����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
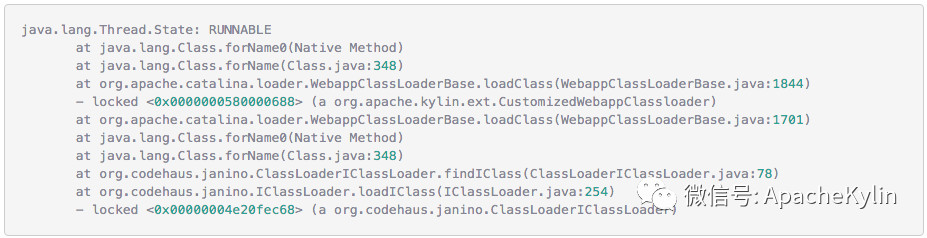
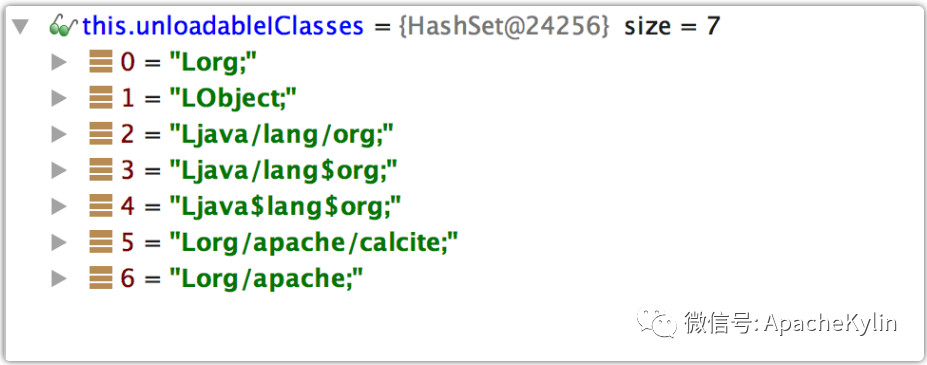
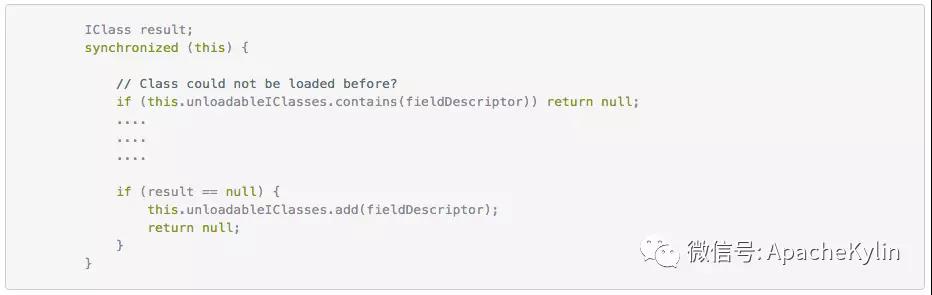
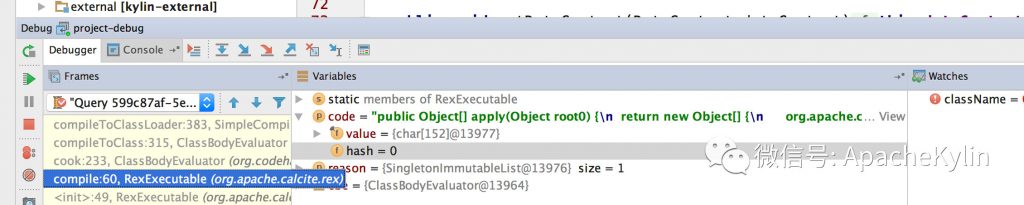
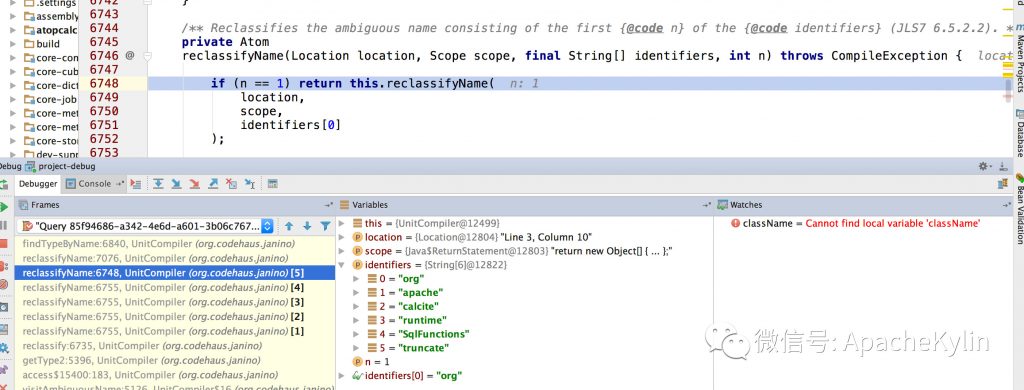
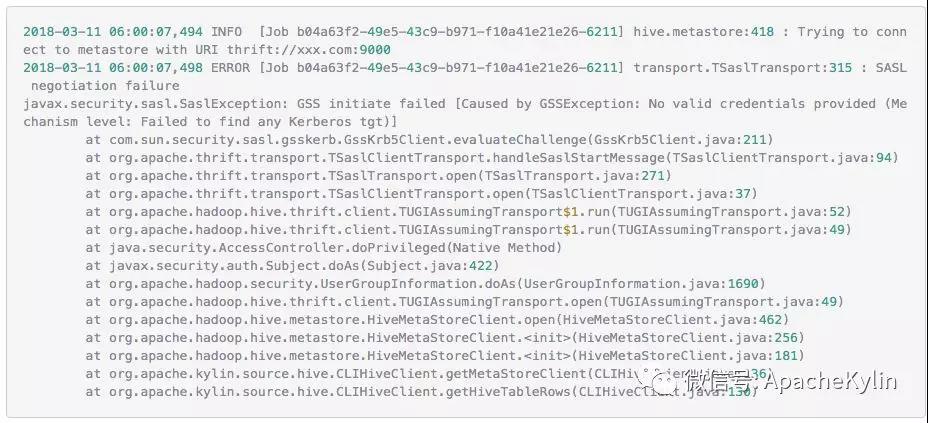
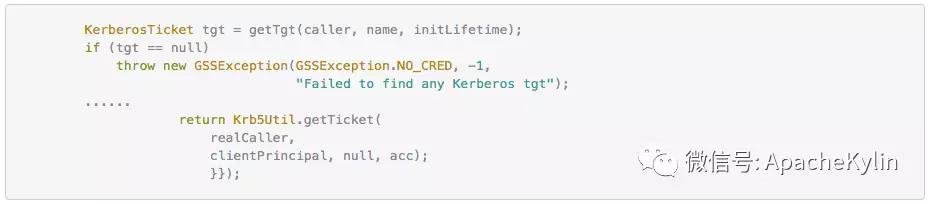
���ߣ�����ɭ ���� 4��9�ŵ�ʱ������һ�����϶�����ѯ��Ⱥ�յ� Http ����500�쳣�ı������û�Ҳ������ѯ���س�ʱ�� ��ʱ���ȿ����¼�ص� Dashboard,���� Kylin QueryServer ������ָ���쳣���ߣ� Kylin.TomcatRequest.processingTime �����ڴ棬CPU ʹ��������GC ���Ҳ������˵�����dz����Ĵ��ѯ����� OOM��֮���Ҿ͵�¼���ϻ��������ֺ�ʱ20����IJ�ѯ���� HBase �ܿ죬ֻ�м� ms�����ǣ� �� service.QueryService:356 �� routing.QueryRouter:56 ֮�� �����ʱ21s�����������ľ���������Ӧ���� Calcite �������⡣���Ǿ������� Jstack���������������ָ����� Jstack ���� ���� Jstack ���֣������߳� Block �� WebappClassLoaderBase loadClass �ĵط��� ����0x0000000580000688�� RUNNABLE ���̳߳��� grep ���·��֣��ȴ�0x0000000580000688��������߳���93��֮�ࡣ �������ڲ�ѯ�߳� blocked ��ԭ���ҵ��ˣ�����Ϊʲô���д����IJ�ѯ�߳���Ҫ loadClass��loadClass Ϊʲô��ʱ�ܾû�������� ��ʱ�ȸ���һ�£��ҵ��������Ƚ���ص����⣺ https://issues.apache.org/jira/browse/CALCITE-1885 https://issues.apache.org/jira/browse/WW-3902 ���������� Jira�����ж�����ܴ���ܺ� Calcite �й�ϵ�� ���������ǵ�һ������������⣬��������������һ��������ͬʱ�������������ѯ��Ⱥ����û�з�����������⣬�����Ҹо�������ⴥ���ĸ���Ӧ�úܵͣ�ͬʱ���ǵ���ʹ������������Ҳ���Կ��ٻָ����Ͳ����������⣬��Ϊ�������ȼ��ܸߵ�����ܶࡣ ���⸴�� ����4��11����������ֳ����ˣ�˵�����ⲻ��һ�������¼�������Ϊʲôֻ��һ����ѯ��Ⱥ����������أ���ʼ�����Dz����û��� SQL �����ʲô�Ķ������������������������⣬���Ǻ��û�ȷ�Ϻ�SQL �����û�иĶ��� ��Ҳ�����˶�������߳������� SQL��ʮ�ּ���û��ʲô�ر�ĵط��� ���Ǵ� WW-3902 �����Ʋ��������ܿ��ܺͲ����йء� ���������������֪��ʵì�ܵĵط��� 1�������ѯ��Ⱥ�IJ��������Ǻܸߣ�QPS ���ֻ��3�� 2����֮ǰר��ѹ��� Kylin��Kylin�ڸ߲������������� Calcite �Ĵ������ɵ�ȷ�������Ե������½��������ڲ���30��ʱҲû�г����߳������� ���ǵ�ʱҲû��������������ĺ�˼·�����Ի��Ǿ��������²�����ᵼ��������⡣ ������32�IJ���ͬʱִ������� SQL���Ƚ����ˣ�����ֱ�Ӹ����ˡ� LoadClass ԭ����ȷ ���������Ѿ�ȷ������������ڸ߲�������� WebappClassLoaderBase loadClass ���������µġ��������������֮ǰ��������Ҫ����ȷ�� WebappClassLoaderBase ��ԭ����loadClass ʲôʱ����Ҫͬ���� Kylin ��ʹ�õ���������� CustomizedWebappClassloader: CustomizedWebappClassloader �̳��� ParallelWebappClassLoader��ParallelWebappClassLoader �̳��� WebappClassLoaderBase��WebappClassLoaderBase �̳��� ClassLoader�� ParallelWebappClassLoader ��һ�����������������ԭ����ͨ������ Classloader.registerAsParallelCapable �����������ء�����������ͬ�� Class �Ϳ��Բ������أ�ֻ��������ͬ�� Class ����Ҫͬ���� ͬʱ WebappClassLoaderBase ������������£� ��������֪��һ��Ӧ�ó�����1����ֻ�����һ�Σ��ڶ��μ���ʱ��� Cache �м��ء� ���Է��� ���� LoadClass ��ԭ��������֪�������ѯ�߳�������ԭ��Ӧ���Ƕ����ѯ�߳���Ҫȥ����ͬһ���࣬���������Ӧ�ü��صıȽ����� ���Ǿ;��������´��룬ͬʱ���ǵ��ܴ���ʺ� Calcite �Ĵ��������й�ϵ���ͽ� calcite.debug ����Ϊ true�� ���� Jstack �ļ������Ƚ��ϵ����õ� WebappClassLoaderBase ��1844�С���Ϊ����ʼ����ʱ��Ҫ���ص���϶��ܶ࣬������������һ������� SQL ����ʽ���� debug�� debug �����з��ֻ��μ��� org,Object,org/apache ����������������������Ȼ�Dz����ڵģ�����ȷ���أ����Ǹ��ݶ�ջ������������Щ���� UnitCompiler.findTypeByName �в����ģ��������� IClassLoader