多本来就可以由业务模型推导出的归档逻辑转换成了自动化的规则,提高了数据库的可维护性。
性能优化列存储 为什么磁盘数据库比较难使用列存储?
- 普通的OLTP操作,需要多列(分布在磁盘非连续位置)并发扫描
- 根据序列号随机定位某列的一个值的IO代价很大
Hana同时支持行存储和列存储,但技术重点在列存储。列存储可获得以下几个优势:
- 较高的数据压缩率
- 同一列下的数据的内容和格式都是相近的,压缩一整块相同列的数据块更有利于提升压缩率
- 动态增删字段(列)
- 对于行存储,增加删除列,需要重组原有的数据内存,以保证新的属性与旧的属性连续存储
- 对于列存储,增加删除列,仅需要开辟或回收一段连续的内存空间
- 对于某些查询,CPU缓存的利用率更高
- 例如一类常用的查询SQL:SELECT * FROM test_table WHERE name = 'john',实际需要CPU进行谓词匹配的列仅为name。
- 对于行存储,由于一行数据所有属性连续存储,每次加载该属性到CPU进行谓词匹配时,都会批量加载其它的属性值到CPU缓存,从而降低了CPU的缓存命中率。
- 对于列存储,所有的name值都连续存储,CPU缓存会充分的利用。
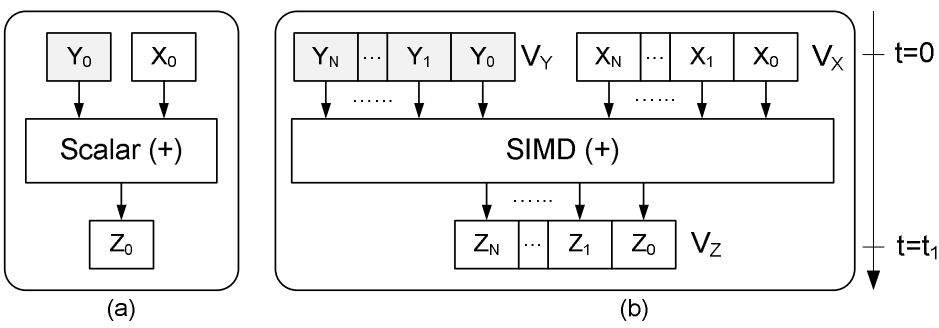
- 利用SIMD指令获得极高的扫描性能,参考文献SIMD-Scan。现代CPU支持单个周期向量处理多个计算(单指令多数据流SIMD),例如通过使用Intel SSE指令,可以实现多组整数在同一个内核cycle进行向量加法,最终得到每组整数的分别求和。
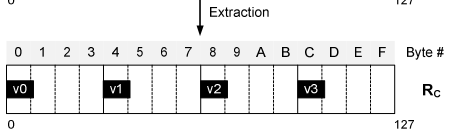
- 基于SIMD的解压缩:将一个字典压缩数据块,向量解析为原始数据块。 论文中32bit整数压缩到固定9bit例子,使用4个指令完成4个值的解压缩:

- mask指令:将前4个压缩值分布到4byte位置(未bit对齐)

