����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
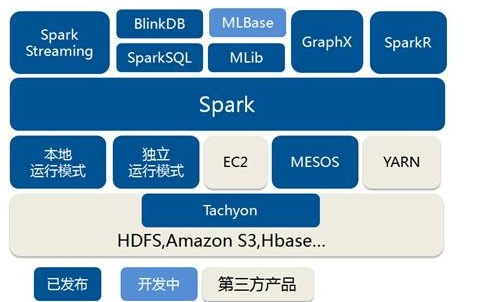
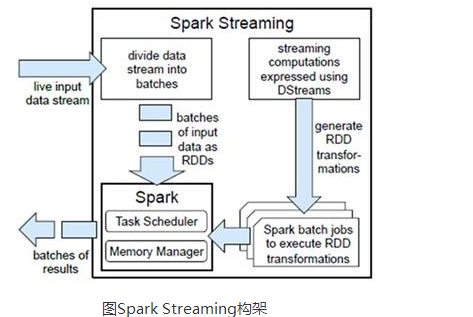
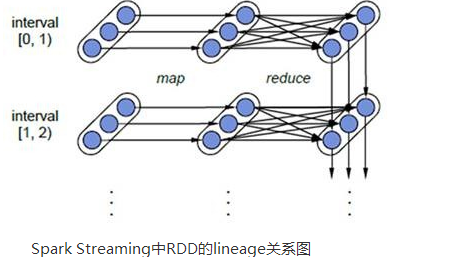
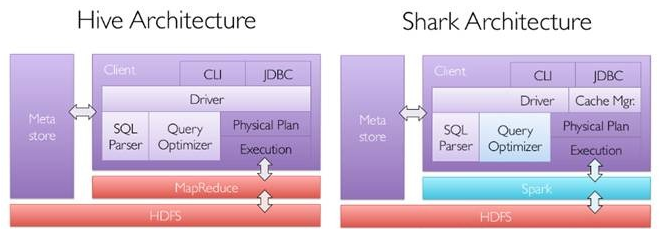
Spark��̬ȦҲ��ΪBDAS�����������ݷ���ջ�����Dz�����APMLabʵ���Ҵ���ģ���ͼ���㷨��Algorithms����������Machines�����ˣ�People��֮��ͨ�����ģ������չ��������Ӧ�õ�һ��ƽ̨��������AMPLab���ô����ݡ��Ƽ��㡢ͨ�ŵȸ�����Դ�Լ��������ļ����������Ժ������������ݽ������ת��Ϊ���õ���Ϣ���Թ����Ǹ��õ��������硣����̬Ȧ�Ѿ��漰������ѧϰ�������ھ����ݿ⡢��Ϣ��������Ȼ���Դ���������ʶ��ȶ������ Spark��̬Ȧ��Spark CoreΪ���ģ���HDFS��Amazon S3��HBase�ȳ־ò��ȡ���ݣ���MESS��YARN������Я����StandaloneΪ��Դ����������Job���SparkӦ�ó���ļ��㡣 ��ЩӦ�ó�����������ڲ�ͬ���������Spark Shell/Spark Submit����������Spark Streaming��ʵʱ����Ӧ�á�Spark SQL�ļ�ϯ��ѯ��BlinkDB��Ȩ���ѯ��MLlib/MLbase�Ļ���ѧϰ��GraphX��ͼ������SparkR����ѧ����ȡ� spark�ĺ������ Spark Coreǰ�������Spark Core�Ļ�������������ܽ�һ��Spark�ں˼ܹ��� l �ṩ��������ͼ��DAG���ķֲ�ʽ���м����ܣ����ṩCache������֧�ֶ�ε�������������ݹ����������ٵ�������֮���ȡ���ݾֵĿ������������Ҫ���ж�ε����������ھ�ͷ��������кܴ����� l ��Spark��������RDD (Resilient Distributed Dataset) �ij������Ƿֲ���һ��ڵ��е�ֻ�����ϣ���Щ�����ǵ��Եģ�������ݼ�һ���ֶ�ʧ������Ը��ݡ�Ѫͳ�������ǽ����ؽ�����֤�����ݵĸ��ݴ��ԣ� l �ƶ���������ƶ����ݣ�RDD Partition���Ծͽ���ȡ�ֲ�ʽ�ļ�ϵͳ�е����ݿ鵽�����ڵ��ڴ��н��м��� l ʹ�ö��̳߳�ģ��������task�������� l �����ݴ��ġ��߿������Ե�akka��ΪͨѶ��� 2.2 SparkStreamingSparkStreaming��һ����ʵʱ���������и�ͨ�����ݴ���������ʽ����ϵͳ�����ԶԶ�������Դ����Kdfka��Flume��Twitter��Zero��TCP ���֣���������Map��Reduce��Join�ȸ��Ӳ���������������浽�ⲿ�ļ�ϵͳ�����ݿ��Ӧ�õ�ʵʱ�DZ��̡� Spark Streaming���� l�������̣�Spark Streaming�ǽ���ʽ����ֽ��һϵ�ж�С����������ҵ�������������������Spark Core��Ҳ���ǰ�Spark Streaming���������ݰ���batch size����1�룩�ֳ�һ��һ�ε����ݣ�Discretized Stream����ÿһ�����ݶ�ת����Spark�е�RDD��Resilient Distributed Dataset����Ȼ��Spark Streaming�ж�DStream��Transformation������Ϊ���Spark�ж�RDD��Transformation��������RDD������������м����������ڴ��С�������ʽ�������ҵ���������Զ��м�Ľ�����е��ӻ��ߴ洢���ⲿ�豸����ͼ��ʾ��Spark Streaming���������̡� �ݴ��ԣ�������ʽ������˵���ݴ���������Ҫ����������Ҫ��ȷһ��Spark��RDD���ݴ����ơ�ÿһ��RDD����һ�����ɱ�ķֲ�ʽ����������ݼ������¼��ȷ���ԵIJ����̳й�ϵ��lineage��������ֻҪ���������ǿ��ݴ��ģ���ô����һ��RDD�ķ�����Partition���������ã����ǿ�������ԭʼ��������ͨ��ת����������������ġ� ����Spark Streaming��˵����RDD�Ĵ��й�ϵ����ͼ��ʾ��ͼ�е�ÿһ����Բ�α�ʾһ��RDD����Բ���е�ÿ��Բ�δ���һ��RDD�е�һ��Partition��ͼ�е�ÿһ�еĶ��RDD��ʾһ��DStream��ͼ��������DStream������ÿһ�����һ��RDD���ʾÿһ��Batch Size���������м���RDD�����ǿ��Կ���ͼ�е�ÿһ��RDD����ͨ��lineage�����ӵģ�����Spark Streaming�������ݿ��������ڴ��̣�����HDFS����ݿ����������������������������Spark Streaming�Ὣ�����������ݵ�ÿһ���������������ݵ������Ļ��������ܱ�֤�ݴ��ԣ�����RDD�������Partition�����������Բ��е������������Ͻ�ȱʧ��Partition�������������ݴ��ָ���ʽ����������ģ�ͣ���Storm����Ч�ʸ��ߡ� ʵʱ�ԣ�����ʵʱ�Ե����ۣ���ǣ�浽��ʽ������ܵ�Ӧ�ó�����Spark Streaming����ʽ����ֽ�ɶ��Spark Job������ÿһ�����ݵĴ������ᾭ��Spark DAGͼ�ֽ��Լ�Spark�����ĵ��ȹ��̡�����Ŀǰ�汾��Spark Streaming���ԣ�����С��Batch Size��ѡȡ��0.5~2����֮�䣨StormĿǰ��С���ӳ���100ms���ң�������Spark Streaming�ܹ��������ʵʱ��Ҫ��dz��ߣ����Ƶʵʱ���ף�֮���������ʽʵʱ���㳡���� l��չ������������SparkĿǰ��EC2�����ܹ�������չ��100���ڵ㣨ÿ���ڵ�4Core����������������ӳٴ���6GB/s����������60M records/s������������Ҳ�����е�Storm��2��5����ͼ4��Berkeley����WordCount��Grep�������������IJ��ԣ���Grep��������У�Spark Streaming�е�ÿ���ڵ����������670k records/s����Storm��115k records/s�� Spark SQLShark��SparkSQL��ǰ������������3��ǰ���Ǹ�ʱ��Hive����˵��SQL on hadoop��Ψһѡ����SQL����ɿ���չ��MapReduce��ҵ������Hive�������Լ���Spark�ļ��ݣ�Shark��Ŀ�ɴ˶����� Shark��Hive on Spark����������ͨ��Hive��HQL��������HQL�����Spark�ϵ�RDD������Ȼ��ͨ��Hive��metadata��ȡ���ݿ���ı���Ϣ��ʵ��HDFS�ϵ����ݺ��ļ�������Shark��ȡ���ŵ�Spark�����㡣Shark��������Ծ��ǿ����Hive����ȫ���ݣ��ҿ�����shellģʽ��ʹ��rdd2sql()������API����HQL�õ��Ľ������������scala���������㣬֧���Լ���д�Ļ���ѧϰ�����������������HQL�����һ���������㡣 ��2014��7��1�յ�Spark Summit�ϣ�Databricks������ֹ��Shark�Ŀ��������ص�ŵ�Spark SQL�ϡ�Databricks��ʾ��Spark