loadClass �������£�IClassLoader �ж������ص������ Cache unloadableIClasses�� �� unloadableIClasses ���������£� ��Ȼ�� Cache����Щ��Ӧ���� WebappClassLoaderBase ֻ�����һ�Σ����� debug �з��� org ���������ֶ�Ρ�˵����� Cache ����ȫ�ֵģ��ٷ��� Jstack���²���Ӧ����ÿ�� UnitCompiler ����һ���� ��ʱ����ȥ������� SQL ��Ӧ�� Calcite ���ɵĴ��룬�����˴����ģ� ��ʱ�� UnitCompiler������ apply ����Ƭ�Σ� Integer.toString(xxx) �⼸�����أ������Ժ������뵽����Ī���Ǻ����������йأ������� Kylin web ��ȷ������ SQL �� id �� price �����ͣ���ȷ�� String�������ҾͰ� SQL �е� Int �ij��� String����32�IJ����������£���Ȼû�����߳�����������ÿ����ѯ�ĺ�ʱ��֮ǰ���̡� ���ˣ��������������ԭ���Ѿ���ȷ��ͬʱ���˽�������� �ղ� apply ����� UnitCompiler �й�ֻ�ǴӴ��������Ͷ�ջ�ϵIJ²⣬֮���ڴ�����Ҳȷ�����£�ÿ������Ƭ�ε�ȷ��Ӧһ�� UnitCompiler�� ������еĵ��������£� ���ﻹ��һ�����⣬Ϊʲô Calcite ����� org,Object,org/apache ��������ֵģ��������ڵ������� ����ͼ��Ӧ���� UnitCompiler �� reclassifyName(Location location, Scope scope, final String[] identifiers, int n)���� reclassifyName(Location location, Scope scope, final String identifier) ��������� Bug������ org.apache.calcite.runtime.SqlFunctions.truncate ���������UnitCompiler �ᵱ��6�� identifier��Ȼ��ݹ���� reclassifyName ��������������Ȼ org��org.apache��org.apache.calcite �����ǺϷ��������� �������� 1��Table �е� id �� dt_name ���� String ���ͣ������� SQL ���û�д���� Int 2��SQL �д����� In ���� Calcite ���ɵĴ����д����� Integer.toString ����Ƭ�� 3��UnitCompiler �ڱ������Ƭ��ʱ�����ɽ϶�Ϸ������� 4�����ڲ��Ϸ�������ÿ�ζ���Ҫ���أ�1�� SQL ������30���(��������)����Ƭ�Σ����ϲ������ͻ������ͬ���������ڼ���ʱ��������һ����һ�δ��������ˣ��ͻ��γɶ���ѭ����������Խ��Խ���أ������γ�90�����ѯ�߳� Blocked ���������ɲ�ѯ�����á� Kylin �� SQL �������͵���Ҫ�� 1��SQL ���������ͺ�ʵ�����Ͳ�һ�£��ڲ�������º������� Kylin QueryServer ������ѯ�߳� Blocked���������²�ѯ�����á� 2��SQL ���������ͺ�ʵ������һ�£��Ȳ�һ��ʱ�������������������������������پͿ� HBase ����ʱ��� Kylin QueryServer ����ʱ���ռ�ȣ����� HBase �Ĵ���ʱ���ڼ�ʮ�������ң���ѯʱ��Ӧ�ÿ�������һ�����������Ӽ������������ٺ��룩 ����Ų�ͽ������ ���Ǽ��������ʦ��ƽʱ��Ȼ�������ܶ�����ϣ�����������Ҫ����������Ҹ�����������һЩ����ľ�����dz̸�����ǽ������ij���˼·���ֶΣ����ʱ��Ƚ϶̣����Ǻ����ƣ� 1.ȷ����ʵ�Ĵ������Ԥ�ڵĴ�������ȫһ�µ� ���Ŵ�Ҷ������������˴�������⣬���շ��ִ���û���µ������ Ԥ��������������ڴ���ֿ���߷���ϵͳ���м��� Commit �ţ��������ǾͿ��Կ����ж����ǵĴ���汾�Ƿ���ȷ�����������ʩֻ�ܱ�֤���ǵ�ǰϵͳ�Ĵ�����û������ģ������ܱ�֤����ϵͳ����������ϵͳ����Ҳ�����µġ� ���磺���ڿ��� Kylin On Druid POC ʱ����Ҫ���� Druid ���룬���������ǹ�˾ Maven �ֿ⣬Ȼ���ٱ��� Kylin ������з����� ��ʼ����ʱ�ҷ��ָĵ� Druid ������ Bug�����·��� Druid ����������±��뷢�� Kylin ���룬�����ҷ��ָ��º��������⣬��ʼ��һֱ��Ϊ���Ҹĵ� Druid �����������⣬����ȷ�ϼ��κ��뵽��ȷ���´��뵽���Dz������µġ� ��� Google �����ȷ��Maven ���� SNAPSHOT �������Ⲣ����֤ÿ�ζ��������°汾�ģ���Ҫ���� -U �������ܱ�֤ÿ��ʹ�����°汾�� 2.ȷ�Ϸ���Ļ����Ƿ���Ԥ�ڵģ���������ȷ�� ����Ļ�����������ϵͳ�汾�����IJ�����JDK �汾������������������ Jar ���ȡ� ����������Dz���Ҫȷ�����ñ���û���⣬��Ҫȷ�������õ����ȼ������õ����ú���Ч��Χ�����û���������ϵͳ�����ã��� Kylin ��������ϵͳ�Ļ�����Ҫ���� HBase��hadoop��Hive��Spark �ȵ����á� ���磺��ȥ���ڸ� Kylin �����Ǩ��ʱ�������� Kylin Spark Cubing ִ��ʧ�ܵ����������Ų飬ȷ���� Kylin ������ bug����������� Bug �����ؾ��ǻ��������õı仯�� ������Բο� KYLIN-2995�� https://issues.apache.org/jira/browse/KYLIN-2995 3.