����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
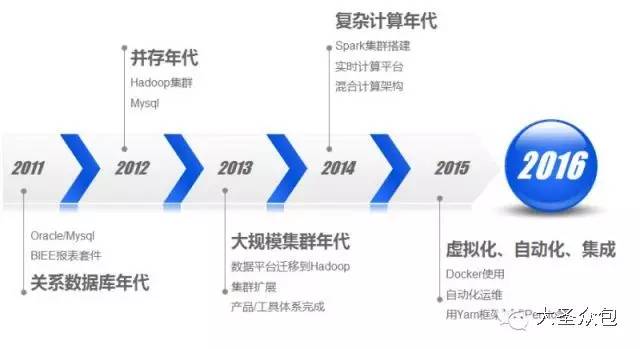
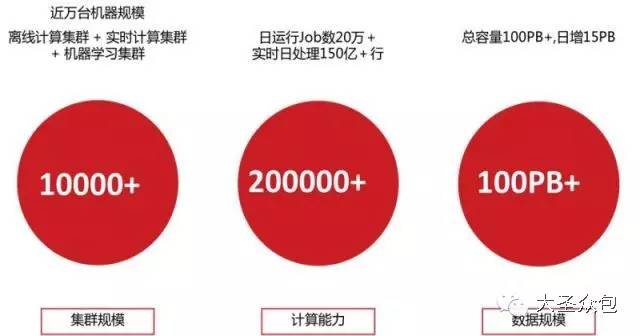
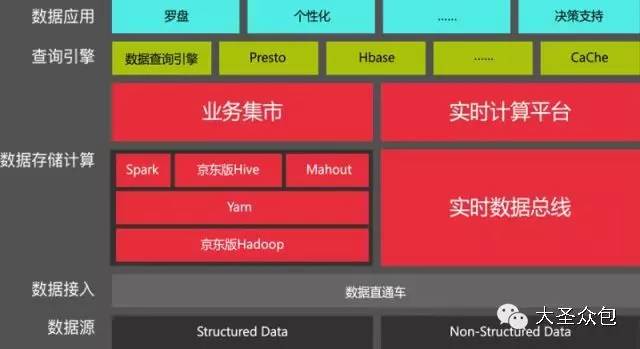
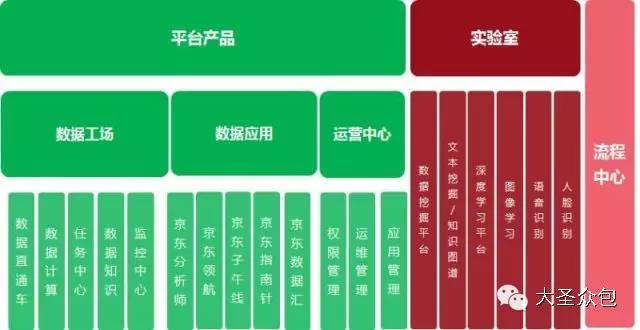
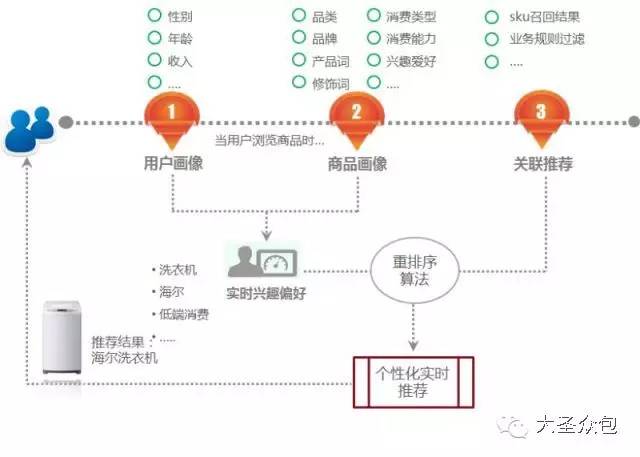
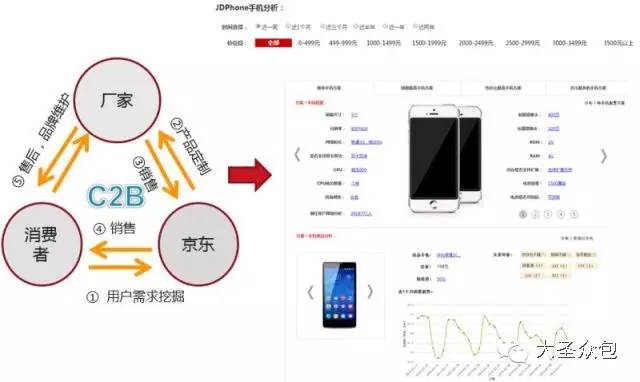
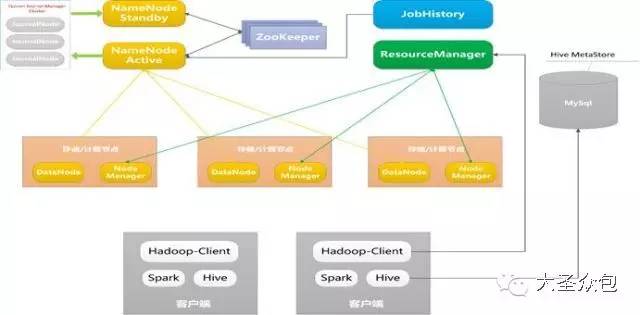
����������ƽ̨���ܹ�ʦ�Թ�����Ϊ��ʥ�ڰ�����ɳ���������α����Ӽ�����Ӧ�á���Ӫ����ά�ȶԾ���������ƽ̨������ϸ�����Ⱥ�ѱ�ʾ�ɻ�̫�࣬�����dz��ɳ������Ҫ��Ϊ�α������뻥�����������֡���Ϊ���ʵ¼���£� �����Թ����α����ʷ��� �����α�����������������3������ɣ� ����������������������ƽ̨�ķ�չ���̼��ſ����Լ������������ļܹ���������������������㲻ͬҵ��Ӧ�ó�������Ҫ�� ����Ӧ�á������ͨ�������ݷ������ھ������в�Ʒ���£�����û�����ʹ����û���ֵ�� ������Ӫ�������ͨ������������ƽ̨����̬������ƽ̨�ķ���ˮƽ�������� ����1 ������������ ����1.ר�Ҳ�⾩���������ݡ�ƽ̨�ĸ����Է�չ�� �����������ݡ�����������ŵĻ��⣬���Ǹ��������������أ� �����ݾ���������ƽ̨��֪���ܹ�ʦ�Թ�����Ϊ����������һ�������������������ݴ���������һ�ֵļܹ��Ա�����ͼΪ�������ǿ���������������������ƽ̨�������ļ����εķ�չ�� ������ͼ������������ƽ̨�ļ����εķ�չ�� �����ڹ�ϵ���ݿ�����������Ⱥ�ʹ����Oracle ExaData һ�����Mysql���ݿ⣬������ҵ��Ŀ��ٷ�չ���������������ͣ�����Ȼ����ͳ����ҵ�����Ѿ����㲻�����潥���������ˡ� �����ڲ�����������š�ѩ�ܡ���Ŀ��������������ʼ�о���ʹ��hadoop��Դ��������������ƽ̨����ʱ�DZ��о��߿����������Mysqlƽ̨��������һЩ���ݴ���������2012�꣬Hadoop��Ⱥ�ѳ��߹�ģ�����ݳ�ȡ�������������µ�����ƽ̨�Ͽ����� �������ſƼ��ķ�չ�����ģ��Ⱥ������٣���Ⱥ�������Ǽ������ӣ��������Ӱ�̨������ǧ̨��������������ȫ��Ǩ������ƽ̨��ͬʱ��Χ�ƴ�����ƽ̨�Ĺ���/��Ʒ��ϵҲ������ɡ� �����ڸ��Ӽ���������������Spark��Ⱥ�������о������ھ��㷨ƽ̨��ͬʱ��Ϊ������ʵʱҵ����������Kafka+Storm���ڴ���������������Ҳͻ�������ݿ�ʵʱ����ץȡ��������ʵ��ʵʱ����ƽ̨��������ƣ�Persto��ElasticSearch�ȼ�ȺҲͬʱ��ʼʹ�á� ����2015�꣬���⻯���Զ��������ɣ���Ϊ���������ݵĹؼ��ʣ��������������Զ�����ά���ߣ���ʹ��Docker��������Դ���룬�Լ�������Yarn��ܣ�������Persto�ȡ�2016�꣬�����������Ը߶˿Ƽ��ͼܹ�ʹ��Ӫ��Ϊ��Ч��ݡ� ����2.��������ǰû�����ܣ�һ�ж������� ������ͼ��Ŀǰ�����Ĵ�����ƽ̨�ſ��� ������Ϥ������������ƽ̨��������Ҫ��Դ�ھ�����Ӫ����ҵ���POPƽ̨ҵ���Լ��������ڡ��������ң�O2O�����������ܡ�����ҵ��Ӧ�̡�O2O�������ȡ��串���˲ɹ����������ִ������͡��ۺ��Լ��û�����վ��������������ݣ��ǵ��̲�ҵ������ȫ�����ݡ� ������ȻĿǰ�������ݺ�������������Խ��٣�������Ϊ�����ġ��м�ֵ�����ݲ��࣬���Ҵ��ⲿ��������ȡ������Ҳ���ࡣ�ܹ�ʦ�Թ�����¶���������Ǹ�����˼�����飬һ�������վ�����С���������һЩ��ʩ����Ҫ�DZ�����Ʒ�۸��һЩ�ؼ���Ϣ��й¶��Ŀǰ��רҵ�Ĺ�˾ͨ������ҳ����ȡ��ص���Ϣ����ͨ������ģ�������˾�����۶�ɱ�������ȵ���ص����ݣ������о仰˵������������ǰû�����ܣ�һ�ж������ġ��� ����3.�����������������ƽ̨���ܹ��뼼���ܹ� ��������������ƽ̨�����ܹ�����������Ҫ�ֳ���������ƽ̨��ʵʱ����ƽ̨�� ������������ƽָ̨���ǣ���Ҫ��Hadoop+SparkΪ�����������ճ��������ݳ�ȡ�ͼ����Ҫ��Ӧ��Spark���ǻ������ڴ沢�м���Ŀ���ܹ������Ч���и��ֲ��л��ھ�ͻ���ѧϰ�㷨����Ҫ��ʵ�ֶԺ������ݵ��ھ��Լ�ΪһЩ��Ҫ���������Ч�ʡ� ����ʵʱ����ƽ̨���⼴����ʵʱ���ݽ��롢�洢������ȫ���̻�����ʵʱ����ƽ̨���������з���ʵʱ���ݽ���ϵͳ���������������Դ��ʵʱ�ɼ�������Kafka�ķֲ�ʽ��Ϣ���У��������ݵ��ݴ桢�Žӣ��乤��ԭ���ǻ���Storm��ʵʱ������������ ������ͼ������������ƽ̨���뼼���ܹ��� ���������ܹ���Ҳ������Hadoop�汾һ�������������ģ���Ϊ��ͬ��Hadoop�汾�����˲�ͬ�ļ������ԡ� ����Ŀǰ�ļ����ܹ�������Spark��Hive��Mahout��Presto��Hbase���ڶ�ļ������ߣ��ǻ���Hadoop �°汾��Yarn��Դ������������ɵġ�Yarn��Hadoop��ϵ��һ���ش��������Ϊ����Ϊһ��ͨ����Դ����ϵͳ����Ϊ�ϲ�Ӧ���ṩͳһ����Դ�����͵��ȡ� ������ͼ������ƽ̨�ļ����ܹ��� ����Ϊ���ÿ�Դ��Hadoop��������ܸ��ʺϾ�����Ӫ��ʵ������������ŶӶ�Դ�����˺ܶ�ĸĶ�������Ϊʲôд����Hadoop�;���Hive��ԭ�����û�Ȩ��������NN�ڵ㡢�ؼ�Ŀ¼����������վ�����ȡ� ����4.ģ�������ģ�Ͳ�� ��������������ƽ̨�ӽ���֮�����ǹ�˾��ͳһ����ƽ̨����ģ�Ͳ���ϻ���Ϊ4����Σ� ����BDM���������ݣ�Դ���ݵ�ֱ��ӳ�� ����FDM���������ݲ㣬���������������������� ����GDM��ͨ�þۺ� ����ADM���߶Ⱦۺ� ������������ģ�Ͳ�κʹ�ͳ�����ݲֿ�ģ����������Ƶģ�������˴�ͳ�ֿ��һЩģʽ����ͬ���ǣ���������ͳ�IJֿ�ģ����ư���з�ʽ���ʹ�ɢ�����ϵĴ�����һ��ԭ��������������̫�Ӵ��ˣ����������еļ�¼����ͳ���������治ת�ģ���һ��ԭ���ǣ�ҵ��ϵͳ����ƴ������ϱ�����֮ǰ������Ϣɢ���ģʽ���û�ע��ͳһ��һ���ط����������ִ������͡��ۺ���Ƕ������ϵͳ���������ҵ��ģ�������������Զ���Ϊ��������������Ϣ������ ����5.�µļ���Ҳ�ڹ�ע�����Ǹ�ѭ���Ĺ��� ���������������£�������������������ƽ̨��Ŀ���Ǵ���һ�廯����������ƽ̨��Χ������ƽ̨�Ĺ�������Ӫ������������һϵ�й��������ù���������Ч�ʡ� ������ͼ����������һ�廯��������ƽ̨�� �������ݹ��������������ݳ�ȡ���ߣ����ߺ�ʵʱ��������ҵ�����������ó�ȡ���ݣ�������IDE�����ڿ�����Ա�����ݲ�ѯ�����ݶ�����������Hadoop��Spark��Presto��JES��Hbase������Դ������֪ʶ��Ԫ���ݹ������ߣ�������Ŀ�����������ͻ�����ȫ���ء� ��������Ӧ�ã��������������Ʊ����Ĺ��ߣ���������ƽ̨��OLAP�������ߣ��DZ��̹����Լ������ƶ��˵Ĺ��ߣ�������������������ݲ鿴���Ự����ز鿴����������ල�ȣ��� ������Ӫ���ģ��û�Ȩ�����롢����������ȡ� ����ʵ���ң���Ҫ�Ƕ�һЩ�¼������о���Ӧ�ã������ھ�ƽ̨��Scalaʵ����GBDT��LDA���㷨ģ�ͣ�����ѧϰ�㷨���о���������ͼ��ʶ���Լ��ı��ִʺ��ھ�ȡ� ����2 ����Ӧ�ò��� ������ͼ���û����� �����û������������������Ҫ�����ݷ������֮һ���Ǿ�Ӫ������Ʒ���¡����Ի�����Ļ�������Ϊ�û����ٶȽ��ͣ�ͨ���û�����ȥ�˽��û����������ǵ�Ŀ�ꡢ��Ϊ�۵�IJ��죬����������Ϊ��ͬ�����ͣ�Ȼ��ÿ�������г�ȡ���������������������֡���Ƭ���˿�ͳ��ѧҪ�ء�������������ʹ֮��Ϊһ������ԭ�ͣ�personas�����û������Ƕ�̬�ģ����û���Ϊ���ݵ���ʵ��ԭ���ǻ��ڳ����Ļ�ԭ����Ҳ���ܴ����˲��ǡ���ʵ���ݡ��������û������Ӧ�úܶ࣬�����������Ƽ���EDM�ȣ���һһ�о��ˡ� ������ͼ�����Ի��Ƽ��� �������Ի��Ƽ����û�������һ������Ӧ�ã����Ի��Ƽ���Ŀ����ʵ��ǧ��ǧ�棬���켫�ȵĸ��Ի��̳ǣ�ʵ�����˶��죬����½ҳ�����Ի����������к�ǿ������ԡ� ������ͼ�����ڴ����ݷ�������ķ���������ģʽ�� ������ͼΪ��һ��Ӧ�õľ������ǻ��ڴ����ݷ�������ķ���������ģʽ�������û�������Ʒ�����ݷ��������Եõ��û��Բ�Ʒ��ϲ�ã�����Щ���ݷ�������Ʒ�������ң�����ʹ�����ڲ�Ʒ�Ĵ��º�������еķ�ʸ�����̲�Ʒ���������ڣ����������ɱ�����������������ģʽӦ�÷�Χ�ܹ㣬Ŀǰ���ֻ���չ�������ļҵ�Ʒ����á����Ƶ����ݲ�Ʒ�����������̺�Ӧ�����̡����ݲ�Ʒ�����ݱ��ֺܺõ�һ�ַ�ʽ��������������һ����Ʒÿ���������������ǧ������룬��dz��ڽΡ� ���������û�������Ϊ�͵���λ�õķ��������ԶԳ��е���Ȧ������Ȧ����ȷ��λ�����ݿ��ṩ���̼�ʹ�ã��������̼Ҹ�����������Ȧ��������Ⱥ�����Լ��Ķ�λ�ͻ�Ʒ������ѡַ�ȡ����Ƶ������кܶ࣬���Ʒ��̬���ۡ����ٲ�����·���Ż��ȣ����ǻ��ڴ����ݷ�����Ӧ�á� ����3 ������Ӫ���� ������ͼ������һ�廯�����Ի���������������ƽ̨�� ��������һ�廯�����Ի���������������ƽ̨������Ӫ��һ��ʤ������ ����ƽ̨�ķ���ˮƽ�������������¼��㡣����������������������SLA�ķ���Ŀ¼�͵ȼ��������淶ģ�͡�����������Ȩ�ȡ�������������������������ͨ��������ר����֤��ѵƽ̨ʹ����Ա��������֤����Ա���ܿ�ͨʹ��Ȩ�ޣ���֤ƽ̨ʹ�õĿɿ��ԣ���ͨ���ṩһվʽ�ķ���ƽ̨�����û����������������Դ���롢�������ơ����ݶ��ġ����ݲ�ѯ�ȹ������������ƽ̨��Ա�Ĺ���ѹ�����з�ƽ̨����Ʒ���¼������������ھ�ƽ̨�����ѧϰ�㷨�ȣ������ˮƽ���ٽ�����Ч�ʡ�����ϵ���Ӵ�Ļ�����Ⱥ��ά�������Ǹ��dz����ص����⣬����̨�����ͼ�ʮ����������������û��һ�������ļ����ϵ��ά�������൱������������ƽ̨��������ļ����ϵ���Ի�����CPU���ڴ桢�洢���˿ڴ�����״�������ݽ����ռ��ͷ����� ������Ͼ���������ƽ̨�Ĺ���/��Ʒ���ж��ڵ���Ӫ������Է�������������֤��Ϊ�����Ӧ�ô�����ƽ̨����Ա������ˮƽ��Ҳ����̬��ϵ�����һ����Ҫ���档 ������ͼ������������ƽ̨�Ĺ���/��Ʒ���ж��ڵ���Ӫ���棩 ������ͼ����Ⱥ��ص�һЩ��Ŀ�� ����������Ⱥ��ص�һЩ��Ŀ������Ϊ����棬�������� ������ͼ����Ⱥ��ؽ�Ŀ���棩 �������Ͼ���ά�Ǵ�����ƽ̨�зdz���Ҫ��һ�����ڣ��������̨�����ͼ�ʮ����������û��һ���õ��ƶȺ���ϵ���Ǿ����������Եġ����ܹ�ʦ�Թ�������˵�� �����α���Ⱥ���ʴ� ������������ʥ�ڰ�������ų����ľ���������ƽ̨��֪���ܹ�ʦ�Թ�������dz���Ľ������������Ⱥ�����ڴ��Ѿõķ���ʱ�䡣 ������1����Ⱥ���ؾ����õ�ʲô�� ������1��service�ĸ��ؾ��⡣ ������2����û����nginx? ������2��ngnix��Ҫ����Web�� ������3������ѧϰ�������Щɶ��r��python������ֱ��дjava�� ������3������ѧϰ�õ���Python��Scala�� ������4����ͳ��ҵ�ľ�Ӫ��������Ӧ�û���ҵ������������Ҫ��ҵ���֧�ֲ�������ȥ�ģ��������ڵ�����Ӧ�������������Ļ���ҵ��������뷨�أ� ������4��Ŀǰÿ��ҵ�������Լ������ݷ����Ŷӣ�����ƽ̨����Ҳ�����ݷ����Ŷӡ� ������5�����������������? ������5�����ݶ��Ŀ�����IDE������ɣ�����ר�ŵ���������Ա�Խ����ṩ�� ������6���ܶ�������ʲôʱ����python��ʲôʱ��ѡ��scala�� ������6������һ�㶼��spark���ܱ�hadoop�úܶࡣ ������7��Ŀǰhadoop ���ȶ�����Σ� ������7���ȶ��Ի����ԣ�Ҳ�ᷢ��Hadoop��ϵ������һЩBUG��������Դ�����ͨ������;�������⡣ ������8�����������ж���Hadoop ���ݽڵ㣿����������� �� ������8�����ڵĽڵ����������̨���ҡ� ������9���ܽ���������HA���ô�� ������9�� Hadoop���ļ�ϵͳ�����������ļ���ʽ�洢�ġ����ң�Hadoop������һ����������ϵ����Դ���ȹ����������������ļ����ܹ�������� ������ͼ��Hadoop���ļ�ϵͳ��
| 
 /1
/1 

 |������������
|������������
 ������ 2016-12-30 17:11:54
������ 2016-12-30 17:11:54




 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������