SQL������Shark���������ԣ��û����Դ�Shark 0.9��������������ڻ����ϣ�Databricks��ʾ��Shark�����Ƕ�Hive�ĸ��죬�滻��Hive������ִ�����棬��˻���һ���ܿ���ٶȡ�Ȼ�������ݺ��ӵ��ǣ�Shark�̳��˴�����Hive���룬��˸��Ż���ά�������˴������鷳�����������Ż����Ƚ��������ϵĽ�һ���������MapReduce��ƵIJ������ɳ�Ϊ��������Ŀ��ƿ������ˣ�Ϊ�˸��õķ�չ�����û��ṩһ�����õ����飬Databricks������ֹShark��Ŀ���Ӷ�������ľ����ŵ�Spark SQL�ϡ� Spark SQL����������Աֱ�Ӵ���RDD��ͬʱҲ�ɲ�ѯ������ Apache Hive�ϴ��ڵ��ⲿ���ݡ�Spark SQL��һ����Ҫ�ص������ܹ�ͳһ������ϵ����RDD��ʹ�ÿ�����Ա�������ɵ�ʹ��SQL��������ⲿ��ѯ��ͬʱ���и����ӵ����ݷ���������Spark SQL�⣬Michael��̸��Catalyst�Ż���ܣ�������Spark SQL�Զ��IJ�ѯ������ʹSQL����Ч��ִ�С� Spark SQL���ص�: l�������µ�RDD����SchemaRDD��������ͳ���ݿⶨ���һ��������SchemaRDD��SchemaRDD�ɶ��������������͵��ж��ɡ�SchemaRDD���Դ�RDDת��������Ҳ���Դ�Parquet�ļ����룬Ҳ����ʹ��HiveQL��Hive�л�ȡ�� l��Ƕ��Catalyst��ѯ�Ż���ܣ��ڰ�SQL��������ִ�мƻ�֮������Catalyst�����һЩ��ͽӿڣ�ִ����һЩ��ִ�мƻ��Ż��������RDD�ļ��� l��Ӧ�ó����п��Ի��ʹ�ò�ͬ��Դ�����ݣ�����Խ�����HiveQL�����ݺ�����SQL�����ݽ���Join������ Shark�ij���ʹ��SQL-on-Hadoop�����ܱ�Hive����10-100������ߣ� ��ô��������Hive�����ƣ�SparkSQL������������ô���ı����أ���Ȼû��Shark�����Hive������Ŀ��������������Ҳ���ֵ÷dz����졣 ΪʲôsparkSQL�����ܻ�õ���ô��������أ���ҪsparkSQL�����漸�������Ż��� 1. �ڴ��д洢��In-Memory Columnar Storage�� sparkSQL�ı��������ڴ��д洢���Dz���ԭ��̬��JVM����洢��ʽ�����Dz����ڴ��д洢�� 2. �ֽ������ɼ�����Bytecode Generation�� Spark1.1.0��Catalystģ���expressions������codegenģ�飬ʹ�ö�̬�ֽ������ɼ�������ƥ��ı���ʽ�����ض��Ĵ��붯̬���롣�����SQL����ʽ������CG�Ż��� CG�Ż���ʵ����Ҫ��������Scala2.10������ʱ������ƣ�runtime reflection���� 3. Scala�����Ż� SparkSQL��ʹ��Scala��д�����ʱ���������Ч�ġ�����GC�Ĵ��룻���������˱�д������Ѷȣ��������û���˵�ӿ�ͳһ�� 2.4 BlinkDBBlinkDB ��һ�������ں������������н���ʽ SQL ��ѯ�Ĵ��ģ���в�ѯ���棬�������û�ͨ��Ȩ�����ݾ�����������ѯ��Ӧʱ�䣬�����ݵľ��ȱ���������������Χ�ڡ�Ϊ�˴ﵽ���Ŀ�꣬BlinkDB ʹ����������˼��: lһ������Ӧ�Ż���ܣ���ԭʼ��������ʱ������ƽ�����ά��һ���ά������ lһ����̬����ѡ����ԣ�ѡ��һ���ʵ���С��ʾ�����ڲ�ѯ��ȷ�Ժͣ�����Ӧʱ������ �ʹ�ͳ��ϵ�����ݿⲻͬ��BlinkDB��һ��������˼�Ľ���ʽ��ѯϵͳ������һ�����ΰ壬�û���Ҫ�ڲ�ѯ���ȺͲ�ѯʱ������һȨ�⣻����û������ػ�ȡ��ѯ�������ô��������ѯ����ľ��ȣ�ͬ���ģ��û�������ȡ���߾��ȵIJ�ѯ���������Ҫ������ѯ��Ӧʱ�䡣�û������ڲ�ѯ��ʱ����һ��ʧ��߽硣 MLBase/MLlibMLBase��Spark��̬Ȧ��һ����רע�ڻ���ѧϰ���û���ѧϰ���ż����ͣ���һЩ���ܲ����˽����ѧϰ���û�Ҳ�ܷ����ʹ��MLbase��MLBase��Ϊ�IJ��֣�MLlib��MLI��ML Optimizer��MLRuntime�� l ML Optimizer��ѡ������Ϊ���ʺϵ��Ѿ����ڲ�ʵ�ֺ��˵Ļ���ѧϰ�㷨����ز������������û���������ݣ�������ģ�ͻ��İ��������Ľ���� l MLI ��һ������������ȡ��ML��̳�����㷨ʵ�ֵ�API��ƽ̨�� l MLlib��Sparkʵ��һЩ�����Ļ���ѧϰ�㷨��ʵ�ó��������ࡢ�ع顢���ࡢЭͬ���ˡ���ά�Լ��ײ��Ż������㷨���Խ��п����䣻 MLRuntime ����Spark�����ܣ���Spark�ķֲ�ʽ����Ӧ�õ�����ѧϰ���� �ܵ���˵��MLBase�ĺ����������Ż�����������ʽ��Taskת���ɸ��ӵ�ѧϰ�ƻ����������ŵ�ģ�ͺͼ�����������������ѧϰWeka��Mahout��ͬ���ǣ� l MLBase�Ƿֲ�ʽ�ģ�Weka��һ��������ϵͳ�� l MLBase���Զ����ģ�Weka��Mahout����Ҫʹ���߾߱�����ѧϰ���ܣ���ѡ���Լ���Ҫ���㷨�Ͳ������������� l MLBase�ṩ�˲�ͬ����̶ȵĽӿڣ����㷨�������� l MLBase����Spark���ƽ̨ 2.6 GraphXGraphX��Spark������ͼ(e.g., Web-Graphs and Social Networks)��ͼ���м���(e.g., PageRank and Collaborative Filtering)��API,������Ϊ��GraphLab(C++)��Pregel(C++)��Spark(Scala)�ϵ���д���Ż����������ֲ�ʽͼ��������ȣ�GraphX���Ĺ����ǣ���Spark֮���ṩһջʽ���ݽ�����������Է����Ҹ�Ч�����ͼ�����һ������ˮ��ҵ��GraphX�����Dz�����AMPLAB��һ���ֲ�ʽͼ��������Ŀ���������ϵ�Spark�г�Ϊһ����������� GraphX�ĺ��ij�����Resilient Distributed Property Graph��һ�ֵ�ͱ߶������Ե��������ͼ������չ��Spark RDD�ij�����Table��Graph������ͼ����ֻ��Ҫһ�������洢��������ͼ�����Լ����еIJ��������Ӷ��������������ִ��Ч�ʡ���ͬSpark��GraphX�Ĵ���dz���ࡣGraphX�ĺ��Ĵ���ֻ��3ǧ���У����ڴ�֮��ʵ�ֵ�Pregelģ�ͣ�ֻҪ�̶̵�20���С�GraphX�Ĵ���ṹ������ͼ��ʾ�����дֵ�ʵ�֣�����Χ��Partition���Ż����еġ�����ij�̶ֳ���˵���˵�ָ�Ĵ洢����Ӧ�ļ����Ż���ȷ��ͼ�����ܵ��ص���ѵ㡣 GraphX�ĵײ���������¼����ؼ��㡣 1.��Graph��ͼ�����в��������ն���ת�����������Table��ͼ��RDD��������ɡ�������һ��ͼ�ļ��㣬���������ϣ��ȼ���һϵ��RDD��ת�����̡���ˣ�Graph���վ߱���RDD��3���ؼ����ԣ�Immutable��Distributed��Fault-Tolerant��������ؼ�����Immutable�������ԣ������ϣ�����ͼ��ת���Ͳ�����������һ����ͼ�������ϣ�GraphX����һ���̶ȵIJ��䶥��ͱߵĸ����Ż������û����� 2.������ͼ�ײ㹲�õ��������ݣ���RDD[Vertex-Partition]��RDD[EdgePartition]������RDD��ɡ���ͱ�ʵ�ʶ������Ա�Collection[tuple]����ʽ�洢�ģ�������VertexPartition/EdgePartition���ڲ��洢һ���������ṹ�ķ�Ƭ���ݿ飬�Լ��ٲ�ͬ��ͼ�µı����ٶȡ�����������ṹ��RDDת���������ǹ��õģ������˼���ʹ洢������ 3.ͼ�ķֲ�ʽ�洢���õ�ָ�ģʽ������ʹ��partitionBy���������û�ָ����ͬ�Ļ��ֲ��ԣ�PartitionStrategy�������ֲ��ԻὫ�߷��䵽����EdgePartition������Master���䵽����VertexPartition��EdgePartitionҲ�Ỻ�汾�ر߹������Ghost���������ֲ��ԵIJ�ͬ��Ӱ�쵽����Ҫ�����Ghost�����������Լ�ÿ��EdgePartition����ıߵľ���̶ȣ���Ҫ����ͼ�Ľṹ����ѡȡ��Ѳ��ԡ�Ŀǰ��EdgePartition2d��EdgePartition1d��RandomVertexCut��CanonicalRandomVertexCut�����ֲ��ԡ����Ա��ֳ����£�EdgePartition2dЧ����á� 2.7 SparkRSparkR��AMPLab������һ��R��������ʹ��R���ѵ������е����ˣ�������ΪSpark��job�����ڼ�Ⱥ�ϣ��������չ��R�����ݴ��������� SparkR�ļ������ԣ� l �ṩ��Spark�е��Էֲ�ʽ���ݼ���RDD����API���û������ڼ�Ⱥ��ͨ��R shell�����Ե�����Spark job�� l ֧���հ����ܣ����Խ��û����庯���������õ��ı����Զ����͵���Ⱥ�������Ļ����ϡ� l SparkR�����Ժ����ص���R��������ֻ��Ҫ�ڼ�Ⱥ��ִ�в���ǰ��includePackage��ȡR�������Ϳ����ˣ���Ȼ��Ⱥ��Ҫ��װR�������� TachyonTachyon��һ�����ݴ��ķֲ�ʽ�ļ�ϵͳ�������ļ����ڴ���ٶ��ڼ�Ⱥ����н��пɿ��Ĺ���������Spark�� MapReduce������ͨ��������Ϣ�̳У��ڴ����룬Tachyon����˸����ܡ�Tachyon�������ļ��������ڴ��У������ò�ͬ�� Jobs/Queries�Լ���ܶ����ڴ���ٶ������ʻ����ļ�������ˣ�Tachyon���Լ�����Щ��Ҫ����ʹ�õ����ݼ�ͨ�����ʴ�������õĴ�����Tachyon����Hadoop�����е�Spark��MR������Ҫ�κ��Ķ����С� ��2013��4�£�AMPLab��������Tachyon 0.2.0 Alpha�汾��Tachyon������������ΪHDFS��300�����̶��ܵ��˼���Ĺ�ע��Tachyon�ļ����������£� lJAVA-Like File API Tachyon�ṩ����JAVA File���API, l������ Tachyonʵ����HDFS�ӿڣ�����Spark��MR������Ҫ�κ��ļ������С� l�ɲ�εĵײ��ļ�ϵͳ Tachyon��һ���ɲ�εĵײ��ļ�ϵͳ���ṩ�ݴ����ܡ�tachyon���ڴ����ݼ�¼�ڵײ��ļ�ϵͳ������һ��ͨ�õĽӿڣ�ʹ�ÿ��Ժ����IJ��뵽��ͬ�ĵײ��ļ�ϵͳ��Ŀǰ֧��HDFS��S3��GlusterFS�͵��ڵ�ı����ļ�ϵͳ���Ժ�֧�ָ�����ļ�ϵͳ�� ��ӭ���䡣
| 
 /1
/1 

 |������������
|������������
 ������ 2019-3-31 17:58:27
������ 2019-3-31 17:58:27
 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������