�������� �ܶ�ʱ�����������ķ����ò������������ɱ�������ģ�һ���������ڲ������ı������������⣬�������ⲿ�ı��������������ڲ��� Bug�� �����ڷ�������ʱ������Ӧ��ȷ���ڲ����ⲿ�ı������������Ǵ��������Щ�ط����û��IJ�ѯģʽ��ʲô�仯�����������Ļ�������������Ļ�����ʲô���𣩣�Ȼ���ٷ���ȷ��ÿ�������Dz��ǵ������Ǵ˴���������ء��ܶ�ʱ������һ�������ǾͿ����ҳ������ԭ�� ����������� Case �ı��������û��� SQL �������ͣ��������Ҳ�Ǵ��� Calcite Bug �����أ���������������ѯ��Ⱥ��û�з�����������⣬ 4.�����ֳ� ��Щ��������ķ�������żȻ�Ժͱ������������Ϸ��������⣬���DZ������ϻָ�����һ�㲻�������������⣬�������DZ��뱣���ֳ��� ��Щ�ֳ��������Ƶļ��ָ�꣺���������ͷ������ļ�أ�Thead dump��Heap dump��Core Dump���ؼ��� Log �ȡ� �������е���� Case �ķ��������������˼��ָ��� Thead dump�� �������ü��ָ��� Thead dump �����������ԭ���Ǵ����߳��� LoadClass ʱ Block���������̶߳�ջ�����жϳ�������ܺ� Calcite �йء� 5.��������������Ҫ�ı���������֪ʶ ����������������������ǽ��д���ʱ�����DZ�Ȼ��Ҫ��ȷ���������ص������������������漰�ĸ���漰��ϵͳԭ��������ԭ�����������ǿ��٣���ȷ�ķ������⣬����äĿ������·�� �������е���� Case ���Ǿ�Ӧ����ȷ Tomcat ����ص����Ǵ��л��Dz��У���ʲô���ȵIJ��С� �پٸ����ӡ� �ڽ��� Kylin On Druid ����ʱ���ҷ��� Druid �� Segment Load �� Druid ʱ������� ���ʱ����Ҫȥ�Ż� Druid Segment Load ���ٶȣ��ͱ������ȸ���� Druid �� Coordinator ��ô֪������ Segment �����ˣ�Druid �� Coordinator ��ûᴦ��һ�� Segment Load��Druid �� Coordinator ��κ� Historical �ڵ㽻���� Historical Load Segment ������ �ٷ��IJ��� Load ����Ϊ�β���Ч��ʵ���Ǵ��� Load���� ֻ����Щ������ȷ���Ҳſ��Խ����Ż��� 6.�������� �������ų��˴������أ��������أ��������أ���������֮��������ص�ԭ��Ҳ��ȷ�ˣ����ǿ������ȳ���ȥ�������⣬��Ϊ����������ͨ��ij�ַ�ʽ�ȶ����ֵĻ�����ô����������ֵ����ػ�����ȷ���ˣ����ǾͿ��Կ�ʼͨ�������ֶη��������� 7.Debug ���������Ƚϸ��ӣ����߿�������ôҲ����������ʱ��������ϵͳ�����ĵ�����ϵͳ������ʱ debug ������Ƚ����á����� Case ��ԭ����ȷ��Ҫ���ľ��� debug��һ����� Kylin ��ѯ����ʱ��debug ʮ�����ã����� Kylin ��ѯ������һ�� debug �����Խ���� 8. Log ������Ҫ����һЩ��ʱ����������ֱ�� debug ʱ������ Hadoop ��Ⱥ�����е� MR Job�������ǾͿ���ֱ�Ӽ�Щ log���������ǿ��ٷ����� 9.ֱ�Ӹ����쳣�������д������ ��ʱ�����ǵ�ϵͳ���׳�һЩ������ϵͳ�����ص��쳣�����ʱ�����ǿ��Գ����´��쳣�����������������쳣������ԭ�� ���磬ǰһ��������̨ Kylin �� JobServer ÿ��24Сʱ�ͻ���ַ��� Hive MetaStore Kerberos ��֤ʧ�ܵ����⣬�������� JobServer ��û�����⡣���Ǹ��� Kerberos ��ͬѧ���˼���Ҳû�鵽ʲôԭ�� ǰ�����Ҿ;���һ�£�������һ��ʼҲûʲô��˼·���Ҿ;����ȿ� JDK8 ��Դ�룬����ȷ������쳣��ֱ��ԭ����ʲô��ͨ���� JDK8 ��Դ�룬������ȷ����쳣��ֱ��ԭ���ǻ�ȡ�� Ticket �� null: Ȼ���ٴ����ַ���Krb5Util.getTicket�����ȳ��Դӵ�ǰAccessControlContext��Subject�л�ȡticket�����ticket��null��javax.security.auth.useSubjectCredsOnly��false�����ͨ��HadoopLoginModule���µ�¼�ķ�ʽ����ȡSubject�������⣬���Ƕ���һ�����ԵĻ��ᡣ ��������ͨ������ javax.security.auth.useSubjectCredsOnly Ϊ false ������������ 10.������ �����ڸ�������ʱһ��Ҫͷ����������������������ط������ƶϣ��ۺ������ۺϷ��ͷ���������Ϊһ�������ٸ��ӣ����Ƕ����Բ��ϲ�⣬����ƽ���ֱ��������Ϥ����֪���⣻ͬʱ������������������֮�䶼�й����������ڷ�������ʱ��ҲҪע�������������صĹ����ԡ� �ܽ� ����ͨ��һ�������¹ʵķ������̣�˵���� Apache Kylin �� SQL �������͵���Ҫ�ԣ������ܽ�������������Ų�ͽ�����⡣
| 
 /1
/1 

 |������������
|������������
 ������ 2018-11-9 10:21:32
������ 2018-11-9 10:21:32







 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������