168大数据
标题: 数据中台建设杂谈 [打印本页]
作者: 168主编 时间: 2019-7-3 11:51
标题: 数据中台建设杂谈
现状
公司属于是互联网金融行业,但因为只是中小型企业,技术积累较少,数据部门也是16年未开始组建的。最初只是一个提数小组,为业务部门提供他们需要的数据,直到上层领导有意走数据驱动业务的方式,才创建了数据部,也可能只是为了赶时髦,毕境17年,各种GB、TB已经满天飞。
于是领导就带领着大家搞起了大数据,创建了最初的仓库平台、搭建了报表平台、可视化平台,对业务提供支撑。几乎没有相关技术储备,可以说从0到1,轰轰烈烈,加班加点搞了几个月,初见成效。在做大数据平台的同时,也引入了一些数据应用产品,比如多维分析的saiku,BI工具SuperSet,用于提供报表和提数需求;并且也开发了自己的数据管理平台、统一调度中心,可以小有成就。
18年年初(3月初左右)公司上层决策创建金融事业中心并单独运营,部门负责人被抽离到金融,并带走部分核心人员,再加上离职人员,技术所剩无几,导致后续大数据平台停步不前,没有什么新的产品开发,日常工作即停留在对原有系统的使用上,应对越来越多的提数需求和个性化的业务定制需求,响应乏力。同事们也有心改造,但无奈人员缺乏,技术储备不足等原因,未能见成效。
当然,近1年多的时间同事们也没有闲着,在完成工作的时事,尝试了一些大数据应用的技术和方案,算是做了些相关技能的存储。
设想2018Q4研发中心架构调整,欲建立去中心化的开发平台,即各业务部门各自管理自己的应用和数据,同时同步到数据中台。各业务部门对其它部门的数据需求,统一走数据中台。所以数据部又一次走到了风口,面临压力,着手改造。
