����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
�����ڱ����ٰ��˵������罻ý�崦����ᣨSMP 2017�����������һ�죬���ӿƴ����ν�������һ�������������ھ���ѧ������ѧ�����ѧ��Ӧ�õ��������档���ν��ڵľ��ʱ��棬ʱ�������᳡������������ �ڱ�����������ڳ���ѧ��������Լ��Ľ��飬����Ϊ�ڵ�ǰ�����ݺ��˹�������չ�����ݱ��ʱ�������ѧ������ѧ������ѧ�ȴ�ͳ��ֻ�ܶ��Է�����ѧ�����������ž�ı仯������ʱ�������ޱ�ʱ������ѧ����һ��Ҫվ���ܹ������ش�ɹ��ĵط������Լ�����о���Աһ��Ҫ����ע���ѧ�ƣ�����Щ���������Լ��Ĺ��ס� ���⣬���ν����ڻش��ֳ��Ĺ�������ʱ��������α����Լ���˽�������У���Ϊ���˲�Ӧ������ȥ�����Լ�����˽����Ϊ���Dz����ܵģ�Ҳ��ȫû�����壻������˽�����κ�����������ҵ����������������������÷��������ǹ���ƽ���������������������һ�侭���������Ϊƽ��������ȫ�� ���Σ���Ϊ���ӿƼ���ѧ���ڣ���Ҫ����ͳ�������븴���Է�����о�����Physics Reports��PNAS��Nature Communications�ȹ���SCI�ڿ�����200��ƪѧ�����ģ�����17000��Σ�Hָ��Ϊ63��2009����������Ȼ��ѧһ�Ƚ���2011����ʮ�����й�����Ƽ�����2013����Ĵ�ʡ�Ƽ�����һ�Ƚ���2014����й������ѧ����Ȼ��ѧ���Ƚ���2014����������ѡElesvier��߹���Ӱ�����й���ѧ�����������������ࣩ��2015�굱ѡ��ʮ�����л�ȫ����������ίԱ�������ο�ѧ���������ίԱ�ḱ���Ρ�2015�굱ѡȫ��ʮ��Ƽ��������2016�굱ѡ�Ĵ�ʡ�����ܳ��˲š�2017���ȫ���������Ƚ��� ����ΪAI�Ƽ����۸����ֳ���¼���ڲ��ı�ԭ���������������ɡ�
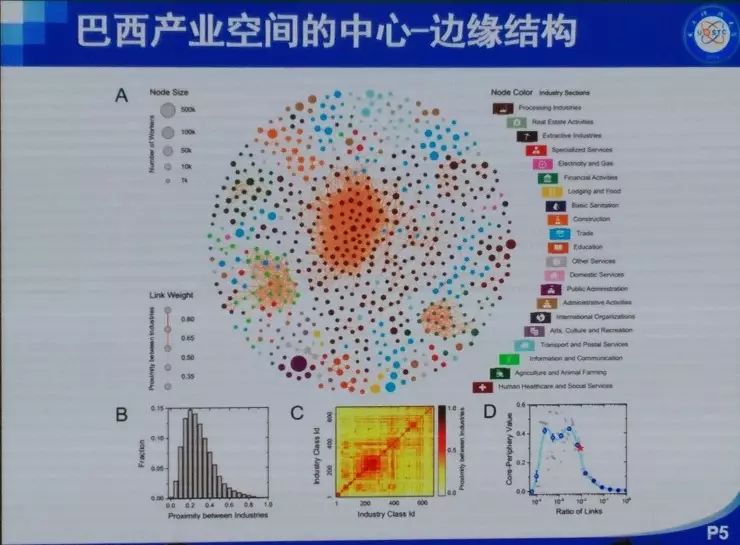
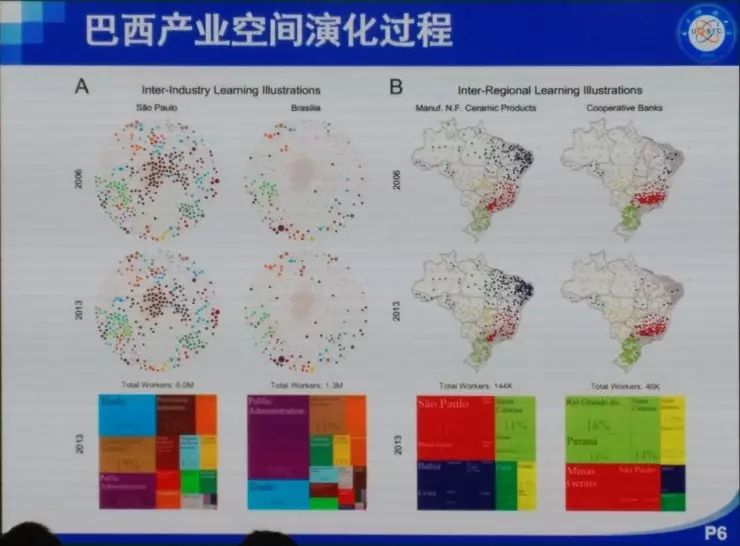
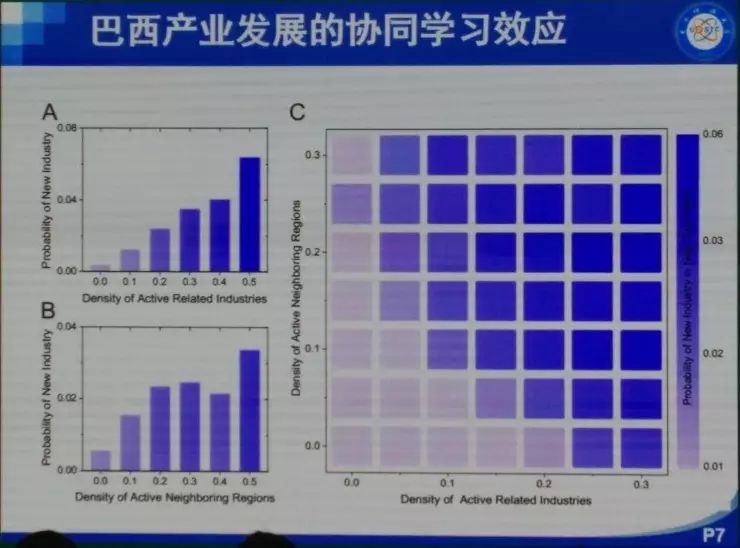
