168大数据
标题: Spark性能优化总结 [打印本页]
作者: 168主编 时间: 2020-4-1 12:35
标题: Spark性能优化总结
本帖最后由 168主编 于 2020-4-4 19:17 编辑
1. 避免重复加载RDD 比如一份从HDFS中加载的数据 val rdd1 = sc.textFile("hdfs://url:port/test.txt"),这个test.txt只应该在你的程序中被加载一次,避免多次加载造成的性能开销。
2. 重复使用的RDD需要被缓存 Spark有数据持久化的几种策略,可以将RDD中的数据保存到内存或者磁盘中,后续对这个RDD的操作不会根据RDD lineage重新计算,而是直接从缓存中提取。
如果要对一个RDD进行持久化,只需要对这个RDD调用cache()和persist(),cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中,
但是生产环境中处理的数据量往往很难全部存储在内存中,需注意虚拟机OOM;persist()方法表示需要手动选择StorageLevel(持久化级别),并使用指定的方式
进行持久化,如序列化到磁盘等(注意,有时候数据全部序列化到磁盘比重新计算一次更慢!)
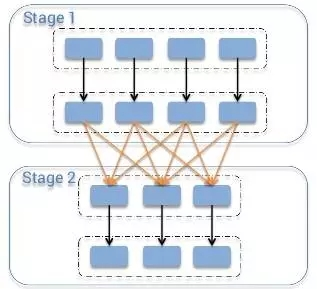
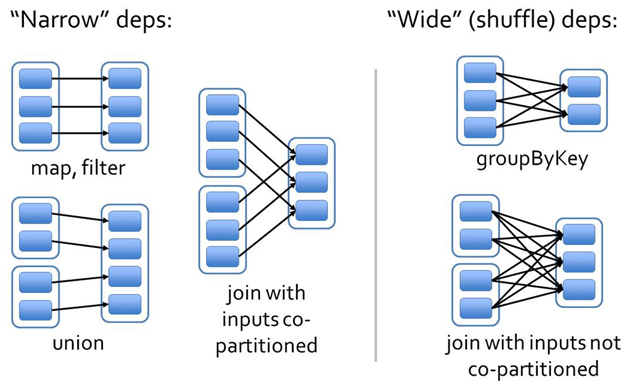
3. 警惕shuffle操作性能问题 类似MapReduce中的shuffle过程(MapReduce浅析),同一个父RDD的分区传入到不同的子RDD分区中,shuffle过程往往会造成跨节点数据传输(即官网所说的宽依赖问题):
各个节点上的相同key首先写入本地磁盘文件中,然后其他节点需要通过网络根据路由函数传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合
操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,溢写到磁盘文件中。。
图1.Spark的shuffle过程
图2. 宽依赖和窄依赖
解决方式有以下两种:
1. 如果可以,先使用filter对RDD先做一定程度的 ‘缩小’
2. 在Map端预先对数据进行聚合,类似传统MapReduce中的Combiner,在Spark中使用reduceByKey或者aggregateByKey会对数据在Map端聚合,
反之,groupByKey会导致全部数据在集群中跨节点传输,性能较差。
4. 广播变量 类似于MapReduce中的DistributeCache。默认情况下Spark会将程序中依赖的变量复制多个副本,分发到各个task中,每个task都有一个副本。如果
变量本身比较大的话,那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。
而Spark中的广播变量作用是一个Executor中的所有task共享一个副本。
5. 序列化 Spark可以使用Kryo优化序列化过程。
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |