168大数据
标题: 想从事数据行业?你必须掌握这个最核心的技能 [打印本页]
作者: 168主编 时间: 2019-1-24 12:49
标题: 想从事数据行业?你必须掌握这个最核心的技能
大家对数据科学家的预期是应该懂很多——机器学习、计算机科学、统计、数学、数据可视化、沟通,以及深度学习。这些领域牵涉到很多的语言、框架以及技术的学习。数据科学家要想成为雇主想要的那种人才的话,应该把学习的精力放在哪些地方呢?我到求职网站去寻找对数据科学家最迫切的技能需求是什么。我看了一般的数据科学技能,也分别看了对语言和工具的要求。2018年10月10日,我在LinkedIn、Indeed、SimplyHired、Monster以及AngelList上面搜索了求职列表。下面这张图列出了每个网站对数据科学家的需求数量。
我看了很多求职列表和调查以找出最常见的技能。像管理这类的术语就不进行比较了,因为可以用到的场合太多了。
所有的搜索都是针对美国,使用了“data scientist(数据科学家)”、“[keyword]”作为搜索关键字。采用精确匹配以减少搜索结果数。然而,这个方法确保了结果对数据科学家职位是相关的,并且对所有搜索术语都产生类似的作用。
AngelList提供的是列出数据科学家岗位的公司数而不是岗位数。我把AngelList从所有分析里面排除掉了,因为其搜索算法似乎按照OR型的逻辑搜索进行,没有办法改成AND。如果你寻找的是“数据科学家”“TensorFlow”的话,AngelList也没问题,因为这只能在数据科学家岗位里面找到,但如果你的关键字是“数据科学家”“react.js”的话,它返回的结果就太多了,其中会包括一大堆非数据科学家的岗位列表。
Glassdoor也被排除在我的分析之外。该网站声称在美国有26263个“数据科学家”职位,但是显示出来的却不超过900个。此外,它上面的数据科学家岗位数超过任何其他主流平台3倍以上似乎极不可能。
LinkedIn上超过400个岗位列表都提到的通用技能以及超过200个岗位列表都提到的特别技术被纳入到最终分析里面。当然,这两者之间会有一些交叉。结果已经被记录进这张Google Sheet 里面。
我下载了.csv文件并且导入到JupyterLab。然后我计算了出现比例并求出求职网站之间的平均数。
我还将软件结果跟GlassDoor的一项研究(2017年上半年,针对数据科学家岗位列表)进行了对比。再结合KDNuggets使用情况调查的信息,似乎一些技能正在变得越来月重要,而其他一些的相关性则在下降。后面我们会细谈。
互动式图表可以到我的Kaggle Kernel上面去看,额外分析可参见此处。可视化我用的是Plotly。为了本文结合使用Plotly和JupyterLab可费了一点功夫——相关指令可到我的Kaggle Kernel找,另外这里也有Plotly的脚本。
通用技能
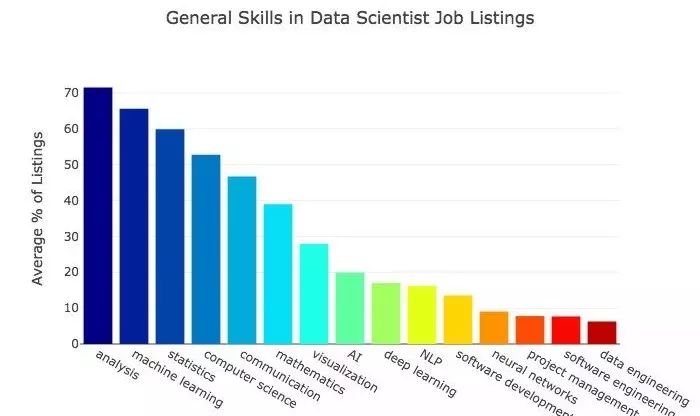
下面这张图反映的是雇主寻找最频繁的数据科学家通用技能。
结果表明,分析和机器学习是数据科学家岗位的核心技能。从数据中发现洞察是数据科学的主要职能。机器学习则是要创建系统来预测表现,这是非常亟需的技能。
数据科学需要统计和计算机科学技能——这一点并不出奇。统计分析、计算机科学以及数学也是大学的专业,这大概对其出现频率有帮助。
有趣的是沟通在将近一半的岗位列表中被提到。数据科学家需要将洞察与工作与他人进行沟通。