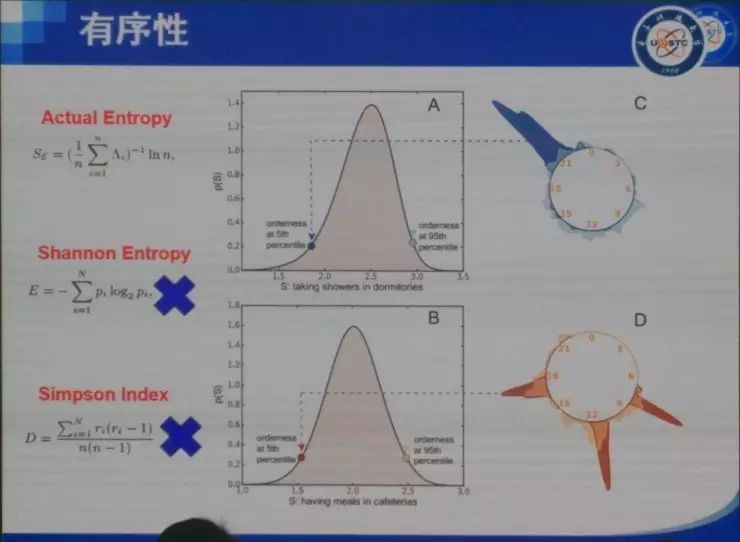
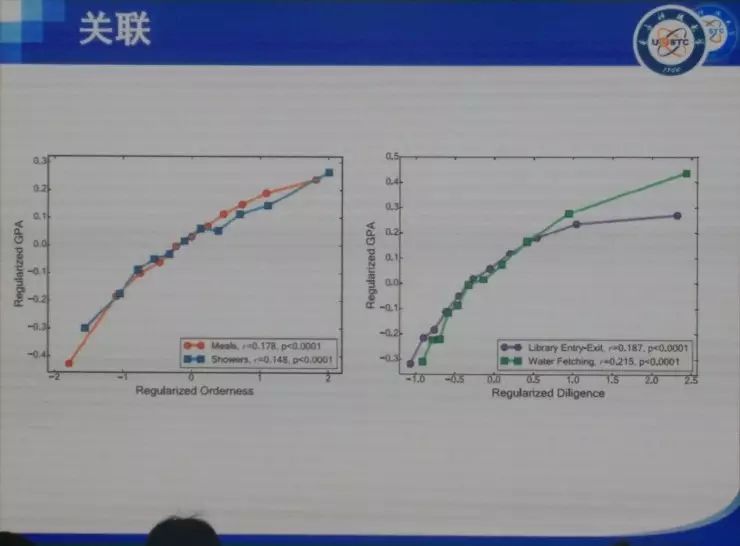
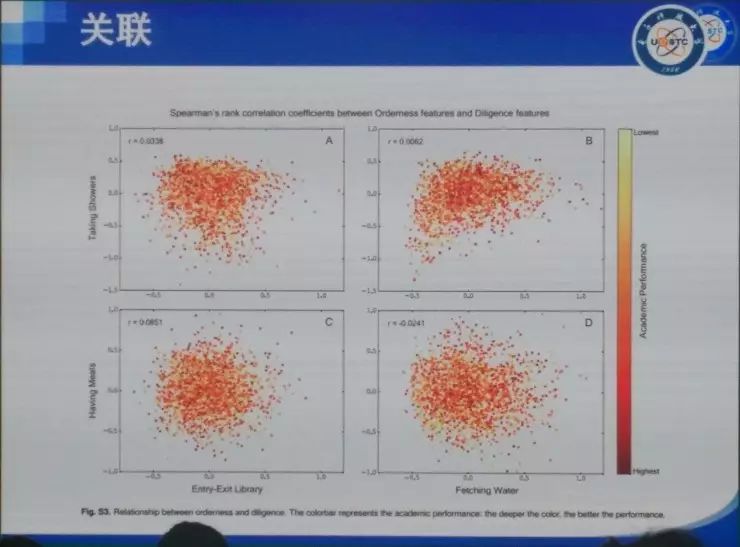
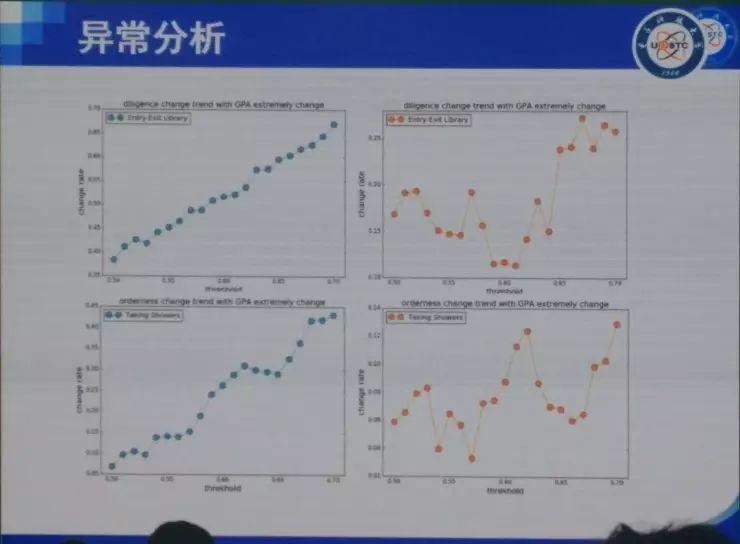
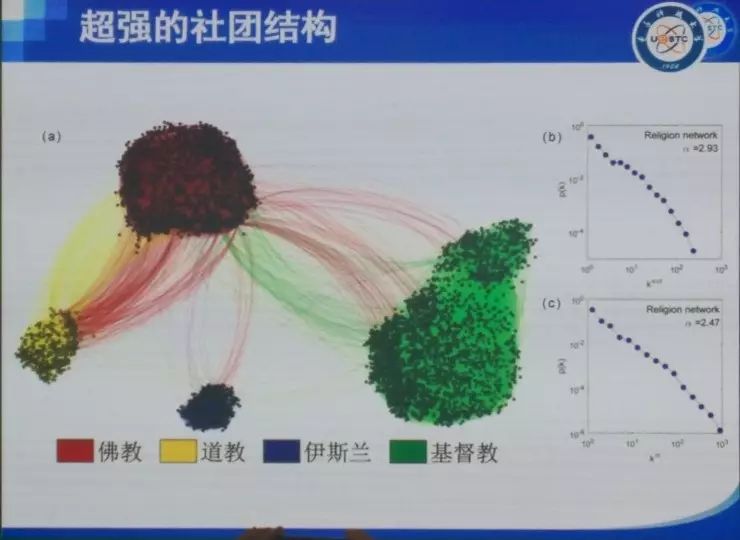
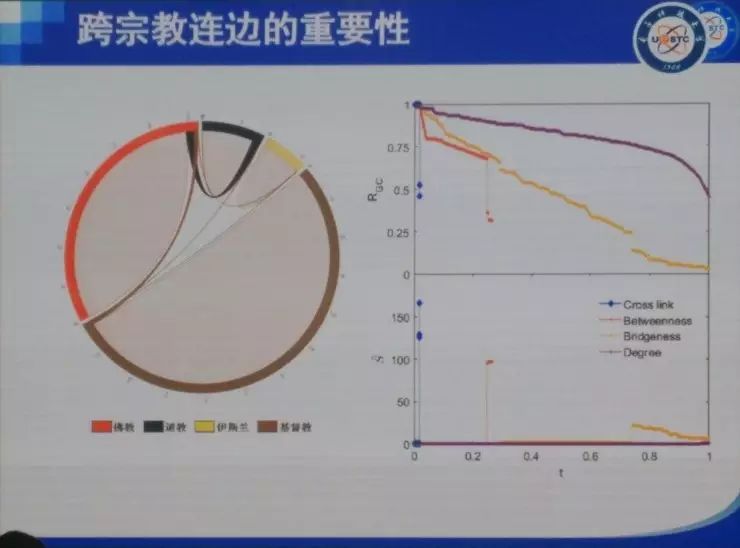
���� ���ȷdz������ܹ����������ô��ͬ�½���������⣬Ҳ�dz���лѧ����ʦ�ͻ�ΰ��ʦ�����룬ллרί�����֯�� �ղ�����ʦ�Ѿ��ᵽ��������ķ�չ���������ᾭ��ѧ�ȣ�����̽�ֵ���ͬ�������⡣���ǵķ����ǣ��ô����ݡ��˹����ܻ�ͳ�Ʒ����İ취ͨ����������ȥ�������ѧ�����ѧ������ѧ�����⡣ʵ���ϴ������Լ��˹����ܴ����˺ܴ�ı仯���Կ�ѧ���ij�������������ڼ����ѧ�Ʊ������ܴ�̶������������������ѧ������ѧ������ѧ�ȵ�ѧ�Ƶ�Ӱ�죬����Щԭ��ֻ�ǰ붨�����߶��Է�����ѧ�Ʊ����һ����������ѧ�ơ� �ҽ�����Ҫ�Ǹ���ҽ�����������˵������Ӱ�졣����������Ҳ�������ǽ��ڵĹ�����һ���Ǿ���ѧ�ġ�һ������ѧ�ģ����һ�����ѧ�ġ� �������뾭��ѧ ��һ�����Ӿ��������ô����ݼ����˹����ܵİ취��ȥ��֪һ�����÷�չ����ʵ����Ȼ���Ը���������÷�չ�Ľ��顣 ��ǰ���Ƿ������ã��õ��˺ܶ�ָ�꣬��PPI��CPI��GDP�ȵȡ�������Щָ����������һЩ��⣬����˵���Ƚ��ͺ�������Ҫ��������һ�����֪����ǰ������ʲô�����⣬�м仹�����д�����ٵĶ�����������ٱ����ݣ��ñ���ȥ�����ݱ�ԭ�еĺÿ��ȵȡ� ��ô������Ҫ��ʲô�أ����������˽�һ��������һ���ؼ��У�����ʵ�����ľ��������ʲô���ӵģ���û�з��գ��Լ����˵���ǿ���һ������ķ�չ�������ܲ��ܸ���һЩ���飿 ���Ǵ����ķ����ǣ�ͨ��������ʵ���ݣ�ͨ����ȷ�ķ�����ȥ��֪����۵ľ����������ô��չ��Ȼ����Ԥ����ܵķ��ա� �ٸ����ӡ����Ƕ�300���ؼ��н��о��������յļ�⡣���Dz��ٿ�����GDP��PPI��CPI��Щ�������ռ���һЩ�ܹ���һʱ�䷴Ӧһ�����б仯�����ݡ����ȣ����Ǵӹ�������վ�������������еĺ��ա���·��·�˿�������ֻ����ʮ��������й�·�˿�������������ֻ�к��պ���·���˿���������Ҳ�����ж��������ɻ���������Щ���С����������Щ����ע��Ĺ�˾��Ƹ��ְλ��Ŀ��ְλ���ͺ�н��ˮƽ���ٴ���������Щ���е���Ϣ���ͿƼ�����ˮƽ���������ң�����ݹ۲���Щ�������ڽ��е��ش�����Ŀ������������û���˺ͳ���Ƶ���˶����ر���û�з����仯���Ӷ��ƶ���Щ��Ŀ�Ƿ��������С� �����ܹ��ڵ�һʱ���õ�һ����Щ���ݡ�������Щ���ݣ�����������ȥ����Щ������û�п��ܵ��ش���ա� �Ҹ���Ҿ�һ���ر�������������ӣ������������˹�����ij��г��ֵ����⡣������˹������ʲô�����أ�����֪������2013�꣬����ϡ����ú̿�۸�Ĵ�����½���ʹ��ԭ�������ٷ�չ�Ķ�����˹����ʱ������˹һ�����еľ��ó�����ͷ�����ͺ��ص��ܺͣ��ľ���Ѹ���»����ܶཨ���¥�������˿�¥������ȫ�������ġ����ǡ��� ������ôȥ������һ�������أ����Ƿ����������ܼ�������һ������Ϣ���̶ȣ����ݾ�����������ж���������IP�����統�������������ɵȣ�����һ������������������˶����г�ռ��Ȩ�����¡�ר���ȣ��������������ĿƼ����������� ���ͼ�оͺ�����˼�����ȿ�Aͼ����������һ�����е��û�����������������GDP��09����ǰ���й�һ����295���ؼ��У�������293�������ļ�¼���ݡ�������ͼ�ϣ����ǿ���GDP����Ϣ�������dz�����صġ�ͨ�����Իع飬������ϳ�һ���ߣ�б�ʴ��Ϊ0.93��ˮƽ�����Ϻ������ƶ������ߣ������������ع��ߵģ������쳣�ij��У����������˹���������������������ǵ���Ϣ��ˮƽ���ߣ����Ǿ���ˮƽԶ���ڶ�Ӧ��Ϣ��ˮƽ��������Щ������2013��ʹ����������ϵ�����������Щ������һ����ͬ���ص㣬���Ƕ��Ǹ߶���Դ�����ͣ����������˹������ϡ����Դ�ȽϷḻ�� ����֪�����ھ���ѧ���棬���Ϸ�չ10%�����µ�10%����ȫ��һ���ġ�������ٷ�չʱ���ܶ���ڻ���������Ͷ�ʡ�������������µ�ʱ���ܶ��˶�����˴��ˡ����ˣ�Ȼ������ЧӦ����������Σ����������ػ���ԭ����һ������Ͷ�ʣ�������Ϣ����ʱ������Ҫ��һ�����еľ�����������ǰ����ķ�չ�������ǰ��Ҳ�����ˣ�������˹�����ij���13��֮ǰ�����������ͷ�չ���ܺã�����ͨ�����ǵķ����Ϳ��Է��֣���ʵ�����ķ��պܴ����Ը��������ʱ�����Ҫ����һЩ�� ��������������һ�����ڰ��������ӡ����Ǵ�����������8000���������ݣ�����˵���ǣ�����ʲô�����˻ᵽʲô������ҵȥ��������һ�����ݡ���������580�����ҵ���й�ֻ��82����ҵ����ͼ��ÿһ����ɫ����һ����ҵ���࣬�����20������Щ��ϸ��Ϊ500�����ҵ��600������֡����ǽ�һ��ͼ��ÿ���ڵ㶼��һ��600��ά��vector��������������Щ�����еķֲ���Ȼ�����Ǽ���ÿ����vector֮���cosֵ����ʾ����س̶ȡ�ͼ��ÿ��node�Ĵ�С��ʾ����������������ı��ء� ����ͨ������������ͼ��������Щ��ҵ֮��Ĺ�ϵ��Ϊ���������Ȼ����������ҵ����кܶ�취��cosֵֻ������һ�֣�����֪�������������ҵ�������ô���Ǻ��п��ܻ��й�ͬ�ľ���Ԫ�أ��ˡ���Դ���������ִ��ȣ����ڷ�չ�����п��ܻ���Эͬ���á����ͼ��������һ�������ܼ��ͽṹ�� �ڲ�ҵ��չ�����У����Ƿ�����һЩ�ص㣬�����������������learning trace��һ����inter-industry learning illustration��Ҳ������ A ��ҵ����IJ�ҵ��չ�Ķ��ܺ�ʱ����ô A ��ҵҲ���п��ܷ�չ�úܺã�������ʱ�����Ͷ��A��ҵ�ͺ����׳ɹ��� ��һ����inter-regional learning