
spaCy是Python和Cython中的高级自然语言处理库,它建立在最新的研究基础之上,从一开始就设计用于实际产品。spaCy带有预先训练的统计模型和单词向量,目前支持20多种语言的标记。它具有世界上速度最快的句法分析器,用于标签的卷积神经网络模型,解析和命名实体识别以及与深度学习整合。它是在MIT许可下发布的商业开源软件。
spaCy项目由@honnibal和@ines维护,虽然无法通过电子邮件提供个人支持。但开源者相信,如果公开分享,会让帮助更有价值,可以让更多人从中受益。(Github官方地址:https://github.com/explosion/spaCy#spacy-industrial-strength-nlp)
spaCy的特征:
世界上最快的句法分析器
实体命名识别
非破坏性标记
支持20多种语言
预先训练的统计模型和单词向量
易于深度学习模型的整合
一部分语音标记
标签依赖分析
语法驱动的句子分割
可视化构建语法和NER
字符串到哈希映射更便捷
导出numpy数据数组
有效的二进制序列化
易于模型打包和部署
最快的速度
强烈严格的评估准确性
安装spaCy
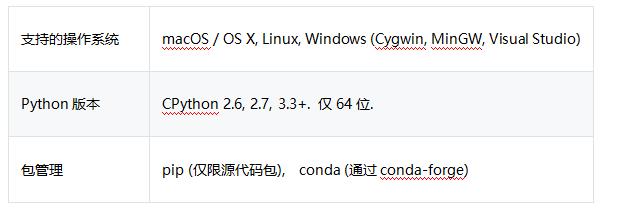
pip
使用pip,spaCy版本目前仅作为源包提供。
pip install spacy
在使用pip时,通常建议在虚拟环境中安装软件包以避免修改系统状态:
venv .envsource .env/bin/activate
pip install spacy
conda
通过社区开发者的努力,终于重新添加了conda支持。现在可以通过conda-forge安装spaCy:
conda config --add channels conda-forge
conda install spacy
更新spaCy
spaCy的一些更新可能需要下载新的统计模型,如果正在运行spaCy v2.0或更高版本,则可以使用validate命令来检查安装的模型是否兼容,如果不兼容,请打印有关如何更新的详细信息:
pip install -U spacy
spacy validate
如果已经训练了自己的模型,请记住,训练和运行时的输入必须匹配。在更新spaCy之后,建议用新版本重新训练模型。
下载模型
从v1.7.0开始,spaCy的模型可以作为Python包安装。这意味着它们是应用程序的组件,就像任何其他模块一样。 可以使用spaCy的下载命令来安装模型,也可以通过将pip指向路径或URL来手动安装模型。
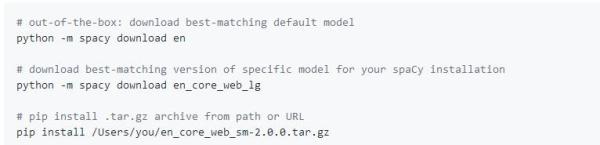
加载和使用模型
要加载模型,请在模型的快捷链接中使用spacy.load():

如果已经通过pip安装了一个模型,也可以直接导入它,然后调用它的load()方法:
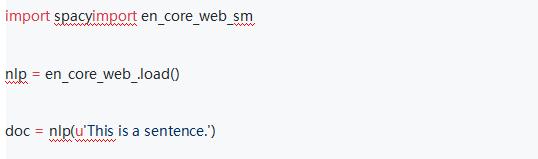
支持旧版本
如果使用的是旧版本(v1.6.0或更低版本),则仍然可以使用python -m spacy.en.download all或python -m spacy.de.download all从spaCy下载并安装旧模型。.tar.gz存档也附加到v1.6.0版本,要手动下载并安装模型,请解压存档,将包含的目录放入spacy / data,并通过spacy.load('en')或spacy.load('de')加载模型。
从源代码编译
另一种安装spaCy的方法是克隆它的GitHub仓库,并从源代码构建它。 如果要更改代码库,常见方法是需要确保你有一个由包含头文件,编译器,pip,virtualenv和git的Python发行版组成的开发环境。编译器部分是最棘手的。,如何做到这一点取决于你的系统。有关详细信息,请参阅Ubuntu,OS X和Windows上的说明。
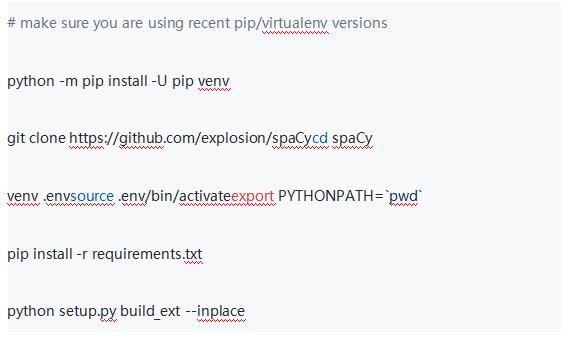
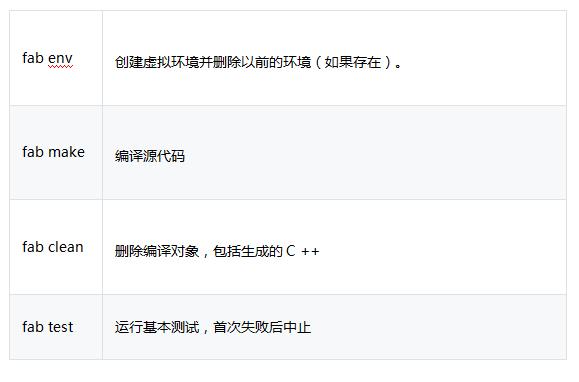
与通过pip进行常规安装相比,requirements.txt会额外安装Cython等开发人员依赖项。 有关更多详细信息和说明,请参阅有关从源代码编译spaCy和快速启动小部件的文档,以获取适用于您平台和Python版本的正确命令,而不是上面的详细命令,你也可以使用下面的结构命令,所有命令都假定虚拟环境位于一个目录.env中。如果使用的是其他目录,则可以通过环境变量VENV_DIR进行更改,例如VENV_DIR =“。custom-env”fab clean make。
Ubuntu
通过apt-get安装系统级依赖关系:
sudo apt-get install build-essential python-dev git
macOS / OS X
安装最新版本的XCode,包括所谓的“命令行工具”。 macOS和OS X预装了Python和git。
Windows
安装与用于编译Python解释器的版本相匹配的Visual Studio Express或更高版本。官方发行版是VS 2008(Python 2.7),VS 2010(Python 3.4)和VS 2015(Python 3.5)。
运行测试
spaCy带有一个广泛的测试套件。 首先,找出spaCy的安装位置:
python -c "import os; import spacy; print(os.path.dirname(spacy.__file__))"
然后在该目录下运行。The flags--vectors,--slow 和--model是可选的,并启用额外的测试:
#make sure you are using recent pytest version
python -m pip install -U pytest
python -m pytest <
| 欢迎光临 168大数据 (http://www.bi168.cn/) | Powered by Discuz! X3.2 |