����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
���ݺ�������2011���������չ�����죬������Ŀǰ�Ѿ������°볡�����ͨ�������ݼ���ʵ��ҵ��Ĺ�ҵ�������������ǽ�Ҫ���ٵ���Ҫ��ս�� ������ҵ���ֻ�ת�͵ļ��٣���ҵ�����Ʊػ�ӭ������ʽ��չ���������ڸ���ϵͳ�Ľ������������������ʹ�óɱ�����Խ��Խ�ߡ���ҵ����һվʽ�����ݽ��������Ӧ�ԣ� P����洢��ģ�����ݵļ���ʽ����������ԭ�еĽṹ�����ݴ洢���Լ����ֻ�ת�ͺ�Խ��Խ��ķǽṹ�����û���Ϊ��־��ͼƬ����Ƶ���ĵ����룬������Ӧ�ý�Ƕ��Խ��Խ���ҵ����T����������������ģ�ӹ�Ԥ������㣬����ڶ�������ͬ���û�����Ƚ�����Խ��Խ��ij����������������ǧά�ȣ����ܼӹ����㣬�Լ�T����������Ϣɨ�裻ͬԴ�칹���ݷ��ʣ����ݵĴ洢���������������ԭʼ��OGG�������洢��Oracle����֧��key-V���ٲ�ѯ��������Ϣ�洢��Hbase����Щ�������������������ʱ������ֻ��Ҫͨ����ѯ����Spark��Hive�ȣ�ֱ�Ӷ�ȡ���ػ�Ԫ������Ϣ����ʵ�ֽ����������ʵ�����ݴ洢������hdfs��hbase����Oracle�ȶ�����������������ݹܵ���֧�ֽ�����ҵ�����ݿ��ٻ�۵����ݺ��������δ����ݷ������㣬ģ��Ԥ�⣬���ʱЧ������Ԥ��,��Ҳʧȥ��ֵ�ˣ�������������Ϊ�滮�����ݺ������������������ ���ݺ�ƽ̨���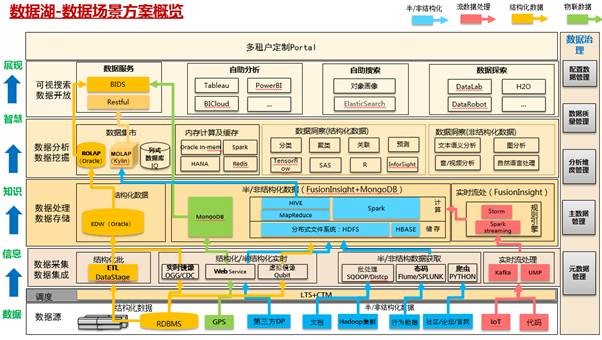
���ݺ�ƽ̨��һ��ϼܹ����Դ�ͳOracle�뻪ΪFusionInsight HD&LibrAΪ��������ͳһ�ںϵ�����ƽ̨��ȫ������ͨ��Ϊ���з����졢��Ӧ���桢��װ����������ݣ���ǿ���ݽ�����ʹ�������������Զ��������ܻ�������������Ч�ʡ� ��ƽ̨Χ�����ݷ�Ϊ���롢����ʹ洢������ģ�飺 
���ݽ�����1�����ݽ���ԭ�� ��Ӧ������Ϊ�������Ƚ����ֵ����������Ŀ������ݱ��������ݹ�������֤��������Ӧ�����ʲ�����ƥ���Ӧ�������������ݽ�ģԭ����ԭʼ���ݡ���ϴ�������ݡ�����ʽ�ṹ�������������Ϲ淶����ƽ̨����ϸ߿��á�ƽ������ԭ����ҵ��3-5������ݹ滮
2����������Ӧ�ó��� ���ݺ������������ռ������㴦�������ݷ����һվʽ������̨������ͼ��Ӧ�ó��������������̡�����ƽ̨�����˱�ע: ����ɫ���ṹ������ͨ�������������⾵��Hive���ݣ���ͨ��KylinԤ���������ݴ�����Cube�У���װ��RESTAPI�����ṩ�߲������뼶��ѯ����������������������ɫ��IoT���ݣ�ͨ��sensor�ɼ��ϱ���MQS����stormʵʱ�ּ�HBase��ͨ���㷨ģ�ͼӹ������ICT����Ԥ����⡣����ɫ����������ͨ��ETLloader��IQ��ʽ���ݺ���������ϴ�ӹ����ṩǧ�ڹ�ģ����ɨ�����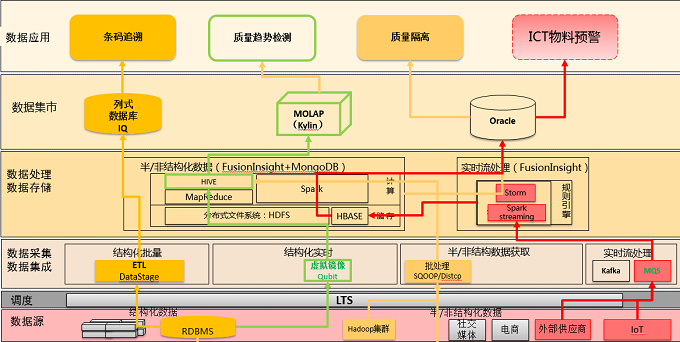
���ݴ洢����Ŀǰ���ݺ����������FusionInsight HD&LibrA��Oracle����ƽ̨Ϊ�����������ԭ�����£� 1�� ��ֵ�����ȶ����ݣ���FusionInsight LibrA��OracleΪ������FIN���ݣ� 2�� �����ԡ��ǽṹ��������FusionInsight HDƽ̨Ϊ������ͼƬ����Ƶ����ͼ�����ݣ� 3�� ��Դ���裬��ԴϵͳΪ��ϵ�����ݿ����Oracle��ԴϵͳΪhadoop��Խ�FusionInsight HD�� 4�� �������Ƚ���ԭ����IT�����졢�з����룻 ���ǰ����������͡����ݹ淶�����ó����������� ������������������Ϣ��ϵͳ�е����ݷ�Ϊ�ṹ�����ݺͷǽṹ�����ݡ��ǽṹ���������ʽ�dz���������Ҳ�Ƕ����Եģ������ڼ����Ϸǽṹ����Ϣ�Ƚṹ����Ϣ���ѱ��������⡣���Դ洢�������������Լ�������Ҫ�������ܻ���IT���������纣���洢�����ܼ�����֪ʶ�ھ����ݱ�������Ϣ����ֵ�������õȣ��������ǰ��������ͷ�Ϊ�����������̣� �ṹ�������ṹ������Ҳ���������ݣ����ɶ�ά���ṹ���������ʵ�ֵ����ݣ��ϸ����ѭ���ݸ�ʽ�볤�ȹ淶����Ҫͨ����ϵ�����ݿ���洢������ �ǽṹ�������ǽṹ�����������ݽṹ�������������û��Ԥ���������ģ�ͣ������������ݿ��ά���������ֵ����ݡ��������и�ʽ�İ칫�ĵ����ı���ͼƬ��XML, HTML�����౨����ͼ�����Ƶ/��Ƶ��Ϣ�ȵȡ�֧�ַǽṹ�����ݵ����ݿ���ö�ֵ�ֶΡ����ֶκͱ䳤�ֶλ��ƽ���������Ĵ����������㷺Ӧ����ȫ�ļ������ֶ�ý����Ϣ�������� ��ģ��ҪҪ��ͳһ���������ǽṹ���ݣ��������ݼ���������������ά����Ա������ʱ����Ϊ���������ֶΡ��ǽṹ�����棬�ǶԶ���ʽ�����ֻ����Ա�Ŀ,�Զ���Ԫ����,���������ǽṹ���칹���ݲ���ͳһ���ļ�Ԫ���ݶ����ݽ��н�ģ,ÿһ��Ԫ���ݿ�����Ϊ�����ݵ�һ��ά��,�������������ݵ�ÿ��Ԫ�������Խ��ж�ά����,������ͬ���͵����ݾͿ����γ��˹����������ǽṹ������(ȫ���ı���ͼ��������Ӱ�ӡ���ý�����Ϣ)�� ����ƽ̨��HBase��mongoDB��HDFS�� ������ʽ��֧��push��pull���ֲ��ԣ���ѡ��HBase�����迼�Ǵ���İ汾��������ҵ��鿴��ʷ�汾�� ���ݺ�Ӧ�ó��������ݺ���Ӧ��������Ҫ�����¼������������� 1���������� �������˻���GPS����λ�õ�ʵʱ�������ӣ�����ʵʱ���������ϱ���������5���ӹ����䵥���˵ķ���Ԥ����������鿴���յ�Ӱ��Ļ�������������ʵ�֣���Ҫʵʱ��ͨ���ˡ��ִ����������ƽ̨���ݲ�Ҫ��5��������ˢ�¾ͷdz������ˡ� 2���������� ���վ�㽻���ƻ������������á����������յ�ʮ���ֳ������+��ϸ15����ȫ��ˢ�³�����֧�Ž�����Ա���ٺ˲�Ӱ�콻���ؼ��㣬�÷����ѵ�������Ŀ����վ��ۺ����ݺ�ǧ����ϸ����ͬ��ˢ�£���������һ���Խ����� 3���������� ͬ����ͨ�������������������ƻ������������������յ����������������ݣ������û�ʵʱ�������ʵʱ�����쳣��⣬�ṩ�û������Ӳ��쳣�����ո�����������IJ㼶�����Ǹ�ʵʱ�����������㣬�����зֲ�ʽ��������ʵ�ֹ������ͺ����Ч�ʼ������䡣 4���������� ���ǻ�����Ϣģʽʵ������AOI��Ƭ����ʵʱ�ɼ�����������5ǧ�����Ϣ��֧����ҵ��ˮ���뼶��أ���ΪIoT���Ե㹤�̣�ϣ�����ǵ�̽�����������塣 5����Ŀ��Ӫ ��iBuy��iGo��iResource��5��Դ������ϣ�ʵ��Ԥ�������ʵʱ��ѯ����ֵԤ��������PO�ں�����Χ�ڿ���ִ�У�����HBase��Ч��ѯ����ʵ�ֺ�����ϸ���ݵ��뼶��ѯ���顣 ���������ɼ����ֻ���Ӫ�ƽ���ҵ����ʵʱ���ӣ���ʵʱ��⣬����ϸ������������ɿأ������ݴ�������ֵ��
| 
 /1
/1 

 |������������
|������������
 ������ 2021-4-16 21:05:23
������ 2021-4-16 21:05:23
 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������