illustration����˼���ǣ��������Χ��ʡA��ҵ��չ�ıȽϺã����ҵ�A��ҵ��չһ��㣬��ô��Χʡ��A��ҵ�ͻ�����ҵ�A��ҵ�ķ�չ�� ����ͼ��˵���������������������������ҵ/�����Ļ�ܶȣ����������²�ҵ/������óɹ���չ�ļ��ʡ�ͼ���ұߵ���ͼ�ǽ�����ͼ����������� ������������ڰ������й�Ҳ���������й�ֻ��82����ҵ���࣬���ݱȽϲң��������Ϻ���չ���������ܱߵĺ��ݡ����ݡ�������Ҳ����̷�չ�����ˣ���㷢չ����������ݸ����ҵ�����ǡ����������⣩�� ���Ǵ�92�굽16�걱��/�ӱ����Ϻ�/�㽭�IJ�ҵ�ֲ�ͼ����ͼ�����ǿ��Կ����������в�ҵ�ı仯�� ���ڽ�ѧϰ���棬�й�������û�а�����ô�ã�������Ȼ�ܹ����������Ĺ��ɡ�����ܱ�ʡ�ݷ�չ�ıȽϺã���ô��һ��ʡ��Ҳ�ᷢչ�ȽϺã����ž���ļ�С�����ǵĹ�ҵ������Ҳ������ �������Щ���ڴ����ݺ�ͳ��ѧ�ķ��������Ǿͷ��֣���ͬ�ij����ڲ�ͬ�ķ�չ�����ϣ�Ͷ��Ӧ����ѭһ�����Ż����ԡ������ҽ��ĵ�һ�����ӣ����������ú���������ȥ��֪����չ����״�������÷�չ�ṩһ���ɶ����������IJ��ԡ� �����������ѧ ����ѧ�����Ӿ��ǣ�������ôͨ����Ϊ������ʵ��Ԥ���Թ���������Ҫ����һ���������ȥ����һ��ѧ���Ƿ����ش����⡣ ��ѧҵ�нϴ�Ӱ��������кܶ࣬��������״�������̡�DNA���˸���Ϊ�ȡ�������Ҫ��ע�˸����Ϊ����Ϊ�����ǿ��Ը�Ԥ�͵����ġ���ǰ���Ƕ���Щ������о�ֻ����ͨ�������ʾ�����ʽ��ü�ʮ�����ٵ��������������ڼ��������������ܹ���ú��������ݣ�����ͨ�������ֻ���mooc����wifi�ȡ� �����õ���ѧ��У��ʹ����������ݣ����Ǹ�����Щ�����ܹ�֪��ѧ����ѧУ���ˮ���Է���ϴ�裨ʱ�䣩��ȥͼ��ݡ�����ȵȵ��������������18960������ѧ���Ĵ��3000�����¼���ݡ� �����ȿ����������ӡ� һ������orderness������������Ƿ��й��ɡ���������ʵ��������orderness��Aͼ��18960��ѧ��ϴ�裨ʱ�䣩�����ݡ����ǿ���orderness����ǰ5%��ѧ��������ɫ��������dz����ɣ�������ֻ������9��ϴ�裻����5%��ѧ����dz��ɫ���������0-6�㣨���ò����ţ���һ�쵱���κ�ʱ����ȥϴ�衣Bͼ���dzԷ������ǰ5%����ɫ�������϶�����������Է�������5%���ٻ�ɫ���������һ�쵱���κ�ʱ����ȥʳ��ˢ������������û���κι��ɡ� ˵��һ�£���������֮��������ʵ�أ���������ũ�ػ���Simpson�أ�����Ϊ���Dz���Ҫ���ֲ��ļ����ԣ���Ҫ���ֲ��Ƿ���˳������Է���������硢�С����Ͷ��У���û�м�ϣ�����ʵ���ǿ��Կ������еĹ����ԡ� ����ͼҲ�Ǹ���18960��ѧ�����ݵķ������ұ����ź��������⣬ѧϰ��Ŭ���̶ȣ��õ��ǽ���ͼ��ݵ����������㣩��GPA�Ǹ߶�����صġ�һ������˼�ķ����ǣ�����Ĺ�����Ҳ��GPA������أ�Ҳ����˵����Խ���ɣ�ѧϰ�ɼ���Խ�á� ֵ��˵�������ڷ̶ܳȺ������orderness����ȫ����صġ�����ǰ�����������صĹ�������ȫ�����ġ� ���ڴˣ���������һ���dz�����˼��������ǣ��쳣��������ɫ���dzɼ��½�����ɫ���dzɼ����������Ƿ��ֳɼ��½�����Ϊ�Ĺ����Ƿdz�ǿ�ģ����ɼ�������һ�������仰˵����Ϯ��̫���ף���ʹ���������ڷ�ѧϰ���ɼ�Ҳ��һ���������������������������ǹܲ��ˣ��������ǿ���ͨ������쳣��Ϊ��Ԥ���´ο�����ijɼ��Ƿ���»������磬��֮ǰÿ��ȥ30��ͼ��ݣ�����¾�ȥ��һ�Σ���ô�϶������⡣������20������Ƶ��쳣��������Ȼ�����õ��������������ģ�����ÿ������Ա��֪����Լ100��ѧ���������ݺ�ѧ�ŵĶ�Ӧ������������ش��쳣��������������û��ˢ����¼��������ͻ��Զ�����ĸ���Ա��һ��֪ͨ�����dz�֮Ϊʧ��Ԥ���� ���������˵��������Ϊ���ݣ��ر���orderness���ݣ����ڷ̶ܳ����ݽ������ʹ�ã��ܹ���߶�ѧ��ѧϰ�ɼ���Ԥ���ԡ� �����������ѧ ���һ��������������big data���ڽ��������֯ģʽ���о�������ʱ��ԭ���Ҿͼؽ���һ�¡���������һ���¾����������������������ڽ�����ķ�������Ȼ�������漰���������ı��������Ͳ��پ���˵�ˡ����ǿ�һ����Щ�ڽ�����ô��֯�ġ� �����й����ڽ������ϵ����ͬ����ɫ�����˲�ͬ���ڽ̡��������ľ�Ȼ�ǻ����̣����ռһ�����ң����ռ40%���ң��������̺���˹���̴��ռ10%���ҡ����ǿ������ڽ����ڽ�֮��Ҳ������ϵ�ģ���Ƿ�˿���������������ڽ���������һ���dz����ص�һ����ǣ������Ƿdz�highly, highly, highly��strong, strong, strong���ڹ����ġ�strong��ʲô�̶��أ����������Newman��Mixing Patternǿ�ȣ�����0.987�������������罻�����������������������͵��Ĺ�ϵ����ͬ����֮��Ĺ�ϵ����Щ���붼�Ȳ����ڽ̡��ڽ̶��ڷdz����ۣ�������������ӣ���Щ��������/���͵����Ȳ�ͬ����֮��ķ��뻹Ҫ���ء��������ǵ�һ���Ƚϴ�ķ��֣����ڽ̴����ĸ���ͷ��룬��ʵ���Ǹ������֡����ڷ�ɫ�������������������ڹ��ҵġ� �ڶ��������ǣ���Ȼ�������ô��������ô��Խ�ڽ̵�����������ô�����أ�ͨ������ͼ���ǿ�������Խ�ڽ̵�������ʵ���٣���������ԣ������Ȼû�л������˶࣬�������ڲ�ͬ���ڽ������˱�����ͨ�Ե����ã�ͨ���ı����������Ƿ��ְٷ�֮�߰�ʮ�ı�����ͨ�ı߶��������Ƶı�ǩ������һ���dz���Ҫ����Ϣ�� ����һ���dz�����˼����Ϣ�ǣ����������Dz�֪������֮���Ƿ��Dz�ͬ�ڽ̣�Ȼ��ͨ����ȥ����Щ�����о����ǵ���Ҫ�ԡ����Ƿ���������ա��ȡ��ķ�ʽ��ȥ����Щ�ߣ���ʵ�Ͼ���ȥ���ڽ��ڲ������ӣ���������û�����ģ���������ա�bridgeness���Ĵ�С��bridgeness�Ĵ�С�����˹�ͨ��ͬ����֮�����������ȥ����Щ�ߣ���ô�ڲ�ͬ��ʱ������������䣻�����ա�betweenness���Ĵ�С����˵�����ָ�������һ���ڵ���Ϊý���������Ҳ����ռ�������������ڵ����·��������Ҫ�Ľڵ㣬������ܾ���ͨ��Ϣ�����������ڵ������ͨ��ռ��������λ��Խ�࣬�����н��Ծ�Խ������ȥ����Щ�ߣ���ô��������ܿ�ͱ����ˡ�ͬ�����������cross