168大数据
标题: 数据质量监控工具——Griffin [打印本页]
作者: 168主编 时间: 2020-11-30 15:31
标题: 数据质量监控工具——Griffin
文章内容输出来源:拉勾教育大数据高薪训练营
第1节 为什么要做数据质量监控1、数据不一致
企业早期没有进行统一规划设计,大部分信息系统是逐步迭代建设的,系统建设时间长短各异,各系统数据标准也不同。企业业务系统更关注业务层面,各个业务系统均有不同的侧重点,各类数据的属性信息设置和要求不统一。另外,由于各系统的相互独立使用,无法及时同步更新相关信息等各种原因造成各系统间的数据不一致,严重影响了各系统间的数据交互和统一识别,基础数据难以共享利用,数据的深层价值也难以体现。
2、数据不完整
由于企业信息系统的孤立使用,各个业务系统或模块按照各自的需要录入数据,没有统一的录入工具和数据出口,业务系统不需要的信息就不录,造成同样的数据在不同的系统有不同的属性信息,数据完整性无法得到保障。
3、数据不合规
没有统一的数据管理平台和数据源头,数据全生命周期管理不完整,同时企业各信息系统的数据录入环节过于简单且手工参与较多,就数据本身而言,缺少是否重复、合法、对错等校验环节,导致各个信息系统的数据不够准确,格式混乱,各类数据难以集成和统一,没有质量控制导致海量数据因质量过低而难以被利用,且没有相应的数据管理流程。
4、数据不可控
海量数据多头管理,缺少专门对数据管理进行监督和控制的组织。企业各单位和部门关注数据的角度不一样,缺少一个组织从全局的视角对数据进行管理,导致无法建立统一的数据管理标准、流程等,相应的数据管理制度、办法等无法得到落实。同时,企业基础数据质量考核体系也尚未建立,无法保障一系列数据标准、规范、制度、流程得到长效执行。
5、数据冗余
各个信息系统针对数据的标准规范不一、编码规则不一、校验标准不一,且部分业务系统针对数据的验证标准严重缺失,造成了企业顶层视角的数据出现“一物多码”、“一码多物”等现象。
第2节 数据质量监控方法1、设计思路
数据质量监控的设计要分为4个模块:数据,规则,告警和反馈
①数据:需要被监控的数据,可能存放在不同的存储引擎中
②规则:值如何设计发现异常的规则,一般而言主要是数值的异常和环比等异常监控方式。也会有一些通过算法来发掘异常数据的方法
③告警:告警是指发告警的动作,这里可以通过微信消息,电话或者短信,邮件
④反馈:反馈是指对告警内容的反馈,比如说收到的告警内容,要有人员回应该告警消息是否是真的异常,是否需要忽略该异常,是否已经处理了该异常。有了反馈机制,整个数据监控才能形成闭环
2、技术方案
- 最开始可以先关注核心要监控的内容,比如说准确性,那么就对核心的一些指标做监控即可
- 监控平台尽量不要做太复杂的规则逻辑,尽量只对结果数据进行监控。比如要监控日质量是否波动过大,那么把该计算流程提前,先计算好结果表,最后监控平台只监控结果表是否异常即可
- 多数据源。多数据源的监控有两种方式:针对每个数据源定制实现一部分计算逻辑,也可以通过额外的任务将多数据源中的数据结果通过任务写入一个数据源中,再对该数据源进行监控
- 实时数据监控:区别在于扫描周期的不同,因此在设计的时候可以先以离线为主,但是尽量预留好实时监控的设计
第3节 Griffin架构Apache Griffin是一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度(如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表 的数据空值数量等)度量数据资产,从而提升数据的准确度、可信度。
Griffin主要分为Define、Measure和Analyze三个部分,如下图所示:
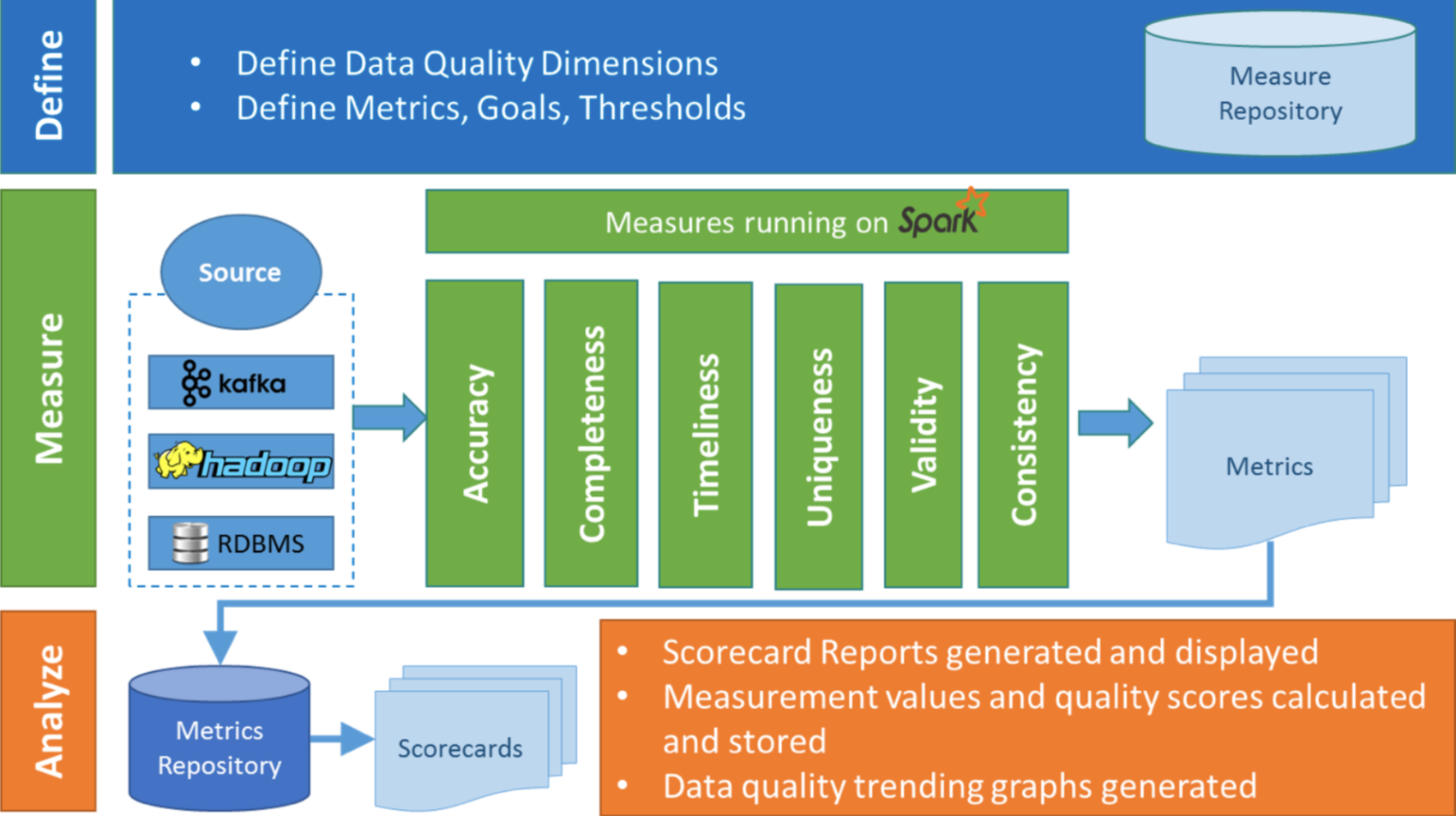
各部分的职责如下:
- Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标 (源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数 量、最大值、最小值、top5的值数量等)