现有的数据仓库架构
如下图所示,按照业内标准的数据架构,数据采集层、数据计算层、数据服务层、数据应用层进行描述。
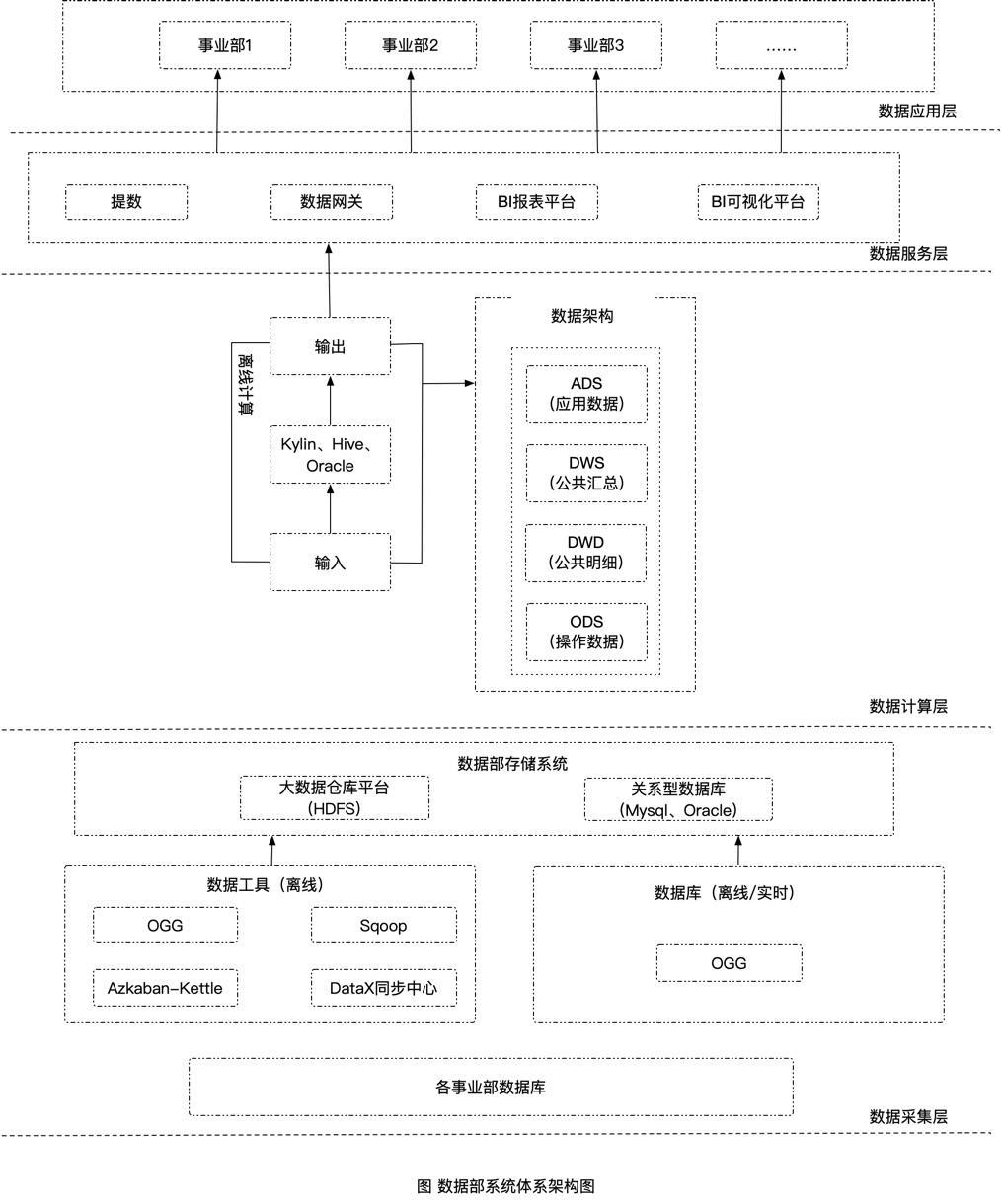
首先是从各业务部门数据库,通过OGG、Sqoop、DataX、Kettle等工具同步定时同步数据到数据中心存储系统上,包括大数据平台HDFS、关系型数据库。然后提供几种查询平台,如kylin、hive、oracle等,进行数据获取,如通过Kylin建模的方式,离线预处理T-1的离线数据;通过oracle数据库,提数人员写SQL查询等,得到想要的数据,目前只支持离线数据。数据同步完成对,外的的数据服务,目前提供了手工提数工单、数据网关接口、帆软BI报表、帆软可视化等方式对业务部门提供查询。
标准数据中台构架如下图所示
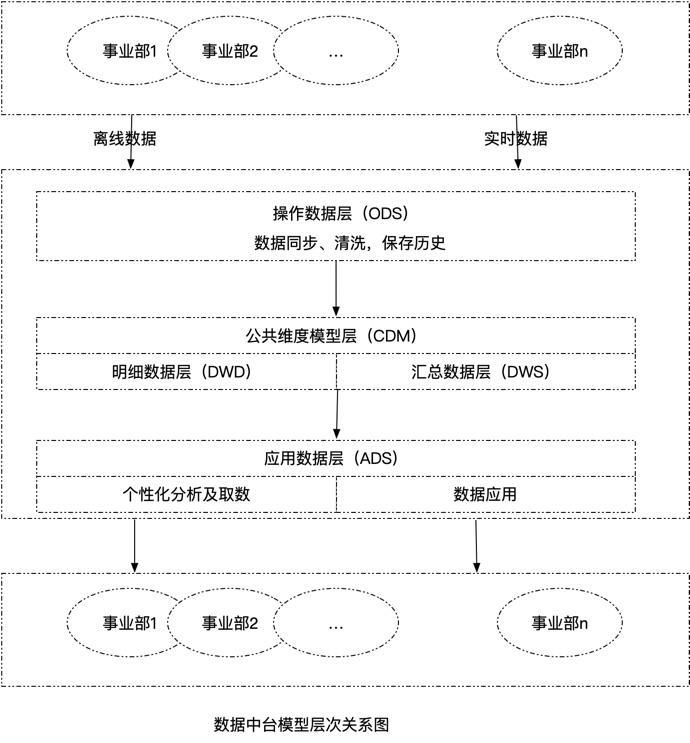
通用的数据中台架构,即从数据同步->模型抽象->对外应用进行划分,其中操作层作了些同步、清洗、日志采集等收集数据的事情;公共维度对业务数据进行建模,划分度量、维度等对数据进行建模,当然也可以采用其它建模方式;应用数据层是对创建好的数据对外提供服务的方式,包含传输数据的渠道、展示数据的方式等。
从我们现有的架构的数据仓库架构来看,最初也是按照这个架构进行设计的。但从具体的实现去分析实则存在很多的问题,及需要改进的地方。下面对现有架构的问题进行一下分析。
存在的问题
当前系统架构,对于技术的应用边界、所选技术的性能等问题没有明确的说明。大致列举如下:
- 数据同步就有OGG、DataX、Sqoop、Kettle,到你在什么情况下使用OGG比较好,在什么情况下应该使用DataX等问题没有明确界线;另外是否需要这么多同步技术支撑,还是说选择1个主流技术和一个补偿机制即可。
现在的大数据平台,只是搭建完成,功能只使用了基础的hdfs/hive,对于其它的技术没用实践;
4.计算引擎单一,目前只有hive方式查询,对于近实时的要求高的应用就不能满足了。应该提供批和流同步支持的查询,针对不同的情况,选择不同的查询引擎。
5.同步与查询模块,能否经受得住后期全业务部门的数据查询需求和高并发、大数据量的考验。需要做哪些改进。
我们能改进的点
应该针对不同的查询需求,提供不同的数据服务出口。比如规范性强的直接走数据网关;定制化要求高的可以走报表;个性化的数据可以走提数工单,定义好边界。
提供批和流两种查询支持。计算是仓库的大脑,如果速度慢,完全影响体验及数据的反馈。
数据建模。应该统一数据建模,建议规范定义和整理,用于数据提取或自助提数。也可减少与业务人员的理解分歧。
理想的仓库如图所示。
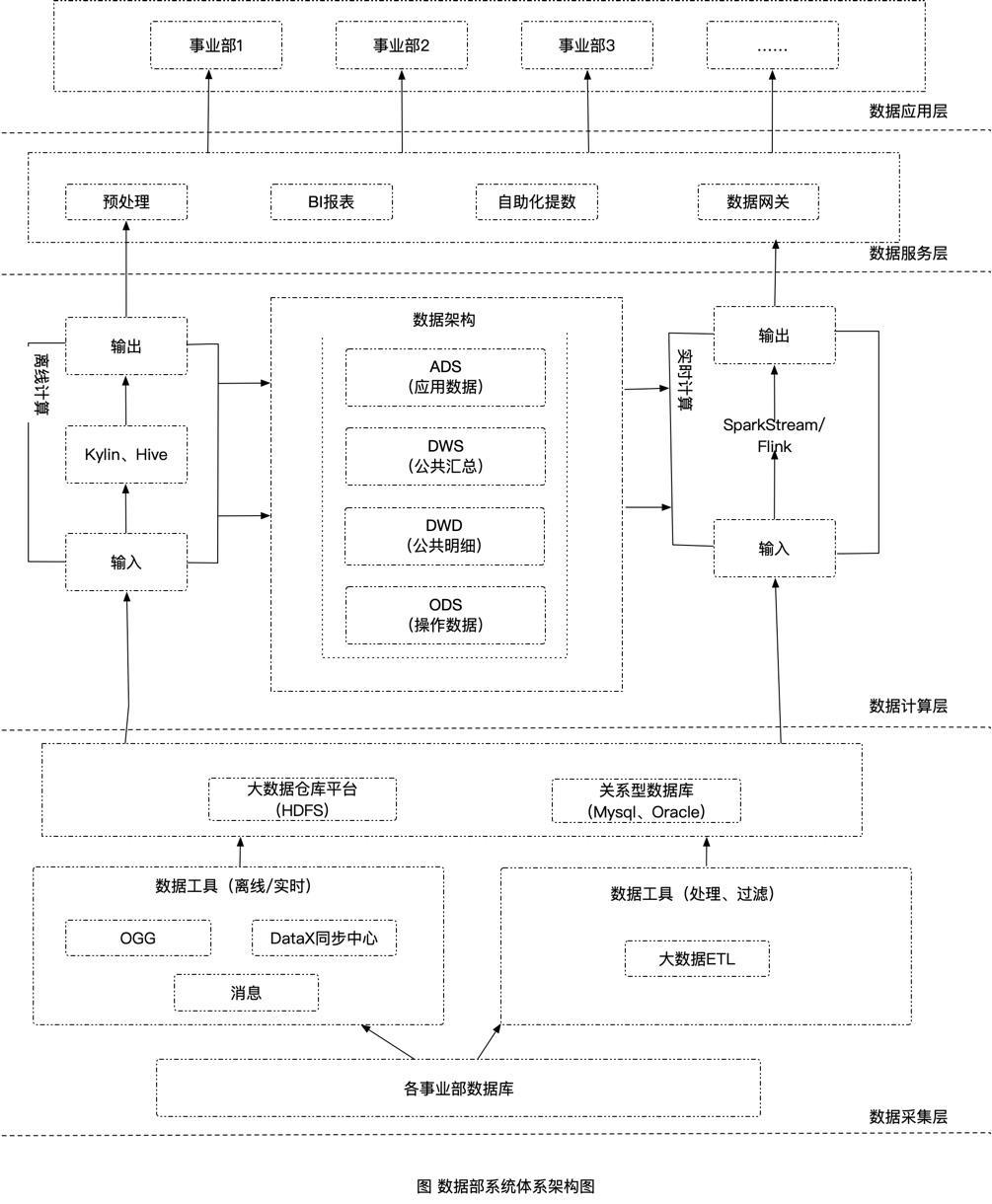
提供批流两种计算方式、对外针对不同的需求,提供不同的对外数据输出。优化建模,改进同步,增加消息同步补偿。
最后
个人见解,很多不足,后期再变更吧。另外理想很丰满,现实很骨感,4季度结束再回头看吧。
参考
阿里巴巴《大数据之路》
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |