168大数据
标题:
Zookeeper功能与基本原理
[打印本页]
作者:
168主编
时间:
2019-10-16 20:16
标题:
Zookeeper功能与基本原理
虽然工作之中的项目有用到Zookeeper,但是没有参与过项目搭建,只是单纯的进行业务相关的开发,没有机会也没有需要让我去接触公司用到的Zookeeper,所以一直就没想着去学习下Zookeeper。为了更好的了解我平常使用的架构,所以开始学习Zookeeper相关的知识。
什么是Zookeeper?
Zookeeper是一种分布式协调服务,用来解决分布式下的一致性问题。
Zookeeper有哪些特性和功能?
数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、Watcher(事件监听器)、事件监听、配置维护,名字服务、分布式同步、分布式锁和分布式队列 等。
Zookeeper基本原理
集群角色
Leader:集群的核心,提供读和写的权限,一个Zookeeper集群同时仅有一个Leader
Follower:Leader的追随者,给外界提供读的服务,在Leader崩溃的时候可以通过Master选举成为Leader
Observer:集群的观察者,与Follower功能相似,也是向外面提供读的服务,但是Observer不会参加Master选举成为Leader,它的存在只是为了扩展系统,提高读的性能。
集群管理与Master选举
集群管理主要是服务器的新增和移除以及Master选举。
通过Zookeeper文件系统的临时节点我们很容易来实现服务器的新增与移除,当服务器在Zookeeper上注册的时候,Zookeeper会为它新增一个临时节点,而服务器与Zookeeper失去连接的时候,Zookeeper会删除该服务器对应的临时节点,并且通知集群内的其它服务器,有一个服务器被移除了。
Leader在集群中只会存在一个,如果Leader宕机了,那么之前在Leader节点注册过Watcher的Follower就会发起Master选举,根据一定的策略选举出Leader。
数据模型
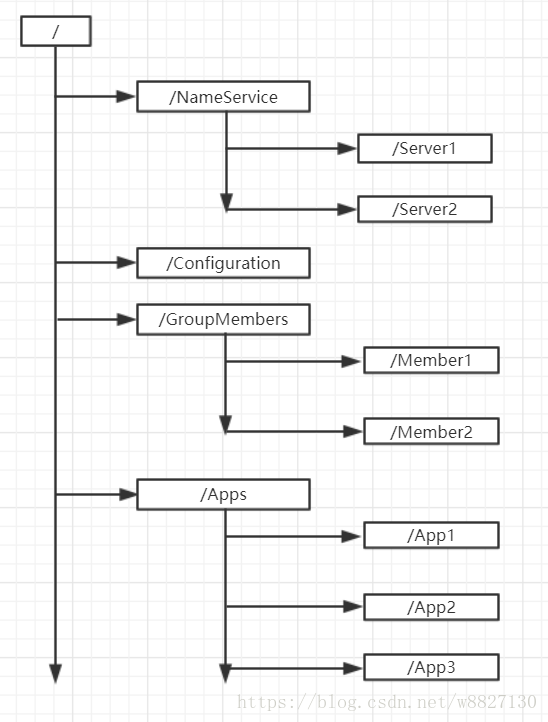
Zookeeper有数据模型和文件系统类似,每一个子目录如NameService都被称为znode(数据节点),znode可以被新增和删除,每个znode上除了保存自己的数据内容,还保存一系列属性信息。
数据模型示意图
有以下4种类型的znode:
1:PERSISTENT-持久化目录节点
创建了之后就会一直存在的目录节点,不会因为Zookeeper宕机或者客户端和Zookeeper断开连接而消失,除非主动删除该节点。
2:PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
不会因为Zookeeper宕机或者客户端和Zookeeper断开连接而消失,Zookeeper给节点进行顺序编号。
3:EPHEMERAL-临时目录节点
会因为Zookeeper宕机或者客户端和Zookeeper断开连接而消失的目录节点。
4:EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
Zookeeper宕机或者客户端和Zookeeper断开连接而消失的目录节点,Zookeeper给节点进行顺序编号。
版本
ZooKeeper为每一个ZNode节点维护一个叫做Stat的数据结构,在Stat中维护了节点相关的三个版本:
当前znode的版本 version
当前znode子节点的版本 cversion
当前znode的ACL(Access Control Lists)版本 aversion
数据发布/订阅与配置维护
发布者将配置信息发布到Zookeeper节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和动态更新。
Zookeeper采用推拉结合的方式来对数据进行管理,客户端向数据节点注册Watcher监听器,当数据节点上的数据发生改变时,服务端会向对此感兴趣的客户端发送Watcher事件通知,客户端接收到通知后会去Zookeeper的数据节点取数据。
这样的配置信息管理机制让本来分散在各个不同服务器上的配置信息集中在一起,提高了配置信息的可维护性。
分布式协调/通知
Zookeeper的分布式协调/通知功能是基于Watcher而实现的,Zookeeper允许客户端在一些节点上注册Watcher,当这些节点发送了变化,就会发送Wather通知给客户端。
命名服务
Zookeeper本身有一个文件系统,在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务,远程对象等等——这些我们都可以统称他们为名字。 其中较为常见的就是一些分布式服务框架(如RPC)中的服务地址列表。通过在ZooKeepr里创建顺序节点,能够很容易创建一个全局唯一的路径,这个路径就可以作为一个名字。 ZooKeeper的命名服务即生成全局唯一的ID。
负载均衡
当Zookeeper与RPC服务框架一起使用的时候,Zookeeper会作为服务注册中心,RPC服务框架可以在Zookpeer上注册服务与订阅服务,当消费者要使用服务,而服务提供方有多个的时候,Zookeeper可以根据一定的负载均衡策略选择服务提供方来提供服务。
分布式锁
就java来说,在单台服务器上可以用单纯的java代码来实现锁机制,但是如果在分布式下,单纯的使用java代码已经无法实现锁机制了,因为每一台服务器都有自己的JVM,这时候需要依靠中间件来实现分布式锁。
Zookeeper一致性文件系统的临时节点可以作为分布式锁,各个客户端可以在注册Watcher来监听该临时节点,它们可以在Zookeeper中尝试去创建临时节点,Zookeeper的同一个目录下只能有一个唯一的文件名机制会保证只有一个客户端可以成功创建临时节点,成功创建节点代表了这个客户端已经获取到了锁。在客户端处理完业务之后只需要将之前创建的临时节点删除,就释放了锁。与此同时,之前注册过Watcher监听临时节点的客户端会接收到通知,继续尝试创建临时节点。
临时节点的特性也会保证分布式锁的正常工作,临时节点会在客户端与Zookeeper失去连接的时候主动删除临时节点,不会造成锁一直存在的情况。
本文仅仅简单介绍了Zookeeper的一些基本原理和功能,意在让大家了解一下Zookeeper,可以在出现问题的时候使用Zookeeper来解决相应的问题,但本人实际工作中并没有太多的机会去接触Zookeeper。
————————————————
版权声明:本文为CSDN博主「呆某人」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/w8827130/article/details/81834905
欢迎光临 168大数据 (http://www.bi168.cn/)
Powered by Discuz! X3.2