- Measure:主要负责执行统计任务,生成统计结果
- Analyze:主要负责保存与展示统计结果
第4节 编译安装4.1 相关依赖重点讲解 Griffin,不对依赖组件做过多讲解,所有组件均采用单机模式安装。
- JDK (1.8 or later versions)
- MySQL(version 5.6及以上)
- Hadoop (2.6.0 or later)
- Hive (version 2.x)
- Maven
- Spark (version 2.2.1)
- Livy(livy-0.5.0-incubating)
- ElasticSearch (5.0 or later versions)
备注:
- Spark:计算批量、实时指标
- Livy:为服务提供 RESTful API 调用 Apache Spark
- ElasticSearch:存储指标数据
- MySQL:服务元数据
4.2 Spark安装1、解压缩,设置环境变量 $SPARK_HOME
tar zxvf spark-2.2.1-bin-hadoop2.7.tgz
mv spark-2.2.1-bin-hadoop2.7/ /opt/lagou/servers/spark-2.2.1/
# 设置环境变量
vi /etc/profile
export SPARK_HOME=/opt/lagou/servers/spark-2.2.1/
export PATH=$PATH SPARK_HOME/bin
SPARK_HOME/bin
source /etc/profile
2、 修改配置文件 $SPARK_HOME/conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux121:9000/spark/logs
spark.serializer
org.apache.spark.serializer.KryoSerializer
spark.yarn.jars
hdfs://linux121:9000/spark/spark_2.2.1_jars/*
备注:上面的路径要创建
拷贝 MySQL 驱动
cp $HIVE_HOME/lib/mysql-connector-java-5.1.46.jar $SPARK_HOME/jars/将 Spark 的 jar 包上传到 hdfs://hadoop1:9000/spark/spark_2.2.1_jars/
hdfs dfs -mkdir -p /spark/logs
hdfs dfs -mkdir -p /spark/spark_2.2.1_jars/
hdfs dfs -put /opt/lagou/servers/spark-2.2.1/jars/*.jar
/spark/spark_2.2.1_jars/
3 、 修改配置文件spark-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231/
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2/
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
4、yarn-site.xml 添加配置
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
yarn.nodemanager.vmem-check-enabled:是否检查虚拟内存。
修改所有节点,并重启yarn服务。
不添加该配配置启动spark-shell,有如下错误:Yarn application has already ended! It might have been killed or unable to launch application master.