AI和深度学习的出现频率没有其他一些属于那么频繁。然而,它们都属于机器学习的子集。机器学习过去由其他算法执行的任务正在被越来越多的深度学习算法替代。比方说,大多数自然语言处理问题最好的机器学习算法现在都是深度学习算法。我预计深度学习技能在未来的需求会更加迫切,而机器学习也将日益变成深度学习的同义词。
此外,哪些数据科学家的软件工具是雇主想要寻求的呢?下面我们就来看看这个问题的答案。
技术技能
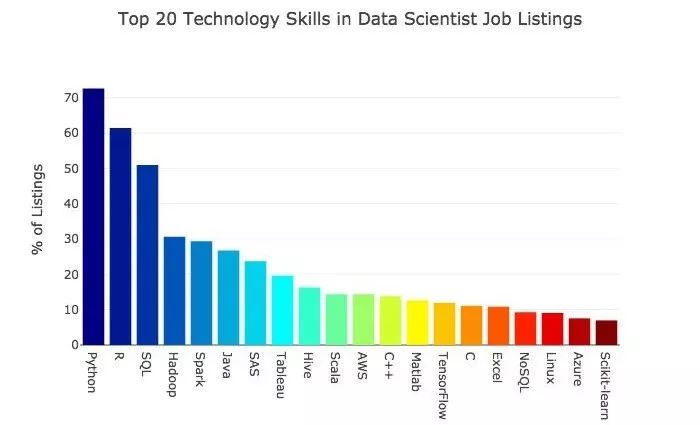
以下是雇主希望数据科学家掌握的排名靠前的20种语言、库以及技术工具。
我们大概看一下其中最常见的技术技能。
Python
Python是需求最旺盛的语言。这门开源语言的流行度已经被很多人注意到。它对初学者很友好,有许多支持资源。绝大部分新的数据科学工具都兼容它。
Python是数据科学家的主要语言。
R
R语言并不比Python落后多少。它一度是数据科学的主要语言。我反而对它的需求依然如此旺盛感到吃惊。这门开源语言的根在统计,至今在统计学家那里仍非常流行。
Python或者R几乎是每一个数据科学家岗位的必须。
SQL
SQL的需求也很高。SQL即结构化查询语言(Structured Query Language),是与关系式数据库的主要交互方式。SQL有时候会被数据科学界忽视,但这是一门值得掌握的技能,如果你打算切入求职市场的话。
Hadoop、Spark
接下来是Hadoop和Spark,这两个都是出自Apache的大数据开源工具。
Apache Hadoop是一个利用商品化硬件搭建的计算机集群对超大规模数据集进行分布式存储和分布式处理的开源软件平台。
Apache Spark是一个有着优雅的、富有表现力的API,可让数据工作者高效执行需要对数据集进行快速迭代存取的流处理、机器学习或者SQL负载的快速内存数据处理引擎。
相对于其他,这些工具在Medium和教程中被提及的次数少了点。我猜具备这些技能的求职者要比具备Python、R和SQL技能的求职者少得多。如果你掌握了一定Hadoop和Spark经验的话,应该可以在竞争中获得优势。
Java、SAS
然后是Java和SAS。这两门语言地位这么高倒是出乎我的意料。其背后都有大公司的支持,支持至少都提供了一些免费的产品。不过Java和SAS在数据科学社区受到的关注都很少。
Tableau
对Tableau的需求次之。这个分析平台和可视化工具非常强大,易用,而且越来越流行。它有一个免费的公共版本,但是如果你想数据保持私有的话得花钱。
如果你对Tableau不熟悉的话,到Udemy上一门Tableau 10 A-Z快速了解一下绝对是值得的。声明一下啊,我这么建议可不是拿了佣金的——那是因为我上过这门课之后发现它的确有用。
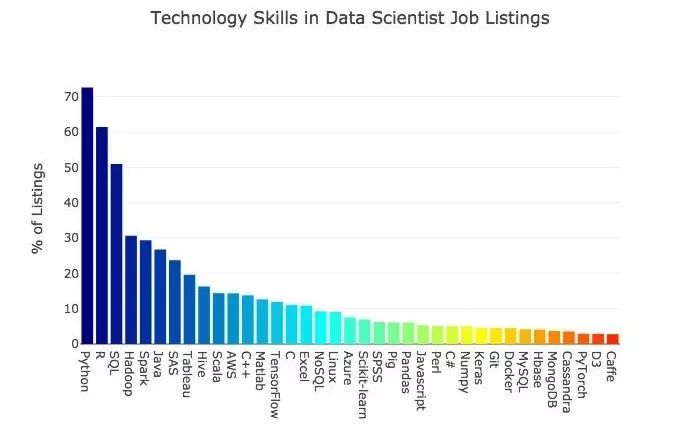
下面这张表反映的是更大范围内的语言、框架等数据科学软件工具的需求情况。
历史对比
GlassDoor对2017年1月到7月间数据科学家10大最常见的软件技能进行了分析。以下是那些术语出现的频度相对2018年10月在LinkedIn、Indeed、SimplyHired及Monster上出现频度平均数的对比。
结果相当类似。我的分析和GlassDoor的分析都发现Python、R及SQL都是需求最旺盛的技能。两份分析发现的需求前9大技术技能都是一样的,尽管顺序方面略有不同。