- mask指令:将每个压缩值的头部与4byte位置对齐

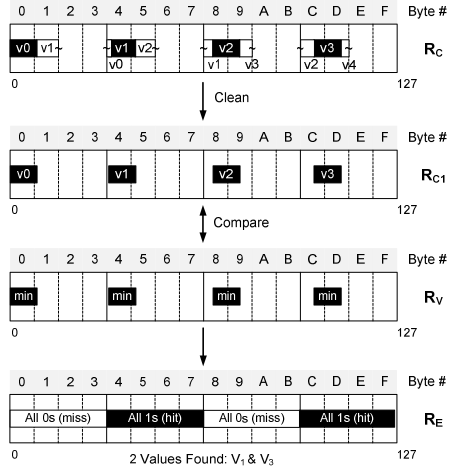
- 基于SIMD的谓词匹配:无需解压缩,直接根据SQL谓词筛选压缩数据块,通常用于等值或范围查询。
- 压缩值向量4字节对齐
- 比较4字节对齐的min向量
- 比较4字节对齐的max向量
- 生成结果向量
增量合并模型 列存储写操作的性能问题:
- 编码位升级问题
- 为了尽可能降低内存占用,Hana使用尽可能少的二进制位数表示一个字典值,例如字典中只有4个值,则只需要用2bit表示。但如果字典中增加第5个值,则数据的位数需要增长一位。这会触发扫描并重建一列的全部数据。对于数百G的内存数据代价也是非常大的。
- 删除操作锁表问题
- 删除一行,需要对全表加锁,否则先后在不同列上进行删除可能导致读操作的不一致
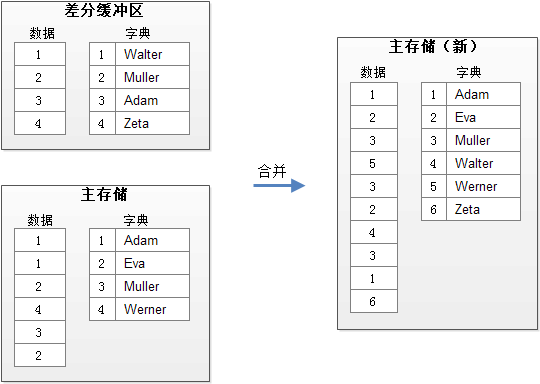
为了解决上述问题,引入差分缓冲区(可以理解为一个写缓冲区),其思路可以概括为:
- 将编码升级和删除操作锁控制在一个较小的数据结构
- 而更大范围的编码升级和删除操作,则通过后台的异步合并完成
熟悉HBase、Cassandra等NoSQL方案的朋友,对于这种(写缓冲区+后台合并)的模型肯定不会陌生。正如图片所示,差分缓冲区维护一个有限容量的内存数据结构,可以顺序的append新的写操作(包括更新和删除),而所有的读操作都需要同时扫描主存储和差分缓冲区,生成合并的结果。而后台合并是异步的,不影响数据库的读写,唯一可能需要加锁的地方在合并完成后替代旧主存储数据的时刻。
这种后台合并机制也决定了,Hana必须预留足够的内存空间同时容纳新旧主存储数据,当然文献中也给出了一种逐列合并的策略,可以有效的将合并所需的临时空间限制在一个列的最大数据总容量。
需要注意的是,差分缓冲区和主存储并不共享字典或字典编号,而需要在合并时生成新的字典
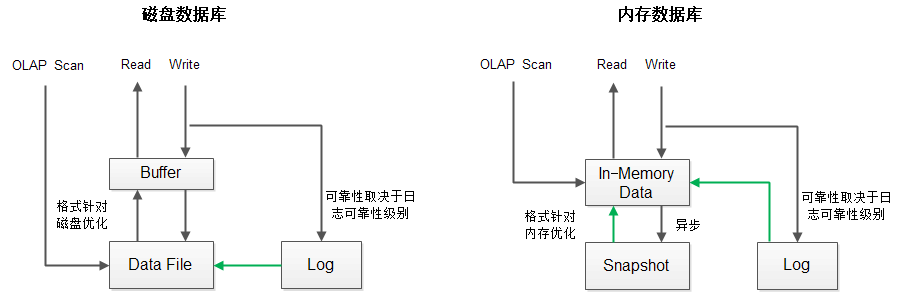
数据可靠性 内存数据库数据更易丢失吗?
- 相同点
- 写操作同步提交到日志模块
- 数据可靠性取决于日志的持久化策略,因此数据可靠性没有本质区别
- 不同点
- 异步生成内存数据快照
- 数据恢复,先将快照加载到内存(需要关注加载效率问题),再回放日志。

日志
那么日志记录为
- key: A
- key: A xor B
- key: B xor C
最终回放日志的结果是
- A xor (A xor B) xor (B xor C) = C
由于异或运算是可交换的,差分日志可以以任意顺序并发回放,从而加速日志回放的性能。
当Hana使用列存储模型,使用以下技巧加速日志回放
- 日志内存内容中加入了受影响数据的列向量偏移位置,从而减少回放时的扫描
- 只有被实际修改的属性才会写入日志,而非记录整行数据
- 支持只记录最新值的日志策略(非默认策略),同一行的某个属性如果更新多次,只会在日志中存储一份
- 支持创建日志的字典快照,降低字典重建开销
书中认为从快照恢复内存数据的性能是没有问题的(没有提到任何优化技术),我对这一点保留疑问。如最高2T的高端内存服务器,其中512G用于内存数据,那么即使采用连续IO性能达到1GBps的SSD卡,也需要8分多钟的恢复时间。
另外,Hana支持多Master的副本模式,即写操作同步写入到多个活动副本后返回。
作者: 悄然回首 时间: 2016-5-6 21:13
不错!以后买了书本自己好好看看
作者: home_888 时间: 2016-7-11 14:36
哎呀,内容太复杂,挺高深啊!
作者: tmsundy 时间: 2016-8-11 10:54
支持一下楼主!支持一下楼主!
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |