168大数据
标题: Marquez,开源的元数据管理工具 [打印本页]
作者: 168主编 时间: 2021-6-28 14:37
标题: Marquez,开源的元数据管理工具
Marquez是一款开源的元数据服务,用于数据生态系统元数据的收集、汇总及可视化。它维护着数据集的消费和生产,为作业运行时和数据集访问频率提供全局可见性,提供集中的数据集生命周期管理等。WeWork发布并开源了Marquez。
Marquez是一款开源的元数据服务,用于数据生态系统元数据的收集、汇总及可视化。它维护着数据集的消费和生产,为作业运行时和数据集访问频率提供全局可见性,提供集中的数据集生命周期管理等。WeWork发布并开源了Marquez。
Marquez的特征:
数据血缘(Data Lineage)
数据治理(Data governance)
数据健康检查(Data health)
数据发现+探索(Data discovery + exploration)
作业(Jobs)
数据集(Datasets)
重视数据集数据
强化作业和数据集的所有权
- 以最小的依赖进行简单的操作和设计
- RESTful API支持与其他系统的复杂集成:
Airflow
Amundsen
Dagster
- 旨在促进一个健康的数据生态系统,在这个系统中,组织中的团队成员可以信心十足地无缝共享并安全地依赖彼此的数据集。
为什么选择Marquez?
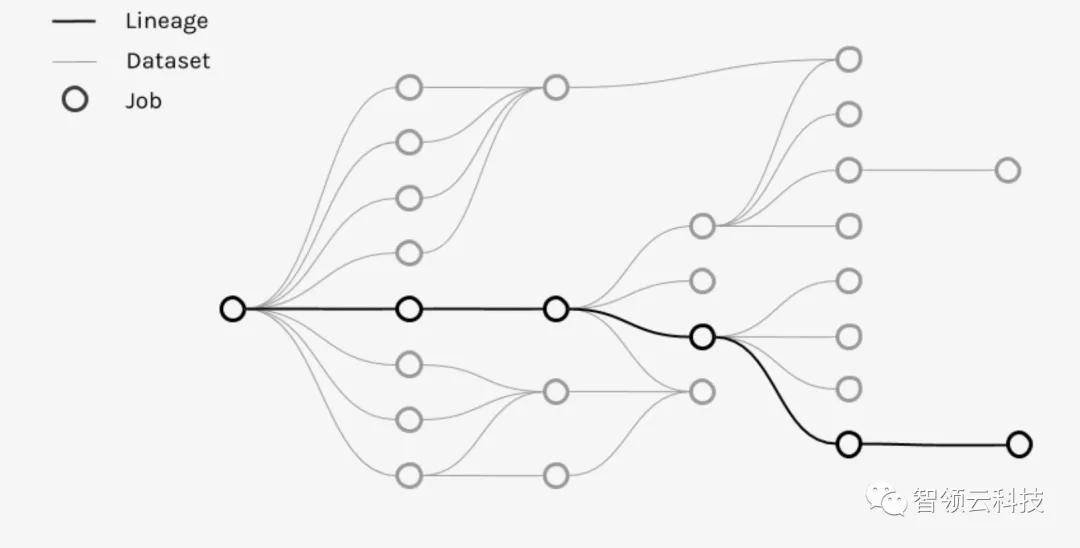
Marquez 支持跨全数据集的高度灵活的数据血缘查询,同时可靠且高效地关联作业及其生成和使用数据集之间的(上下游)依赖关系。
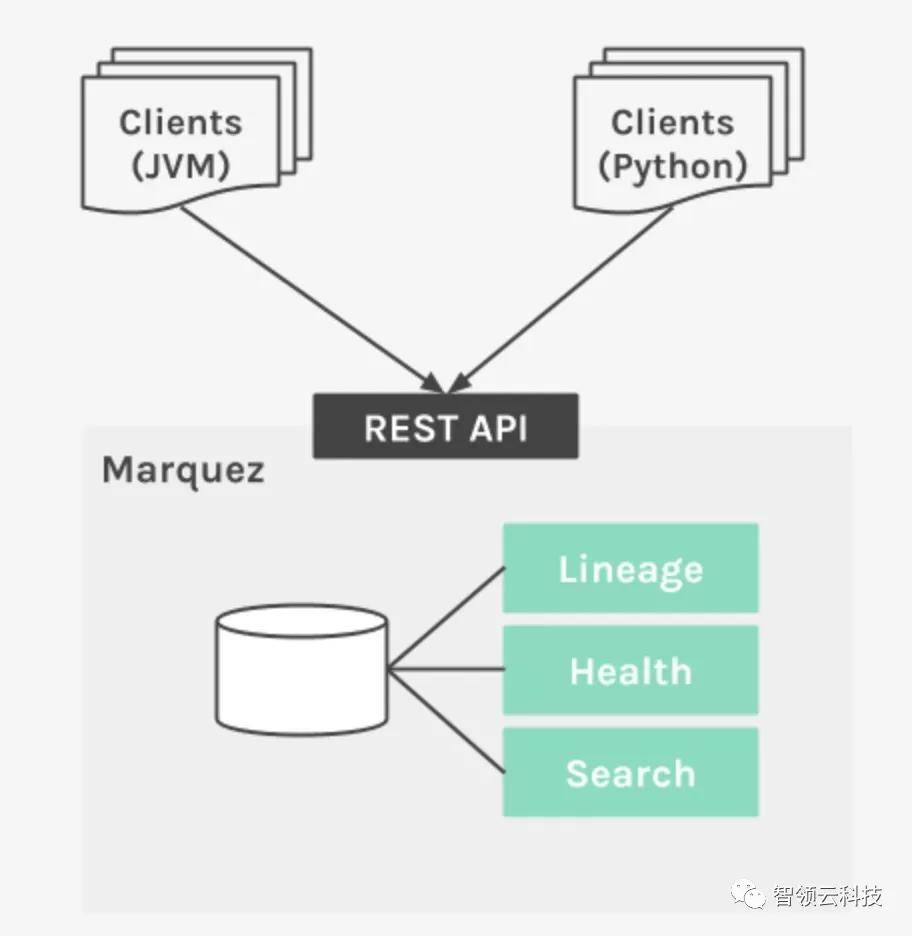
Marquez的设计
Marquez 是一个模块化系统,作为一个可高度伸缩和扩展的去平台化的解决方案,实现元数据管理。它由以下系统组成:
- 元数据存储库:存储所有作业和数据集元数据,包括作业运行和作业级统计的完整历史记录(如:总运行时间、平均运行时间、成功/失败等)。
- 元数据API:RESTful API使一组不同的客户端能够围绕数据集的生产和消费收集元数据。
- 元数据UI:用于数据集发现、连接多个数据集并探索它们依赖关系图。
为了方便采用并使不同的数据处理应用程序能够将元数据收集作为其设计的核心需求,Marquez提供了实现元数据API的特定语言客户端。作为初始版本的一部分,它支持Java和Python。
元数据API是一个抽象的概念,用于记录数据集生产和使用的信息。是一个低延迟、高可用的无状态层,负责封装持久化的元数据、集合血缘信息。API允许客户端收集,且/或从元数据存储库获取数据集信息。
元数据需要被收集、组织和存储,以便通过元数据UI进行丰富的探索性查询。元数据存储库是由元数据API压缩且清洗后的抽象的数据集信息目录。
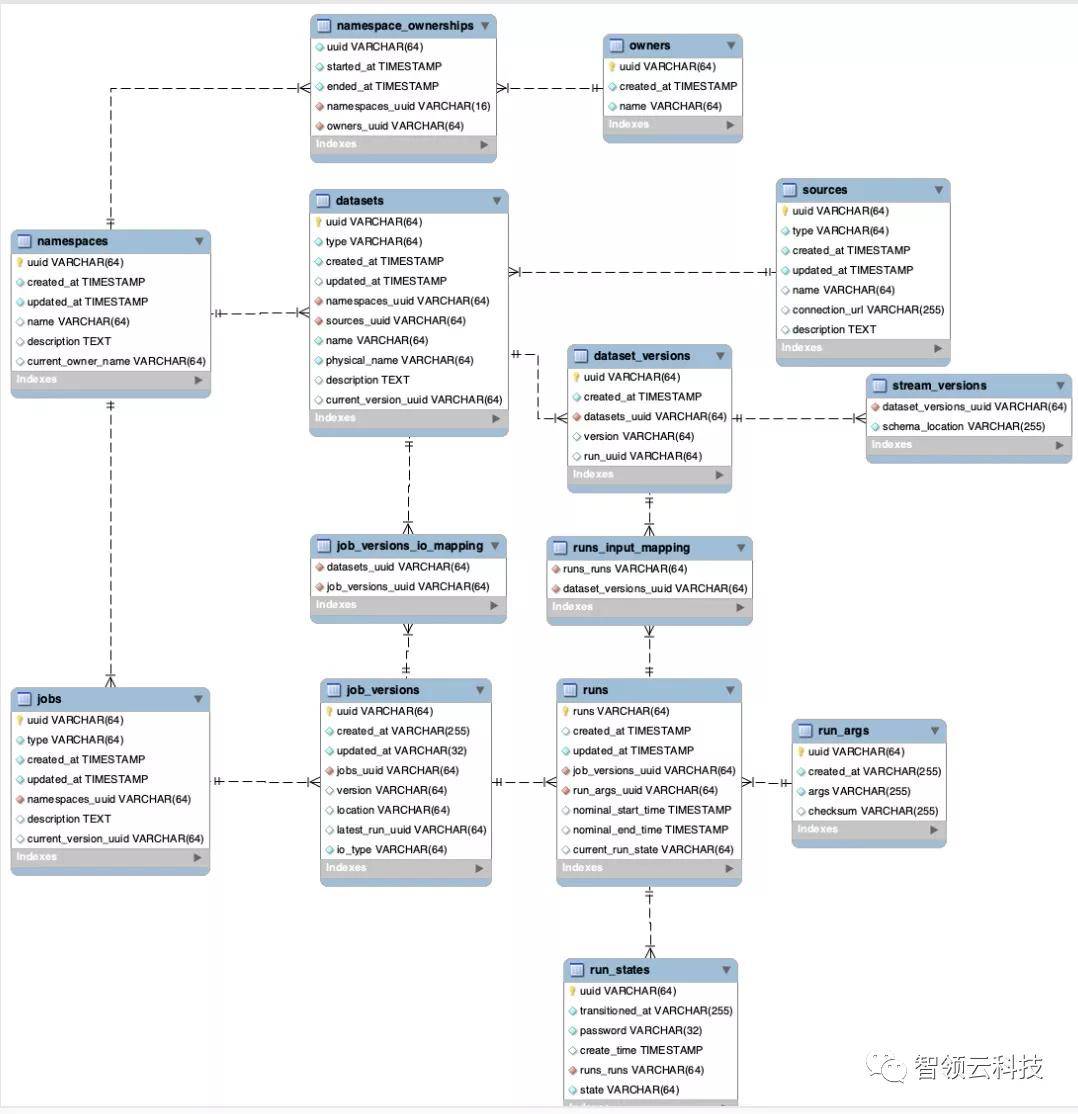
Marquez的数据模型
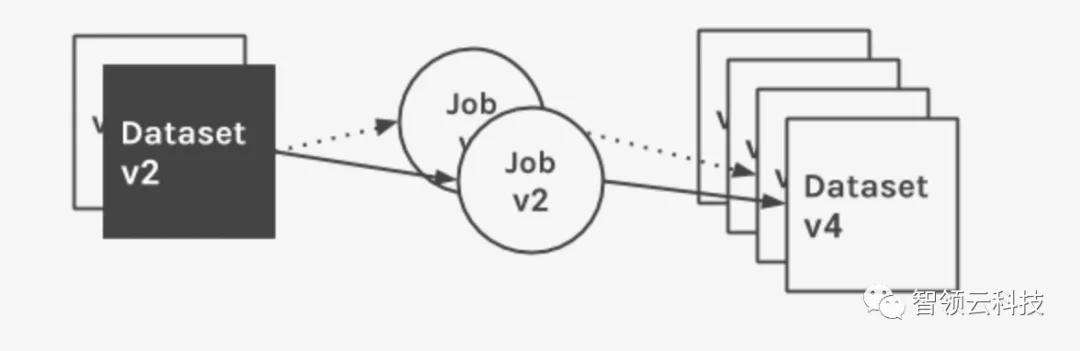
Marquez的数据模型强调数据集的不变性和及时处理性。数据集由作业运行生成,价值重要。作业运行与版本代码链接,并生成一个或多个不可变的版本输出。数据集的更改通过轻量级API的调用被记录在作业执行的不同点,包括运行本身的成功或失败。
下图显示了在多次运行中为给定作业收集和编目的元数据,以及应用于其输入数据集的时间序列变化。
- 作业:作业包含所有者、唯一名称、版本和可选描述。作业会将一个或多个版本输入定义为依赖,并将一个或多个版本输出定义为artifacts。需注意的是,作业可能只定义了输入数据集,也可能仅定义了输出数据集。
- 作业版本:作业的只读不可变版本,有唯一可引用的链接,以编码存储保证源码的重现。作业版本将一个或多个输入和输出数据集关联到作业定义(数据在各种作业中的流转,对记录血缘信息很重要)。这些关联对源链接进行分类,并提供强大的可视化数据流。
- 数据集:数据集有所有者、唯一名称、schema、版本和可选描述。数据集包含于数据源。数据源可将物理数据集分组到它们的物理源。每个数据集都有一个指向历史更改集的版本指针,由Marquez来维护。当将数据集更改提交回Marquez时,将生成一个唯一的版本ID,进行存储,然后将其设置为当前版本,并在内部更新指针。
- 数据集版本:数据集的只读不可变版本。每个版本都可以独立读取,有一个唯一ID,映射到数据集的更改,以保留其在特定时间点的状态。只有当数据集的更改被记录,才会更新最新版本ID。为了计算不同的版本ID,Marquez将版本控制功能应用于与底层数据源的数据集相对应的一组属性。
| 欢迎光临 168大数据 (http://www.bi168.cn/) |
Powered by Discuz! X3.2 |