结果表明,相对于2017年上半年,R、Hadoop、Java、SAS及MatLab现在的需求略微下降,而对Tableau的需求则在上升。加上KDnuggets开发者调查这类的辅助性结果,我想这就是我预期的结论。R、Hadoop、Java和SAS均呈现出多年的下降趋势,而对Tableau则显示出明显的上升势头。
建议
基于这些分析的结果,以下是对当前和想要成为数据科学家的人提供的提升自我价值的建议。
- 证明你可以进行数据分析并且专注机器学习,要变得非常擅长。
- 对你的沟通技能进行投资。我建议去读读《Made to Stick(让创意更有粘性)》这本书来让你的想法产生更大影响。此外还可以用Hemmingway Editor这款app改进写作的清晰性。
- 掌握一种深度学习框架。精通一种深度学习框架在精通机器学习中占据了越来越大的部分。深度学习框架在使用情况、流行度等方面的对比情况可以看我的这篇文章。
- 如果你要走学习Python和R语言之间做选择的话,选Python。如果你对Python不感冒,那就选择R。如果你也懂R的话在市场上一定会更加抢手。
当雇主寻找懂Python技能的数据科学家时,他们可能也会预期应征者了解常见的python数据库库:numpy、pandas、scikit-learn以及matplotlib等。如果你想学习这里提到的工具的话,我建议你看看以下这些资源:
- DataCamp 及 DataQuest——均为定价合理的在线SaaS数据科学教育产品,可以一边编码一边学习。这两个都教若干的技术工具。
- Data School上面有各种资源,其中就包括了一套很好的YouTube视频,里面解释了数据科学的概念。
- McKinney的《Python for Data Analysis》。这本书是pandas库的主要作者写的,聚焦的是pandas,同时也讨论了python基础、numpy以及scikit-learn的数据科学功能。
- Müller & Guido的《Introduction to Machine Leaning with Python》。Müller是scikit-learn的主要维护者之一。这本书非常优秀,是学习用scikit-learn做机器学习的好读物。
- 如果你寻求去学习深度学习的话,我建议先从Keras 或者 FastAI 开始,然后再转到TensorFlow或者PyTorch。Chollet的《Deep Learning with Python》是学习Keras的好资源。
除了这些推荐以外,我还建议你学习自己感兴趣的东西,尽管在决定如何分配学习时间方面显然有很多考虑因素。
LinkedIn
如果你要通过在线门户找数据科学家岗位的话,我建议你从LinkedIn开始——这个地方总是有最多的结果。
如果你在求职网站上寻找工作或者职位的话,关键字很重要。每个网站搜“数据科学”返回的结果数几乎是“数据科学家”的3倍。但如果你要找的就是数据科学家的工作的话,最好还是搜索“数据科学家”。
无论你去哪里找,我建议你要制作一份在线作品集来证明你擅长许多亟需的技能。我也建议你在LinkedIn档案上展示你的技能。
原文来自:towardsdatascience.com 编译自:36Kr
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |