����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
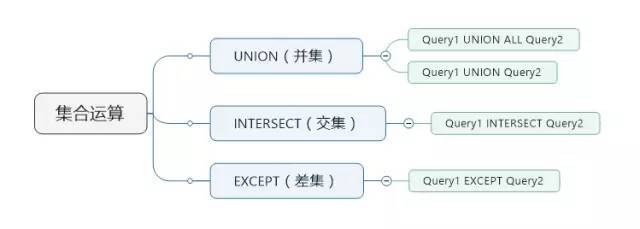
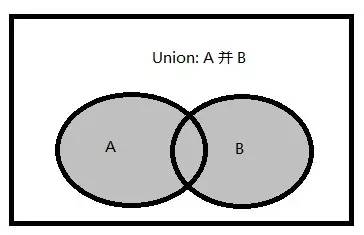
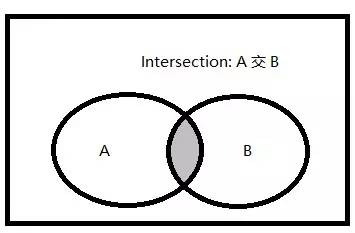
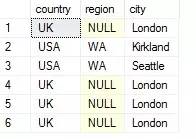
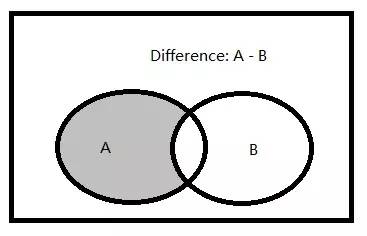
��ǰ�������¶��������ֻ�����������Ҫ�ģ�������Ҫ��Ŀ���Ǿ�ͨSQL��ѯ��SQL�����Ż��� ���� ��ƪ��Ҫ�ǶԼ��������в����������������������ܽᡣ ��������������֣� 1.��������(����) 2.�������� 3.����� �����Ǽ��������˼ά��ͼ�� Ϊʲôʹ�ü������� 1.�ڼ��������б����Ӳ�ѯ��EXISTS/NOT EXISTS�����㡣 ���Ķ�������½�ʱ�����ǿ����Ȱѻ������ã����µ�SQL�ű���������Ҵ������ݿ⣬���������������ݡ� һ���������� 1.�������� (1)��������������ϻ�༯���е����㡣 (2)�༯������������IJ�ѯ���ɵĿ��ܰ����ظ���¼���м������� (3)T-SQL֧�����ּ������㣺����(UNION)������(INTERSECT)���(EXCEPT) 2.� ��������Ļ�����ʽ�� ����IJ�ѯ1 ���������> ����IJ�ѯ2 [ORDER BY] 3.Ҫ�� (1)����IJ�ѯ���ܰ���ORDER BY�־�; (2)����Ϊ��������������ѡ���Ե�����һ��ORDER BY�־�; (3)ÿ�������IJ�ѯ��������������ѯ������(������������˳���ORDER BY�־�); (4)������ѯ ���������ͬ������; (5)��Ӧ�б�����м��ݵ��������͡����ݸ����������ͣ����ȼ��ϵ͵��������ͱ�������ʽ��ת��Ϊ�ϸ����������͡���������IJ�ѯ1�ĵ�һ��Ϊint���ͣ�����IJ�ѯ2�ĵ�һ��Ϊfloat���ͣ���ϵ͵���������int���Ϳ�����ʽ��ת��Ϊ�ϸ�float���͡��������IJ�ѯ1�ĵ�һ��Ϊchar���ͣ�����IJ�ѯ2�ĵ�һ��Ϊdatetime���ͣ������ʾת��ʧ�ܣ����ַ���ת�����ں�/��ʱ��ʱ��ת��ʧ��; (6)����������������������IJ�ѯ1���������ҪΪ����������У�Ӧ��������IJ�ѯ1�з�����Ӧ�ı���; (7)��������ʱ�����н��н��бȽ�ʱ������������Ϊ����NULL���; (8)UNION֧��DISTINCT��ALL��������ʾָ��DISTINCT�־䣬�����ָ��ALL����Ĭ��ʹ��DISTINCT; (9)INTERSET��EXCEPTĬ��ʹ��DISTINCT����֧��ALL�� ����UNION(����)�������� 1.����������ͼ �������������ϵIJ�����һ����������A��B������Ԫ�صļ��ϡ� ͼ����Ӱ�����������A�뼯��B�IJ��� 2.UNION ALL�������� (1)����Query1����m�У�Query2����n�У���Query1 UNION ALL Query2����(m+n)��; (2)UNION ALL ����ɾ���ظ��У��������Ľ�����Ƕ༯�������������ļ���; (3)��ͬ�����ڽ���п��ܳ��ֶ�Ρ� 3.UNION DISTINCT�������� (1)����Query1����m�У�Query2����n�У�Query1��Query2����ͬ��h�У���Query1 UNION Query2����(m+n-h)��; (2)UNION ��ɾ���ظ��У��������Ľ�����Ǽ���; (3)��ͬ�����ڽ����ֻ����һ�Ρ� (4)������ʾָ��DISTINCT�־䣬�����ָ��ALL����Ĭ��ʹ��DISTINCT�� (5)��Query1��Query2�Ƚ�ij�м�¼�Ƿ����ʱ������ΪȡֵΪNULL��������ȵ��С� ����INTERSECT(����)�������� 1.����������ͼ ��������������(��Ϊ����A�ͼ���B)�Ľ������ɼ�����A��Ҳ����B������Ԫ����ɵļ��ϡ� ͼ����Ӱ�����������A�뼯��B�Ľ��� 2.INTERSECT DISTINCT�������� (1)����Query1���� m �У�Query2���� n �У�Query1��Query2����ͬ�� h �У���Query1 INTERSECT Query2���� h ��; (2)INTERSECT������������������ɾ����������༯�е��ظ���(�Ѷ༯��Ϊ����)��Ȼ��ֻ�����������ж����ֵ���; (3)INTERSECT ��ɾ���ظ��У��������Ľ�����Ǽ���; (4)��ͬ�����ڽ����ֻ����һ�Ρ� (5)������ʾָ��DISTINCT�־䣬�����ָ��ALL����Ĭ��ʹ��DISTINCT�� (6)��Query1��Query2�Ƚ�ij�м�¼�Ƿ����ʱ������ΪȡֵΪNULL��������ȵ��С� (7)�������ӻ�EXISTSν�ʿ��Դ���INTERSECT�������㣬���DZ����NULL���д��������������ַ�����NULLֵ���бȽ�ʱ���ȽϽ������UNKNOWN���������лᱻ���˵��� 3.INTERSECT ALL�������� (1)ANSI SQL֧�ִ���ALLѡ���INTERSECT�������㣬��SQL Server2008���ڻ�û��ʵ���������㡣������ṩһ������T-SQLʵ�ֵ��������; (2)����Query1���� m �У�Query2���� n �У������R��Query1�г�����x�Σ���Query2�г�����y�Σ�����RӦ����INTERSECT ALL����֮�����minimum(x��y)�Ρ� �����ṩ����T-SQLʵ�ֵ�INTERSECT ALL�������㣺���ñ�����ʽ + �������� ������£� ����UK NULL London���ĸ��ظ��У� ����������OVER�־���ʹ�� ORDER BY ( SELECT ����> )���Ը���SQL Server���������е�˳�� �ġ�EXCEPT(�)�������� 1.�������ͼ �����������(��Ϊ����A�ͼ���B)�������ڼ���A���������ڼ���B������Ԫ����ɵļ��ϡ� ͼ����Ӱ�����������A�뼯��B�IJ 2.EXCEPT DISTINCT�������� (1)����Query1���� m �У�Query2���� n �У�Query1��Query2����ͬ�� h �У���Query1 INTERSECT Query2���� m �C h ��,��Query2 INTERSECT Query1 ���� n �C h �� (2)EXCEPT����������������ɾ����������༯�е��ظ���(�Ѷ༯ת��ɼ���)��Ȼ��ֻ�ڵ�һ�������г��֣��ڵڶ��������ڲ����������С� (3)EXCEPT ��ɾ���ظ��У��������Ľ�����Ǽ���; (4)EXCEPT�Dz��ԳƵģ���Ľ��ȡ����������ѯ��ǰ���ϵ�� (5)��ͬ�����ڽ����ֻ����һ�Ρ� (6)������ʾָ��DISTINCT�־䣬�����ָ��ALL����Ĭ��ʹ��DISTINCT�� (7)��Query1��Query2�Ƚ�ij�м�¼�Ƿ����ʱ������ΪȡֵΪNULL��������ȵ��С� (8)���������ӻ�NOT EXISTSν�ʿ��Դ���INTERSECT�������㣬���DZ����NULL���д��������������ַ�����NULLֵ���бȽ�ʱ���ȽϽ������UNKNOWN���������лᱻ���˵��� 3.EXCEPT ALL�������� (1)ANSI SQL֧�ִ���ALLѡ���EXCEPT�������㣬��SQL Server2008���ڻ�û��ʵ���������㡣������ṩһ������T-SQLʵ�ֵ��������; (2)����Query1���� m �У�Query2���� n �У������R��Query1�г�����x�Σ���Query2�г�����y��,��x>y������RӦ����EXCEPT ALL����֮����� x �C y �Ρ� �����ṩ����T-SQLʵ�ֵ�EXCEPT ALL�������㣺���ñ�����ʽ + ��������
[AppleScript] ���ı��鿴 ���ƴ��� WITH INTERSECT_ALL
AS (
��SELECT ROW_NUMBER() OVER ( PARTITION BY country, region, city ORDER BY ( SELECT
0
) ) AS rownum ,
country ,
region ,
city
FROM HR.Employees
EXCEPT
SELECT ROW_NUMBER() OVER ( PARTITION BY country, region, city ORDER BY ( SELECT
0
) ) AS rownum ,
country ,
region ,
city
FROM Sales.Customers
)
SELECT country ,
region ,
city
FROM INTERSECT_ALL
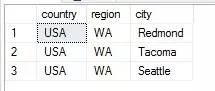
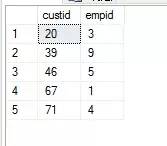
������£� �塢������������ȼ� 1.INTERSECT>UNION=EXCEPT 2.���ȼ���INTERSECT,Ȼ������ҵij���˳�����δ������ȼ�����ͬ�����㡣 3.����ʹ��Բ���ſ��Ƽ�����������ȼ�����������ߵ����ȼ��� ��������� 1.ֻ��ORDER BY�ܹ�ֱ��Ӧ���ڼ�������Ľ��; 2.����������������WHERE��GROUP BY��HAVING�ȣ���֧��ֱ��Ӧ���ڼ�������Ľ�������ʱ�����ʹ�ñ�����ʽ���ܿ���һ���ơ�����ݰ�����������IJ�ѯ�����������ʽ��Ȼ�����ⲿ��ѯ�жԱ�����ʽӦ���κ���Ҫ������ѯ����; 3.ORDER BY�־䲻��ֱ��Ӧ���ڼ��������еĵ�����ѯ�����ʱ�����TOP+ORDER BY�־�+������ʽ���ܿ���һ���ơ��綨��һ�����ڸ�TOP��ѯ�ı�����ʽ��Ȼ��ͨ��һ��ʹ�����������ʽ���ⲿ��ѯ���뼯�����㡣 �ߡ���ϰ�� 1.дһ����ѯ��������2008��1���ж����������2008��2��û�ж�����Ŀͻ���Ա�� ��������� ����һ��EXCEPT (1)���ò�ѯ1��ѯ��2008��1�·��ж�����Ŀͻ���Ա (2)�ò�ѯ2��ѯ2008��2�·ݿͻ��Ķ�����Ŀͻ���Ա (3)�ò�������ѯ2008��1���ж������2008��2��û�ж�����Ŀͻ���Ա
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate
��������NOT EXISTS ���뱣֤custid��empid����Ϊnull��������NOT EXISTS���в�ѯ�����custid��empid������nullֵ���ڣ�������NOT EXISTS���в�ѯ����Ϊ�Ƚ�NULLֵ�Ľ����UNKNOWN������������NOT EXISTS��ѯ���ص��Ӳ�ѯ���лᱻ���˵��������������ѯ����NULLֵ���У�����ѯ����л���NULLֵ���С�
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders AS O1
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate
����cutid=NULL,empid=1,orderdate=��20080101��
[AppleScript] ���ı��鿴 ���ƴ��� INSERT INTO [TSQLFundamentals2008].[Sales].[Orders]
( [custid] ,
[empid] ,
[orderdate] ,
[requireddate] ,
[shippeddate] ,
[shipperid] ,
[freight] ,
[shipname] ,
[shipaddress] ,
[shipcity] ,
[shipregion] ,
[shippostalcode] ,
[shipcountry]
)
VALUES ( NULL ,
1 ,
'20080101' ,
'20080101' ,
'20080101' ,
1 ,
1 ,
'A' ,
'20080101' ,
'A' ,
'A' ,
'A' ,
'A'
)
GO
����cutid=NULL,empid=1,orderdate=��20080201��
[AppleScript] ���ı��鿴 ���ƴ��� INSERT INTO [TSQLFundamentals2008].[Sales].[Orders]
( [custid] ,
[empid] ,
[orderdate] ,
[requireddate] ,
[shippeddate] ,
[shipperid] ,
[freight] ,
[shipname] ,
[shipaddress] ,
[shipcity] ,
[shipregion] ,
[shippostalcode] ,
[shipcountry]
)
VALUES ( NULL ,
1 ,
'20080201' ,
'20080101' ,
'20080101' ,
1 ,
1 ,
'A' ,
'20080101' ,
'A' ,
'A' ,
'A' ,
'A'
)
GO
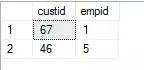
�÷���һ��ѯ�������Ϊ50�У����cutid=NULL,empid=1���й��˵�
�÷�������ѯ�������Ϊ51�У������cutid=NULL,empid=1���й��˵� ������ķ������Խ����������⣬��Ҫ����cutid=NULL,����empid=null�����������50��
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders AS O1
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate
2.дһ����ѯ��������2008��1�º���2008��2�¶��ж�����Ŀͻ���Ա��
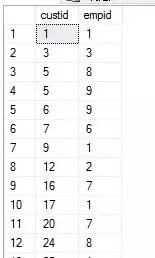
��������� ����һ��INTERSECT (1)���ò�ѯ1��ѯ��2008��1�·��ж�����Ŀͻ���Ա (2)�ò�ѯ2��ѯ2008��2�·ݿͻ��Ķ�����Ŀͻ���Ա (3)�ý����������ѯ2008��1�º�2008��2�¶��ж�����Ŀͻ���Ա
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate
��������EXISTS ���뱣֤custid��empid����Ϊnull��������EXISTS���в�ѯ�����custid��empid������nullֵ���ڣ�������EXISTS���в�ѯ����Ϊ�Ƚ�NULLֵ�Ľ����UNKNOWN������������EXISTS��ѯ���ص��Ӳ�ѯ���лᱻ���˵��������������ѯ����NULLֵ���У�����ѯ����л���NULLֵ���С�
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders AS O1
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate
�������Sales.Orders���в����������ݣ� ����cutid=NULL,empid=1,orderdate=��20080101�� ����cutid=NULL,empid=1,orderdate=��20080201�� �÷���һ��ѯ�������Ϊ6�У������cutid=NULL,empid=1���й��˵� �÷�������ѯ�������Ϊ5�У����cutid=NULL,empid=1���й��˵� ������ķ������Խ����������⣬��Ҫ����cutid=NULL,����empid=null�����������6�С�
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders AS O1
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate
3.дһ����ѯ��������2008��1�º���2008��2�¶��ж����������2007��û�ж�����Ŀͻ���Ա
��������� ����һ��INTERSECT + EXCEPT [AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate = '20070101'
AND orderdate
��������EXISTS + NOT EXISTS
[AppleScript] ���ı��鿴 ���ƴ��� SELECT custid ,
empid
FROM Sales.Orders AS O1
WHERE orderdate >= '20080101'
AND orderdate = '20080201'
AND orderdate = '20070101'
AND orderdate
| 



 /1
/1 

 |������������
|������������

 ������ 2017-4-7 17:33:13
������ 2017-4-7 17:33:13


 QQ���Ѻ�Ⱥ
QQ���Ѻ�Ⱥ QQ�ռ�
QQ�ռ� ��Ѷ��
��Ѷ�� ��Ѷ����
��Ѷ���� �ղ�
�ղ� ת��
ת�� ����
���� ����
���� ��
�� ��
�� ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������