5、测试spark
spark-shell
// /wcinput/wc.txt : HDFS上的文件
val lines = sc.textFile("/wcinput/wc.txt")
lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
4.3 Livy安装1、解压缩,设置环境变量 $LIVY_HOME
unzip livy-0.5.0-incubating-bin.zip
mv livy-0.5.0-incubating-bin/ ../servers/livy-0.5.0
# 设置环境变量
vi /etc/profile
export LIVY_HOME=/opt/lagou/servers/livy-0.5.0
export PATH=$PATHLIVY_HOME/bin
source /etc/profile
2、修改配置文件 conf/livy.conf
livy.server.host = 127.0.0.1
livy.spark.master = yarn
livy.spark.deployMode = cluster
livy.repl.enable-hive-context = true
3、修改配置文件 conf/livy-env.sh
export SPARK_HOME=/opt/lagou/servers/spark-2.2.1
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2/
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
4、启动服务
cd /opt/lagou/servers/livy-0.5.0
mkdir logs
nohup bin/livy-server &
4.4 ES安装1、解压缩
tar zxvf elasticsearch-5.6.0.tar.gz
mv elasticsearch-5.6.0/ ../software/
2、创建 elasticsearch用户组 及 elasticsearch 用户。不能使用root用户启动ES程序,需要创建 单独的用户去启动ES 服务;
# 创建用户组
groupadd elasticsearch
# 创建用户
useradd elasticsearch -g elasticsearch
# 修改安装目录的宿主
chown -R elasticsearch:elasticsearch elasticsearch-5.6.0/
3、修改linux系统文件 /etc/security/limits.conf
elasticsearch hard nofile 1000000
elasticsearch soft nofile 1000000
* soft nproc 4096
* hard nproc 4096
4、修改系统文件 /etc/sysctl.conf
# 文件末尾增加:
vm.max_map_count=262144
# 执行以下命令,修改才能生效
sysctl -p
5、修改es配置文件 /opt/lagou/servers/elasticsearch-5.6.0/config/elasticsearch.yml
network.host: 0.0.0.0/opt/lagou/servers/elasticsearch-5.6.0/config/jvm.options
jvm内存的分配,原来都是2g,修改为1g
6、启动ES服务
# 到ES安装目录下,执行命令(-d表示后台启动)
su elasticsearch
cd /opt/lagou/servers/elasticsearch-5.6.0/
bin/elasticsearch -d
在浏览器中检查:http://linux122:9200/

7、在ES里创建griffin索引
#linux122为ES服务所在节点
curl - XPUThttp: //linux122:9200/griffin-d'
{
"aliases": {},
"mappings": {
"accuracy": {
"properties": {
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"tmst": {
"type": "date"
}
}
}
},
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
}
}
'
4.5 Griffin编译准备1、软件解压缩
cd /opt/lagou/software
unzip griffin-griffin-0.5.0.zip
mv griffin-griffin-0.5.0/ ../servers/griffin-0.5.0/
cd griffin-0.5.0
2、在MySQL中创建数据库quartz,并初始化
/opt/lagou/servers/griffin-0.5.0/service/src/main/resources/Init_quartz_mysql_innodb.sql
备注:要做简单的修改,主要是增加 use quartz;
# mysql中执行创建数据库
create database quartz;
# 命令行执行,创建表
mysql -uhive -p12345678 < Init_quartz_mysql_innodb.sql
3、Hadoop和Hive
在HDFS上创建/spark/spark_conf目录,并将Hive的配置文件hive-site.xml上传到该目录下
hdfs dfs -mkdir -p /spark/spark_conf
hdfs dfs -put $HIVE_HOME/conf/hive-site.xml /spark/spark_conf/
备注:将安装 griffin 所在节点上的 hive-site.xml 文件,上传到 HDFS 对应目录中;
4、确保设置以下环境变量(/etc/profile)
export JAVA_HOME=/opt/lagou/servers/hadoop-2.9.2
export SPARK_HOME=/opt/lagou/servers/spark-2.2.1/
export LIVY_HOME=/opt/lagou/servers/livy-0.5.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
4.6 Griffin编译1、service/pom.xml文件配置