link���Ĵ�С�����Ӳ�ͬ�����������������ȥ���ߣ����������ͱ����� ��˵�������������ں��Ժ���ͨ�ԣ��ǿ�����Щ���ڽ̵�����ʵ�֡����ھ�������أ�����Ҫͨ���ı���������Щ���ڽ̵����ӵ�������Դ��ʲô���Ĺ�ͬ��Ȥ�����ԡ� �ܽ� �����ҽ�������������˵�������ݡ��˹����ܵ��о��ھ���ѧ������ѧ�����ѧ�е�Ӧ�á������һ��������ǣ�����һ���dz�ǿ�ҵĸо������ѧ������ѧ���Ѿ������پޱ䣻�����ʱ���ڷ����ޱ��ʱ����һ��Ҫվ�ں����ײ���һЩ��ɹ��ĵط���������ǿ�ҽ��飬��Ҷ����ѧ������ѧҪ�б����� ���� �ʣ�������α����Լ�����˽��������˾�������������ֲ���֯�����ã� ���Σ��������ܺá��ҵ��ж��ǣ������DZ��������Լ���˽�ġ����Ը��˾Ͳ�Ҫ�����������ͼ������Ҫ�����������ǹ���ͨ�������簲ȫ�����Լ����̷����ڶ����������Ľ��ͣ�ȷ����˾����ҵȥ���������˽��һ�ַ�ʽ���������ɼ������˽���ڶ����Dzɼ���֮���������٣������־�������Ȩ���ɼ������ɼ���֮��ֻ���ںܾ��ĵط���������Ӱ����ĸ�����˽�������������˺��� ��������Ӧ��������ȥͨ��������Լ������ҵȥ���������˽��������ͼ��������ͼ�����Լ�����˽����ȫ�����ܵģ�Ҳû���κμ�ֵ�����磬ֻҪ���������ţ��ڱ���������۶���֪����Ĺ켣���㻹�ܲ��Ͻ֣����û����̵�˳��ԭ���������̶����õ��������Լ�������˽�����Dz�̫���ܵ��¡����Ի����������ù�˾��̧���֣����ַ������˽�� ������ǣ�ƽ�����˻ᱻ�����ø��á�����iPhone�������ܶ�Ů���ǵ����վͱ��ϴ��ˣ���ͬʱ�ܶ�����������������Ƭ��û�б��ϴ���������Ϊ����̫ƽ�������ڿͶ���ȥ��ע�� ��Ϊƽ��������ȫ��
| 

 /1
/1 

 |������������
|������������
 ������ 2017-9-28 10:57:54
������ 2017-9-28 10:57:54











 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������