现在Bigtable型(列族)数据库应用越来越广,功能也非常强大。
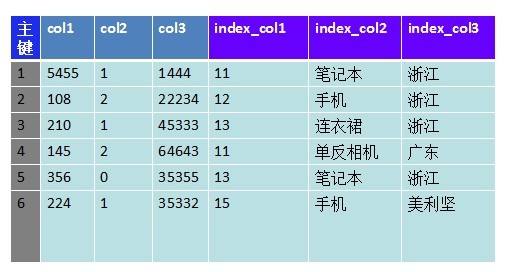
传统关系型数据库(mysql,oracle)数据存储方式主要例如以下:
图一
上图是个非常典型的数据储存方式。我把每条记录分成3部分:主键、记录属性、索引字段。我们会对索引字段建立索引,达到二级索引的效果。
可是随着业务的发展。查询条件越来越复杂,须要很多其它的索引字段,且非常多值都不存在,例如以下图:

图二
上图是6个索引字段。实际情况可能是上百个甚至很多其它,而且还须要依据多个索引字段刷选。
列族数据库非常强大。非常多人就想把数据从mysql迁到hbase,存储的方式还是跟图一或者图二一样,主键为rowkey。其它各个字段的数据。存储一个列族下的不同列。
这时候事实上能够转换下思维。能够把数据倒过来,例如以下图:

图三
把各个索引字段的值作为rowkey,然后把记录的主键和属性值依照一定顺序存在相应rowkey的value里。上图仅仅有一个列族。是最简单的方式。 Value里的记录能够设置成定长的byte[],多个记录集合通过移位高速查询到。
可是上面仅仅适合单个索引字段的查询。假设要同一时候对多个索引字段查询,图三的方式须要求取出全部value值,比方查询“浙江”and“手机”。须要取出两个value,再解析出各自的主键求交。假设每条记录的属性有上百个,对性能影响非常大。
接下来的变化是解决多索引字段查询的问题。我们将主键字段和属性字段分开存储,储存在不同的列族下,多索引查询仅仅须要取出列族1下的数据,再去最小集合的列族2里取得想要的值。储存如图四:
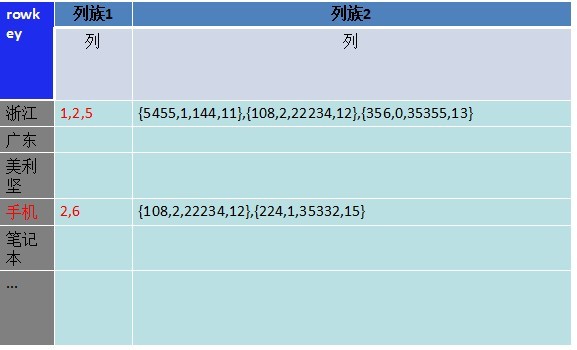
图四
为什么是不同列族,而不是一个列族下的两个列?列族数据库数据文件是依照列族分的。
接下来是对列族2扩展。列族2储存很多其它的列,用来做各种刷选、计算处理。例如以下图:
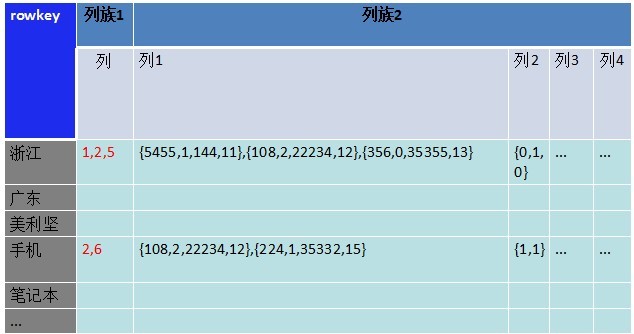
图五
后来我感觉这玩样越来越像搜索了。。。
| 欢迎光临 168大数据 (http://www.bi168.cn/) | Powered by Discuz! X3.2 |