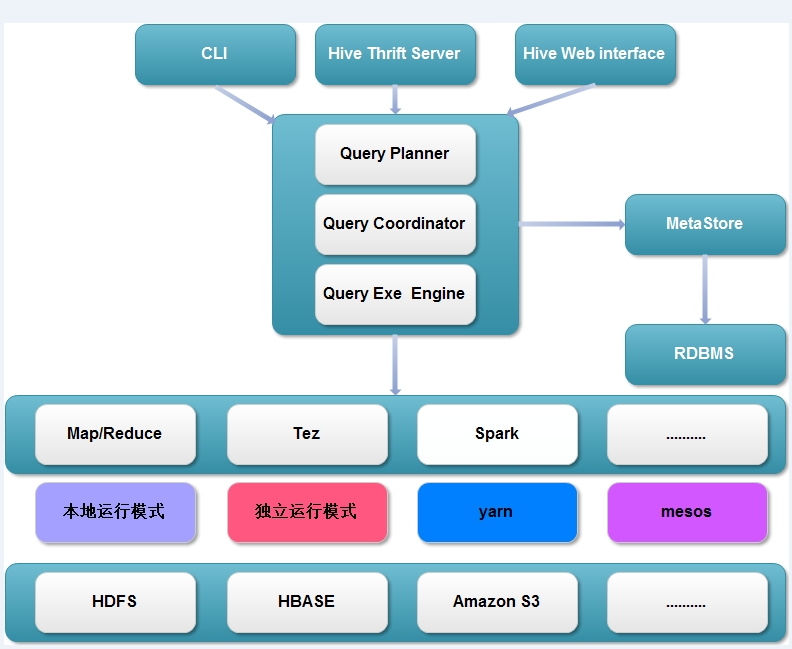
1 2 3 | mapreduce.output.fileoutputformat.compress=true mapreduce.output.fileoutputformat.compress.type=BLOCK mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec |
1 2 | mapreduce.map.output.compress=true mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec |
1 2 | hive.exec.compress.output=true hive.exec.compress.intermediate=true |


| 欢迎光临 168大数据 (http://www.bi168.cn/) | Powered by Discuz! X3.2 |