����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
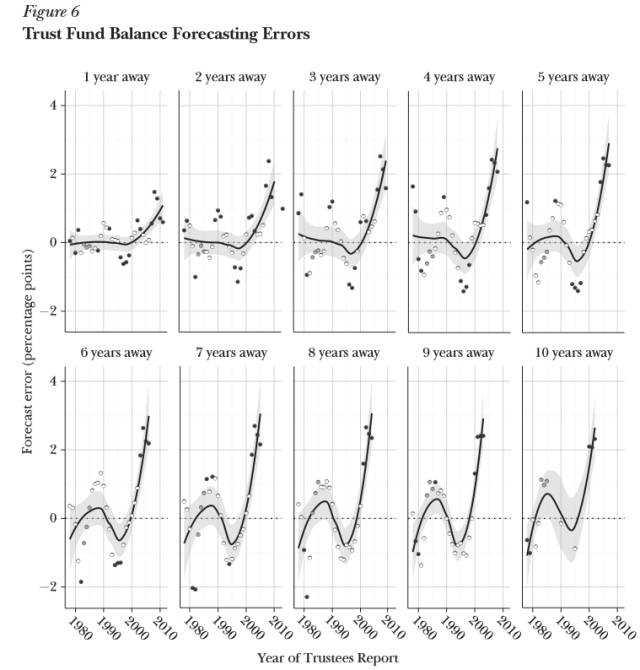
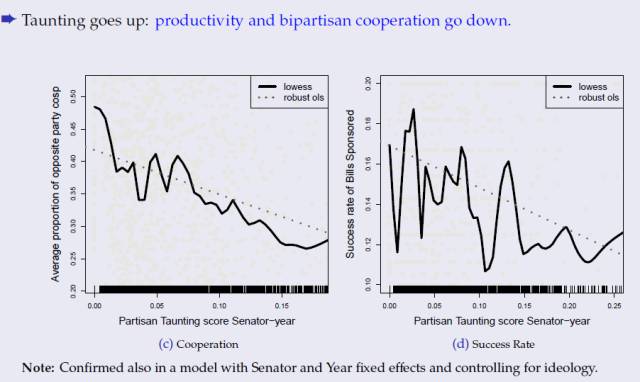
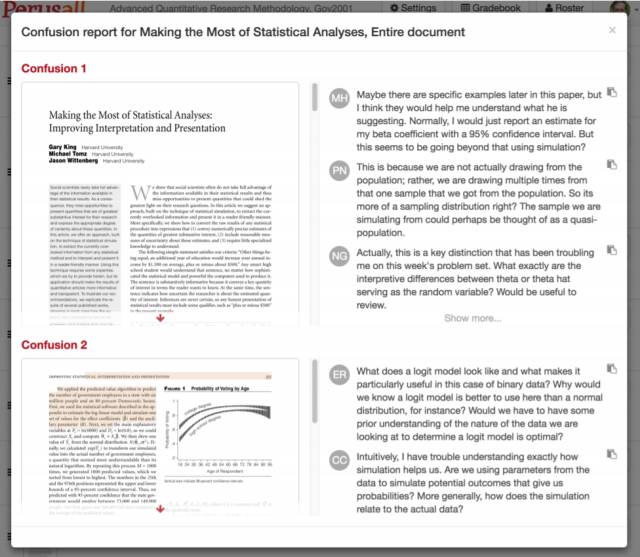
2017����������ѧ����ѧϵ���ڼ����Gary King�����Ϻ���ͨ��ѧ�ٰ���һ����Ϊ������������Ҫ�IJ������ݡ���Big Data is Not About the Data���Ľ����� Gary King�ǹ����ѧ��У�����ڣ�University Professor����King������ʵ֤�о�֪�����ó������о������о��漰����ѧ���������ߡ���ѧ������ѧ��ͳ��ѧ������ ��ͼƬ˵����1��4�գ�Gary King�������Ϻ������ݽ��ֳ��� ������Gary King �����ݽ�ʵ¼����ɾ�ڣ��� �ҹ��������������������ѧ��Quantitative Social Science������ʱ������һ����ƣ��д����ݡ��������ݡ������������ý�巢�ֵģ�����ͼ����ڽ�����������ʲô�ģ�Ŀǰ�������͵�Ч���������� Ȼ���������ݵļ�ֵ���������ݱ�������Ȼ������Ҫ���ݣ����ݺܶ�ʱ��ֻ�ǰ���Ƽ���������������ѵĸ���Ʒ������˵��ѧУΪ����ѧ���ܸ���Ч��ע���������ע��ϵͳ���������ѧ���ĺܶ���Ϣ����Щ������Ϊ�����Ľ������������������� �����ݵ�������ֵ�������ݷ�����������Ϊ��ij��Ŀ�Ĵ��ڣ�Ŀ�Ŀ��Ա䣬���ǿ���ͨ���������˽���ȫ��ͬ�Ķ������������ݹ�Ȼ�ã��������û�з��������ݵļ�ֵ��û�����֡� ������һ���������ڹ������߲������õİ����� ������������һ�������о�������2000���Ժ�������ᱣ�Ϲ�������U.S. Social Security Administration����ơ�SSA�������������籣�˻����˿�������Ԥ����ϵͳ��ƫ� ��ͼƬ˵����2000���Ժ�SSA���籣�����˻������Ԥ���������ƫ���Դ��Gary King���ģ� ���ǣ���������ᱣ��ƽ̨���������ĵ�һ����ƽ̨�������ʽ��ǿ�������ġ�����ǰ�����ߵ����Ͻ����������ǵ���һ���������ڹ������˽���˰�� ����SSA��ҪԤ��������л�����Ŀ����ʽ������Լ��˵���������ȷԤ�����������Ҫ��������DZ�SSAԤ�ڵĸ����١�����Ȼ���Ǻ��¡����ͺܿ��ܵ������л������û���㹻��Ǯ�����������ˡ� �����о����֣�SSA��Ԥ����2000���Ժ������ϵͳ��ƫ�������ƫ���ԭ��֮һ����SSAʹ�õ�ģ�ͱ����϶��Է�����ģ�ͣ��Ҷ���������û�е���������һЩҩ���ʹ�úͰ�֢���ڷ��֣������˿�ʼ��ģ��Ԥ��ظ������ˡ� ����ͨ�������ó��Ľ����ǣ������籣���л������ٴ���8ǧ����Ԫ��ȱ�ڡ� ��Ȼ�����е㲻�ң�����������Ҫ��ǰ֪�������������Ϳ����пռ���˰�ʣ���������ȷ�����е��������ǹ������߲���Ļ��⡣ ���ڶ��Է����Ͷ�����������ʵ������μ�����ġ�������ȫ�����Է����������������Dz����ģ���Ϊ���кܶ����ݲ�֪������ô������ ȫ�������������ɻ���������Ҳ���У������һ�ž��excel�������DZ���û���С��еı�ǩ�����ԣ������ݷ�����Ҫ���������������ɼ���������ļ�����we need computer-assisted, human-led technology���� ���ǻ�����һ������������Ķ���ʵ�顣���ǿ�����һ������������Զ����Ķ��ļ�����������ܰ������Ǵӷǽṹ������������ȡ����֯���Ҵ���������Ϣ�� �������øü���������64000ƪ������Ա�ٷ����������Ÿ壬��ͨ��������������������࣬��������Ա�����Ÿ��ж�˵��Щʲô�� ������Ƿ��֣���Ȼ�иߴ�27%����Ա���������Ÿ�����ֻ�ǵ�����������Է���Partisan Taunting������������Ҫƽ��Ԥ���ֹͣս�����������⡣ ��ͼƬ˵����Gary King��ʾ������Է������Ӹ��˽Ƕ����������Եģ����Ǵ�������Ⱥ�ĽǶ��������Ƿ����Եģ��������Է����������࣬����֮��ĺ�����ϵ����Ч���������Դ��Gary King�о��ɹ���ҳ�� ������ʱ�������ǿ���ͨ��ȥ������ȥ������������Ϣ��ʹ�þ����ͳ��ѧ����������Щ��Ϣ��Ϊ���ܡ� ���ڣ����Ƕ����Զ�һЩǿ�������ԣ�inherently qualitative���Ķ��������������ˣ�����Ƶ����Ƶ�����ǣ�Ŀǰ����һЩ���Է���������Ҫ���������ݻ�δ�����������ԣ����Է�������������Ҫ��ϲ������С� �Ҳ����һ����Ʒ��Ŀ����Perusall����Peruse������ϸ��������˼��Perusall����peruse + all�����Լ�����Ϊ���һ����� �����Ʒ�����ı����ǣ���ѧ���ڻ��ͬѧ�����Ķ���ҵ�����ǽ��ں�������ѧ���Ƿ��Ķ��˹涨���½ڡ�����е�ѧ��û�����е�ѧ�����ˣ����������õ��ڿ�Ч������Ӱ�졣 Perusall�ĺô�֮һ���������Ķ���һ�����������һ���������Ķ����µ�ͬѧ���Զ��Լ��������IJ�������ע��Ҳ���Զ�����ͬѧ����ע���ظ����������������ͬѧ�Ķ������������ԣ����Ķ���ø���Ȥ������������ᶯ���Ҳ��Ϊʲô�����������iTunes�������Ը�⻨Ǯȥ���ݳ��ᣬ��Ȼǰ������������������ ��ͼƬ˵������ѧ�����桱��������Դ����������� һ��ѧ����Perusall�������Ķ�֮�����Ǿ����˺ܶ�֮ǰ�����ܻ���ȡ�����ݣ�֪��ѧ���ڶ�ʲô�����Ƕ��Ķ����ݵķ��������������ڶ�ÿһҳ��ʱ����ʱ�䣻��Ȼ�������û�ж���ĵ�46-47ҳ������Ҳ��֪������� һ���棬Perusall�����ÿ��ѧ�����Ķ������������������ѧ���������Ķ���ҵ���д�֣�����ʦ�IJ��濴����ʡȥ��ԭ���Ķ���ҵ�������������⡣ ��һ���棬Perusall�������Щ�Ķ����ݣ�֪��ѧ���Ƕ�������ʱ�������� Perusall��������ʦ�Ͽ�ǰ����һ����ѧ�����桱��Students confusion report�����õ���ݱ��棬�ҾͿ�����һ�߽�����ʱ˵�����������ǵ��Ķ���������ǿ����������������⡣�� ע�����ĸ���Gary King����2017��1��4�����Ϻ���ͨ��ѧ�Ľ��������������༭���ɡ� ��Դ�������о������㹫����
| 
 /1
/1 

 |������������
|������������
 ������ 2017-2-15 10:40:49
������ 2017-2-15 10:40:49

 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������