编辑 service/pom.xml(约113-117行),增加MySQL JDBC 依赖(即删除注释):
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.java.version}</version>
</dependency>
2、修改配置文件 service/src/main/resources/application.Properties
server.port = 9876
spring.application.name=griffin_service
spring.datasource.url=jdbc:mysql://linux123:3306/quartz?
autoReconnect=true&useSSL=false
spring.datasource.username=hive
spring.datasource.password=12345678
spring.jpa.generate-ddl=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=true
# Hive metastore
hive.metastore.uris=thrift://linux123:9083
hive.metastore.dbname=hivemetadata
hive.hmshandler.retry.attempts=15
hive.hmshandler.retry.interval=2000ms
# Hive cache time
cache.evict.hive.fixedRate.in.milliseconds=900000
# Kafka schema registry
kafka.schema.registry.url=http://localhost:8081
# Update job instance state at regular intervals
jobInstance.fixedDelay.in.milliseconds=60000
# Expired time of job instance which is 7 days that is 604800000
milliseconds.Time unit only supports milliseconds
jobInstance.expired.milliseconds=604800000
# schedule predicate job every 5 minutes and repeat 12 times at most
#interval time unit s:second m:minute h:hour d:day,only support these four units
predicate.job.interval=5m
predicate.job.repeat.count=12
# external properties directory location
external.config.location=
# external BATCH or STREAMING env
external.env.location=
# login strategy ("default" or "ldap")
login.strategy=default
# ldap
ldap.url=ldap://hostname:port
ldap.email=@example.com
ldap.searchBase=DC=org,DC=example
ldap.searchPattern=(sAMAccountName={0})
# hdfs default name
fs.defaultFS=
# elasticsearch
elasticsearch.host=linux122
elasticsearch.port=9200
elasticsearch.scheme=http
# elasticsearch.user = user
# elasticsearch.password = password
# livy
livy.uri=http://localhost:8998/batches
livy.need.queue=false
livy.task.max.concurrent.count=20
livy.task.submit.interval.second=3
livy.task.appId.retry.count=3
# yarn url
yarn.uri=http://linux123:8088
# griffin event listener
internal.event.listeners=GriffinJobEventHook
备注:
- 默认端口是8080,为避免和spark端口冲突,这里端口修改为9876
- 需要启动Hive的 metastore 服务
- 如果Griffin、MySQL没有安装在同一节点,请确认用户有权限能够远程登录
3、修改配置文件 service/src/main/resources/quartz.Properties
# 将第26行修改为以下内容:
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJD BCDelegate
4、修改配置文件 service/src/main/resources/sparkProperties.json
sparkProperties.json 在测试环境下使用:
{
"file": "hdfs:///griffin/griffin-measure.jar",
"className": "org.apache.griffin.measure.Application",
"name": "griffin",
"queue": "default",
"numExecutors": 2,
"executorCores": 1,
"driverMemory": "1g",
"executorMemory": "1g",
"conf": {
"spark.yarn.dist.files": "hdfs:///spark/spark_conf/hive-site.xml"
},
"files": []
}
备注:修改第11行:"spark.yarn.dist.files": "hdfs:///spark/spark_conf/hive-site.xml"
sparkProperties.json 在生产环境中根据实际资源配置进行修改【生产环境】
{
"file": "hdfs:///griffin/griffin-measure.jar",
"className": "org.apache.griffin.measure.Application",
"name": "griffin",
"queue": "default",
"numExecutors": 8,
"executorCores": 2,
"driverMemory": "4g",
"executorMemory": "5g",
"conf": {
"spark.yarn.dist.files": "hdfs:///spark/spark_conf/hive-site.xml"
},
"files": []
}
5、修改配置文件 service/src/main/resources/env/env_batch.json
{
"spark": {
"log.level": "WARN"
},
"sinks": [{
"type": "CONSOLE",
"config": {
"max.log.lines": 10
}
}, {
"type": "HDFS",
"config": {
"path": "hdfs:///griffin/persist",
"max.persist.lines": 10000,
"max.lines.per.file": 10000
}
}, {
"type": "ELASTICSEARCH",
"config": {
"method": "post",
"api": "http://liunx122:9200/griffin/accuracy",
"connection.timeout": "1m",
"retry": 10
}
}],
"griffin.checkpoint": []
}
备注:仅修改第24行
6、编译
cd /opt/lagou/software/griffin-0.5.0
mvn -Dmaven.test.skip=true clean install
备注:
- 编译过程中需要下载500M+左右的jar,要将Maven的源设置到阿里
- 如果修改了前面的配置文件,需要重新编译
7、修改文件
编译报错:
[ERROR] ERROR in /opt/lagou/servers/griffin- 0.5.0/ui/angular/node_modules/@types/jquery/JQuery.d.ts (4137,26): Cannot find name 'SVGElementTagNameMap'.
[ERROR] ERROR in /opt/lagou/servers/griffin- 0.5.0/ui/angular/node_modules/@types/jquery/JQuery.d.ts (4137,89): Cannot find name 'SVGElementTagNameMap'.
这个文件在编译之前是没有的
/opt/lagou/servers/griffin-0.5.0/ui/angular/node_modules/@types/jquery/JQuery.d.ts
删除 4137 行
find<K extends keyof SVGElementTagNameMap>(selector_element: K | JQuery<K>): JQuery<SVGElementTagNameMap[K]>;8、再次编译
cd /opt/lagou/servers/griffin-0.5.0
mvn -Dmaven.test.skip=true clean install
9、jar拷贝
编译完成后,会在service和measure模块的target目录下分别看到 service-0.5.0.jar 和measure-0.5.0.jar 两个jar,将这两个jar分别拷贝到服务器目录下。
# 将 service-0.5.0.jar 拷贝到 /opt/lagou/servers/griffin-0.5.0/
cd /opt/lagou/servers/griffin-0.5.0/service/target
cp service-0.5.0.jar /opt/lagou/service/griffin-0.5.0/
# 将 measure-0.5.0.jar 拷贝到 /opt/lagou/servers/griffin-0.5.0/,并改名
cd /opt/lagou/servers/griffin-0.5.0/measure/target
cp measure-0.5.0.jar /opt/lagou/servers/griffin-0.5.0/griffin-measure.jar
# 将 griffin-measure.jar 上传到 hdfs:///griffin 中
cd /opt/lagou/servers/griffin-0.5.0
hdfs dfs -mkdir /griffin
hdfs dfs -put griffin-measure.jar /griffin
备注:spark在yarn集群上执行任务时,需要到HDFS的/griffin目录下加载griffin-measure.jar,避免发生类org.apache.griffin.measure.Application找不到的错误。
4.7 启动Griffin服务启动Griffin管理后台:
cd /opt/lagou/servers/griffin-0.5.0
nohup java -jar service-0.5.0.jar>service.out 2>&1 &
Apache Griffin的UI:http://linux122:9876 用户名口令:admin / admin

登录后的界面:

第6节 与电商业务集成6.1 数据资产单击右上角的 DataAssets 来检查数据资产

备注:这里的数据数据资产主要是保存在Hive上的表,要求 Hive Metastore 服务正常
6.2 创建 measure- 如果要测量源和目标之间的匹配率,请选择 Accuracy(精确度验证)
- 如果要检查数据的特定值(例如:空列计数),请选择 Data Profiling(数据统计分析
- 统计表的特定列里面值为空、唯一或是重复的数量
- 统计最大值、最小值、平均数、中值等
- 用正则表达式来对数据的频率和模式进行分析

核心交易分析中有两张表:
- dws_trade_orders(订单明细)
- dws_trade_orders_w(订单明细宽表)
这两张表的数据量应该是相等的(Accuracy)
计算ODS层
订单表的数据量(Data Profiling)
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |