����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
Hive�������� Hive�����FacebookΪ������Ժ����罻�������ݵĹ����ͻ���ѧϰ������������ͷ�չ�ġ����������ڽ�����������ʱ���������������ڻ����������ƣ���hadoop���Ǵ�����ʱ����ĺ��ļ���������hadoop��mapreduce����רҵ��̫ǿ������facebook����Щ�����Ͽ�����hive��ܣ��Ͼ������ϻ�sql���˱Ȼ�java���˶�Ķ࣬hive����˵��ѧϰhadoop��ؼ�����һ��ͻ�ƿڡ���ô��hive��ʲô��? Hive�����˵��hive�ǻ���hadoop�����ݲֿ⡣ ��ôΪʲô˵hive�ǻ���Hadoop���أ� ֮����˵hive�ǹ�����Hadoop֮�ϵ����ݲֿ⣬��˵����Ϊ�� �����ݴ洢��hdfs�� �����ݼ�����mapreduce �����������������һ�£� Hive��һ�ֽ�����Hadoop�ļ�ϵͳ�ϵ����ݲֿ�ܹ������Դ洢��HDFS�е����ݽ��з��������������Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ�������ṩ������ SQL ��ѯ���ܣ����Խ� SQL ���ת��Ϊ MapReduce ����������У�ͨ���Լ��� SQL ȥ ��ѯ������Ҫ�����ݣ����� SQL ��� Hive SQL��HQL����ʹ����Ϥ MapReduce ���û�Ҳ�ܷܺ�������� SQL ���Զ����ݽ��в�ѯ�����ܡ�������ͬʱ���������Ҳ������Ϥ MapReduce �������ǿ����Զ����mappers��reducers�������ڽ���mappers��reducers����ɵĸ��ӵķ���������Hive�������û���д�Լ�����ĺ���UDF�������ڲ�ѯ��ʹ�á�Hive����3��UDF��User Defined Functions��UDF����User Defined Aggregation Functions��UDAF����User Defined Table Generating Functions��UDTF����Ҳ����˵�Դ洢��HDFS�е����ݽ��з������������Dz���ʹ���ֹ������ǽ���һ�����߰ɣ���ô������߾Ϳ�����hive�� Hive������Ӧ�ó���(1)��־�������ֻ�������˾ʹ��hive������־�����������ٶȡ��Ա��ȡ� 1)ͳ����վһ��ʱ����ڵ�pv��uv 2)��ά�����ݷ��� (2)�����ṹ���������߷��� Hive���ص㣨��ȱ�㣩��һ��hive���ŵ�(1)���������֣��ṩ����SQL��ѯ����HQL (2)����չ��Ϊ�������ݼ�����˼���/��չ������MR��Ϊ�������棬HDFS��Ϊ�洢ϵͳ�� һ������²���Ҫ��������Hive�������ɵ���չ��Ⱥ�Ĺ�ģ�� (3)�ṩͳһ��Ԫ���ݹ��� (4)��չ�ԣ�Hive֧���û��Զ��庯�����û����Ը����Լ���������ʵ���Լ��ĺ��� (5)�ݴ������õ��ݴ��ԣ��ڵ��������SQL�Կ����ִ�� ������hive��ȱ�㣨�����ԣ�(1)hive��HQL������������ 1)����ʽ�㷨���������pagerank 2)�����ھ��棬����kmeans (2)hive��Ч�ʱȽϵ� 1)hive�Զ����ɵ�mapreduce��ҵ��ͨ������²������ܻ� 2)hive���űȽ����ѣ����Ƚϴ� 3)hive�ɿ��Բ� Hive ����ԭ�� Hive ����ԭ������ͼ��ʾ�� 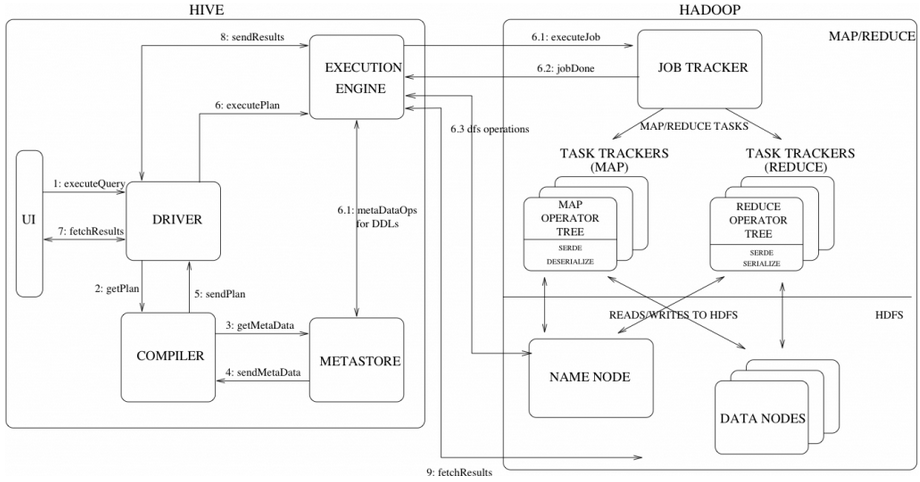 Hive������Hadoop֮�� ��1��HQL�жԲ�ѯ���Ľ��͡��Ż������ɲ�ѯ�ƻ�����Hive��ɵ� ��2�����е����ݶ��Ǵ洢��Hadoop�� ��3����ѯ�ƻ���ת��ΪMapReduce������Hadoop��ִ�У���Щ��ѯû��MR�����磺select * from table�� ��4��Hadoop��Hive������UTF-8����� Hive����������ɣ�  Hive������������ 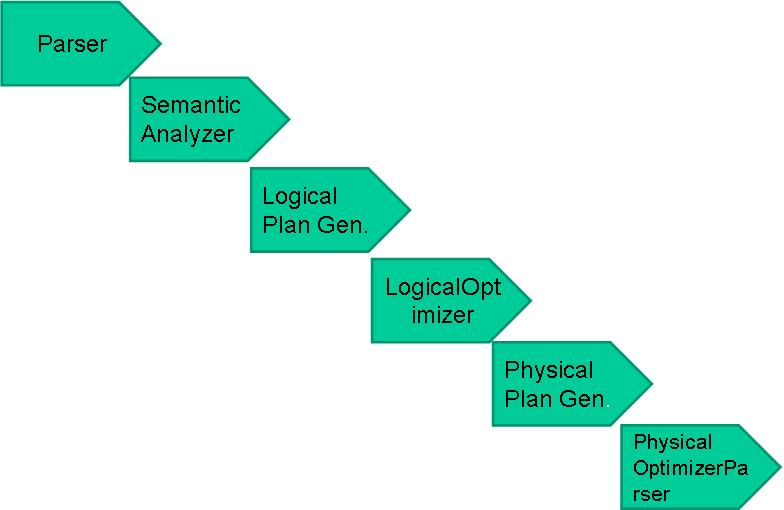 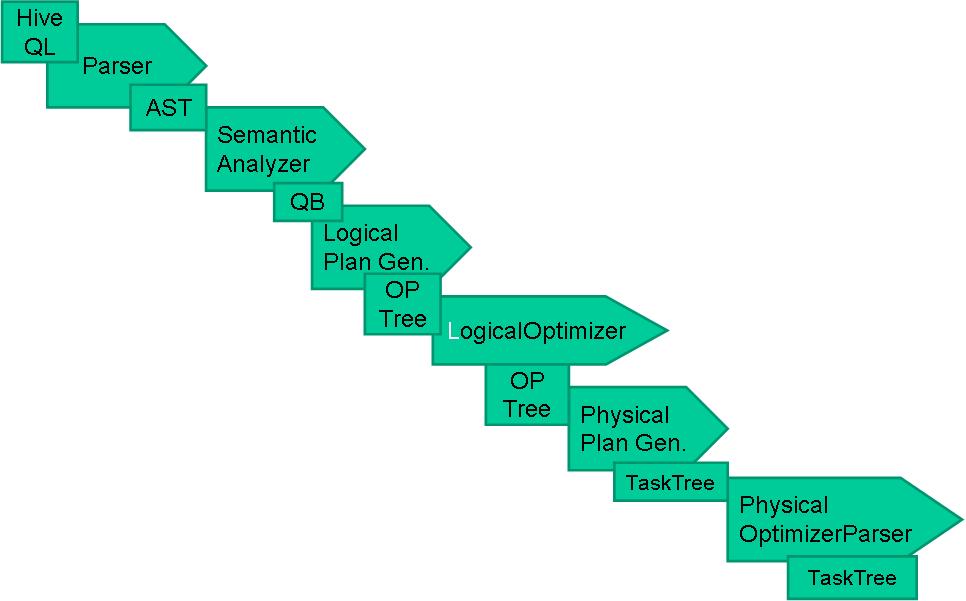 Hive�����ݿ����ͬ Hive�����ݿ����ͬ����Hive������SQL�IJ�ѯ����HQL����˺�����Hive����Ϊ���ݿ⡣��ʵ�ӽṹ��������Hive�����ݿ����ӵ�����ƵIJ�ѯ���ԣ���������֮�������ݿ��������Online��Ӧ���У�����Hive��Ϊ���ݲֿ����Ƶģ������һ�㣬�����ڴ�Ӧ�ýǶ�����Hive�����ԡ� Hive�����ݿ�ıȽ����±��� 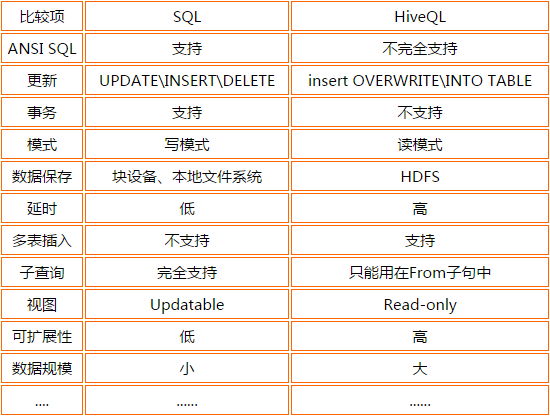 MapReduce ������Ա�����Լ�д�� Mapper �� Reducer ��Ϊ���֧�� Hive �������ӵ����ݷ����� �����ϵ�����ݿ�� SQL ���в�ͬ����֧���˾����������䣨�� DDL��DML���Լ������ľۺϺ��������Ӳ�ѯ��������ѯ�Ȳ����� Hive ���ʺ���������(online) ��������Ҳ���ṩʵʱ��ѯ���ܡ������ʺ�Ӧ���ڻ��ڴ������ɱ����ݵ���������ҵ��Hive ���ص��ǿ� ��������Hadoop �ļ�Ⱥ�϶�̬�������豸��������չ���ݴ��������ʽ����ɢ��ϡ�Hive �������DRIVER ��ִ�е� SQL ��������ύ�� DRIVER ������Ȼ����� COMPILER ���������� ���ս��ͳ� MapReduce ����ִ�У��������ء� Hive �������� Hive �ṩ�˻����������ͺ����������ͣ��������������� Java �����������еġ����γ̽��� Hive ���������������Լ���������֮���ת���� ��һ��������������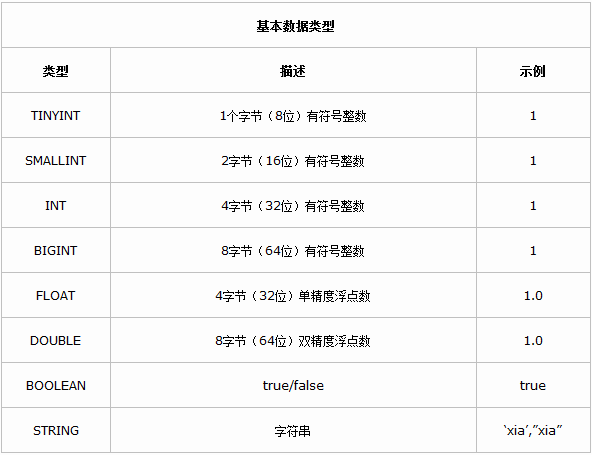 ���ϱ����ǿ���hive��֧���������ͣ���hive�����ڶ������ַ�������ʾ�ģ������õ����ڸ�ʽת����������ͨ���Զ��庯�����в����� hive����java�����ģ�hive��Ļ����������ͺ�java�Ļ�����������Ҳ��һһ��Ӧ�ģ�����string���͡��з��ŵ��������ͣ�TINYINT��SMALLINT��INT��BIGINT�ֱ�ȼ���java��byte��short��int��longԭ�����ͣ����Ƿֱ�Ϊ1�ֽڡ�2�ֽڡ�4�ֽں�8�ֽ��з���������Hive�ĸ�����������FLOAT��DOUBLE,��Ӧ��java�Ļ�������float��double���͡���hive��BOOLEAN�����൱��java�Ļ�����������boolean�� ����hive��String�����൱�����ݿ��varchar���ͣ���������һ���ɱ���ַ���������������������������ܴ洢���ٸ��ַ��������������Դ洢2GB���ַ����� ������������������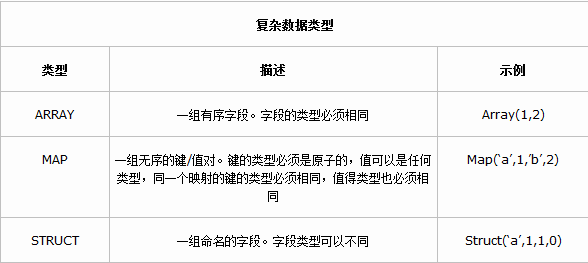 Hive �����ָ����������� ARRAY��MAP �� STRUCT��ARRAY �� MAP �� Java �е� Array �� Map ���ƣ���STRUCT �� C�����е� Struct ���ƣ�����װ��һ�������ֶμ��ϣ����������������������ε�Ƕ�ס� �����������͵���������ʹ�ü�����ָ�����������ֶε����͡��������У�ÿ�ж�Ӧһ�ָ��ӵ��������ͣ�������ʾ�� CREATE TABLE complex( col1 ARRAY< INT>, col2 MAP< STRING,INT>, col3 STRUCT< a:STRING,b:INT,c OUBLE>) ����������ת�� OUBLE>) ����������ת�� Hive ��ԭ�����������ǿ��Խ�����ʽת���ģ������� Java ������ת��������ij����ʽʹ�� INT ���ͣ�TINYINT ���Զ�ת��Ϊ INT ���ͣ� ���� Hive ������з���ת�������磬ij����ʽʹ�� TINYINT ���ͣ�INT �����Զ�ת��Ϊ TINYINT ���ͣ����᷵�ش�����ʹ�� CAST ������ ��1����ʽ����ת���������¡� 1�����κ��������Ͷ�������ʽ��ת��Ϊһ����Χ��������ͣ��� TINYINT ����ת���� INT��INT ����ת���� BIGINT�� 2���������������͡�FLOAT �� String ���Ͷ�������ʽ��ת���� DOUBLE�� 3����TINYINT��SMALLINT��INT ������ת��Ϊ FLOAT�� 4����BOOLEAN ���Ͳ�����ת��Ϊ�κ����������͡� ��2������ʹ�� CAST ������ʾ������������ת�������� CAST('1' AS INT) �����ַ���'1' ת�������� 1�����ǿ������ת��ʧ�ܣ���ִ�� CAST('X' AS INT)������ʽ���ؿ�ֵ NULL��
Hive �ܹ�������Hive�ļܹ�ͼ�� 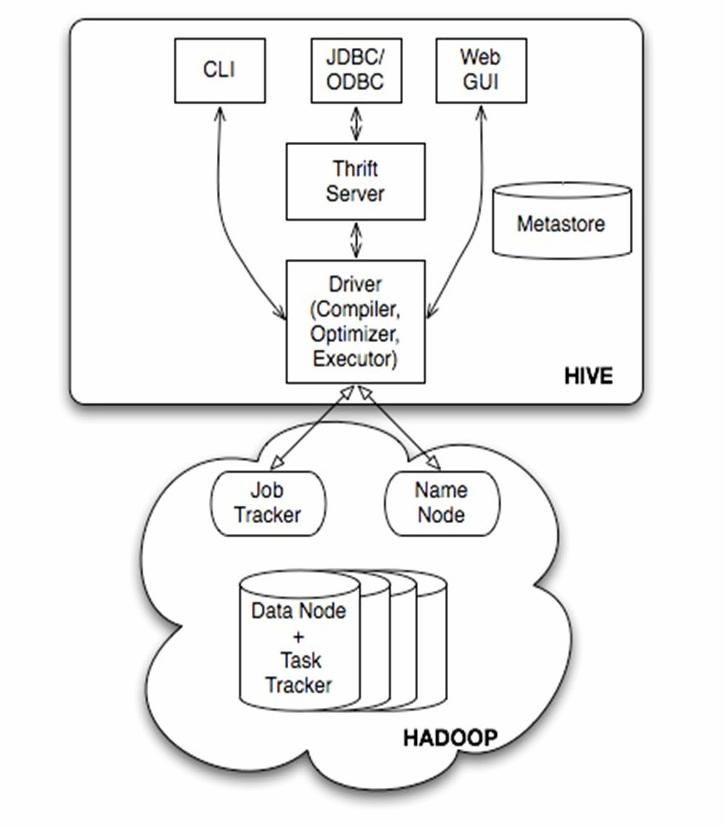 Hive����ϵ�ṹ���Է�Ϊ���¼����� Hive����ϵ�ṹ���Է�Ϊ���¼�������1���û��ӿ���Ҫ��������CLI��Client �� WUI��������õ���CLI��Cli������ʱ��ͬʱ����һ��Hive������Client��Hive�Ŀͻ��ˣ��û�������Hive Server�������� Clientģʽ��ʱ����Ҫָ��Hive Server���ڽڵ㣬�����ڸýڵ�����Hive Server�� WUI��ͨ�����������Hive�� ��2��Hive��Ԫ���ݴ洢�����ݿ��У���mysql��derby��Hive�е�Ԫ���ݰ����������֣������кͷ����������ԣ��������ԣ��Ƿ�Ϊ�ⲿ���ȣ���������������Ŀ¼�ȡ� ��3�������������������Ż������HQL��ѯ���Ӵʷ�����������������롢�Ż��Լ���ѯ�ƻ������ɡ����ɵIJ�ѯ�ƻ��洢��HDFS�У����������MapReduce����ִ�С� ��4��Hive�����ݴ洢��HDFS�У��ֵIJ�ѯ��������MapReduce��ɣ�����*�IJ�ѯ������select * from tbl��������MapRedcue���� ��һ���û��ӿ�Hive �����ṩ�����ַ���ģʽ���� Hive ������ģʽ��CLI����Hive �� Web ģʽ��WUI����Hive ��Զ�̷���Client�������������Щ������÷��� 1�� Hive ������ģʽ Hive ������ģʽ���������ַ�ʽ��ִ�����������ǰ����Ҫ���� Hive �Ļ��������� 1) ���� /home/hadoop/app/hive Ŀ¼��ִ��������� ./hive 2) ֱ��ִ����� hive --service cliHive ������ģʽ���� Linux ƽ̨�����в�ѯ����ѯ�������� MySQL ��ѯ������ƣ����н��������ʾ�� [hadoop@djt01 hive]$ hivehive> show tables;OKstockstock_partitiontstTime taken: 1.088 seconds, Fetched: 3 row(s)hive> select * from tst;OKTime taken: 0.934 secondshive> exit;[hadoop@djt01 hive]$2��Hive Web ģʽ Hive Web ����������������¡� hive --service hwiͨ����������� Hive��Ĭ�϶˿�Ϊ 9999�� 3�� Hive ��Զ�̷��� Զ�̷���Ĭ�϶˿ں� 10000��������ʽ�������£���nohup...&�� �� Linux �����ʾ�����ں�̨���С� nohup hive --service hiveserver & //��Hive 0.11.0�汾֮ǰ��ֻ��HiveServer�������nohup hive --service hiveserver2 & //��Hive 0.11.0�汾֮���ṩ��HiveServer2����Hive Զ�̷���ͨ�� JDBC �ȷ��������� Hive �����dz���Ա����Ҫ�ķ�ʽ�� ���γ����ǰ�װ����hive1.0�汾���������� hive service �������¡� hive --service hiveserver2 & //Ĭ�϶˿�10000hive --service hiveserver2 --hiveconf hive.server2.thrift.port 10002 & //����ͨ��������ֱ�ӽ��˿ںŸ�Ϊ10002hive��Զ�̷���˿ں�Ҳ������hive-default.xml�ļ������ã���hive.server2.thrift.port��Ӧ��ֵ���ɡ� < property> < name>hive.server2.thrift.port< /name> < value>10000< /value> < description> ort number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.< /description>< /property> ort number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.< /description>< /property> Hive �� JDBC ���Ӻ� MySQL ���ƣ�������ʾ�� import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;public class HiveJdbcClient { private static String driverName = "org.apache.hive.jdbc.HiveDriver";//hive�������� hive0.11.0֮��İ汾 //private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";//hive�������� hive0.11.0֮ǰ�İ汾 public static void main(String[] args) throws SQLException { try{ Class.forName(driverName); }catch(ClassNotFoundException e){ e.printStackTrace(); System.exit(1); } //��һ��������jdbc:hive://djt01:10000/default ����hive2��������ӵ�ַ //�ڶ���������hadoop ��HDFS�в���Ȩ���û� //������������hive �û����� �ڷǰ�ȫģʽ�£�ָ��һ���û����в�ѯ���������� Connection con = DriverManager.getConnection("jdbc:hive://djt01:10000/default", "hadoop", ""); System.out.print(con.getClientInfo()); }}
������Ԫ���ݴ洢��Hive��Ԫ���ݴ洢��RDBMS�У�������ģʽ�������ӵ����ݿ⣺��1�� ���û�ģʽ����ģʽ���ӵ�һ��In-memory �����ݿ�Derby��һ������Unit Test�� 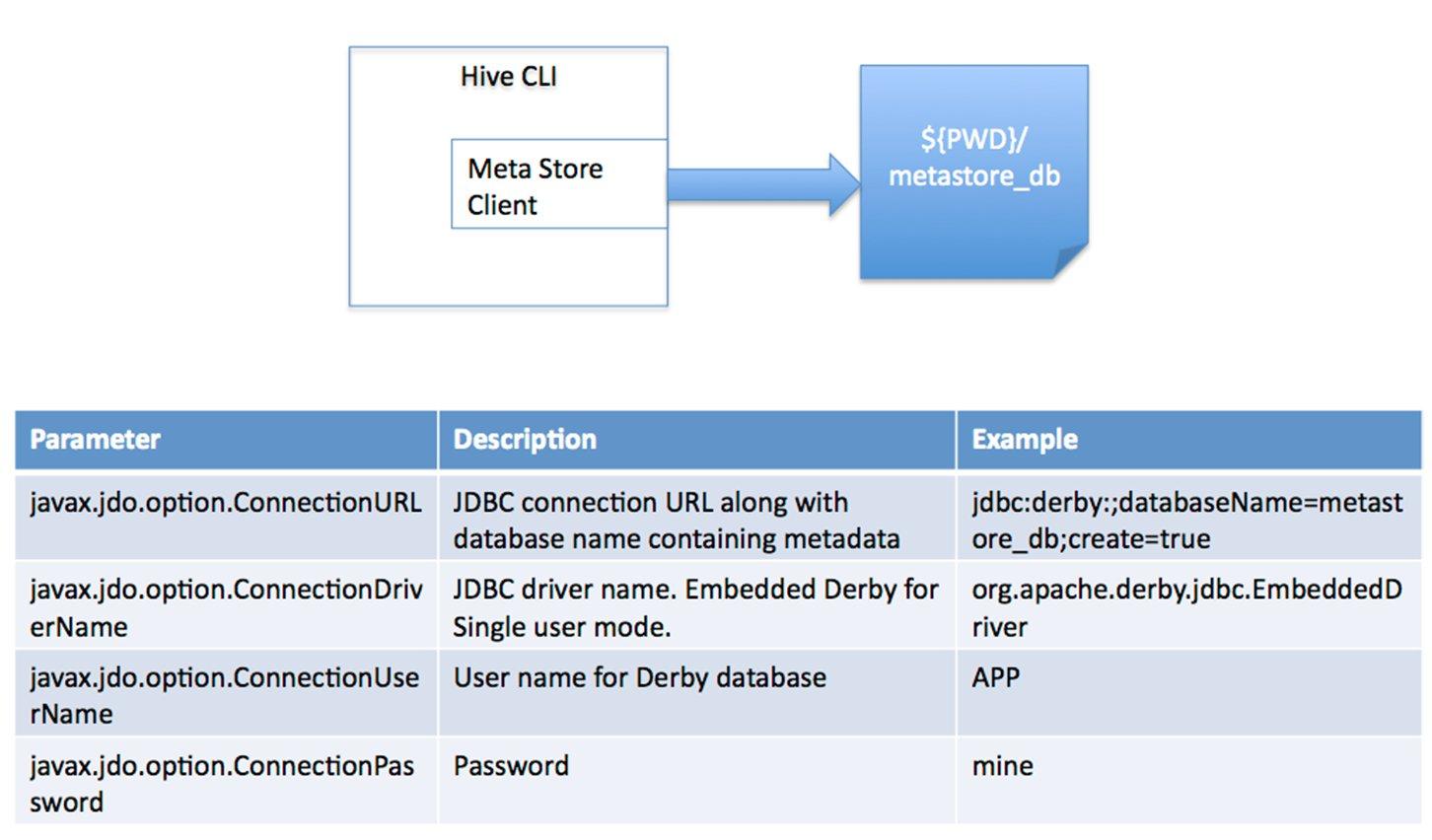 ��2�����û�ģʽ��ͨ���������ӵ�һ�����ݿ��У������ʹ�õ���ģʽ�� 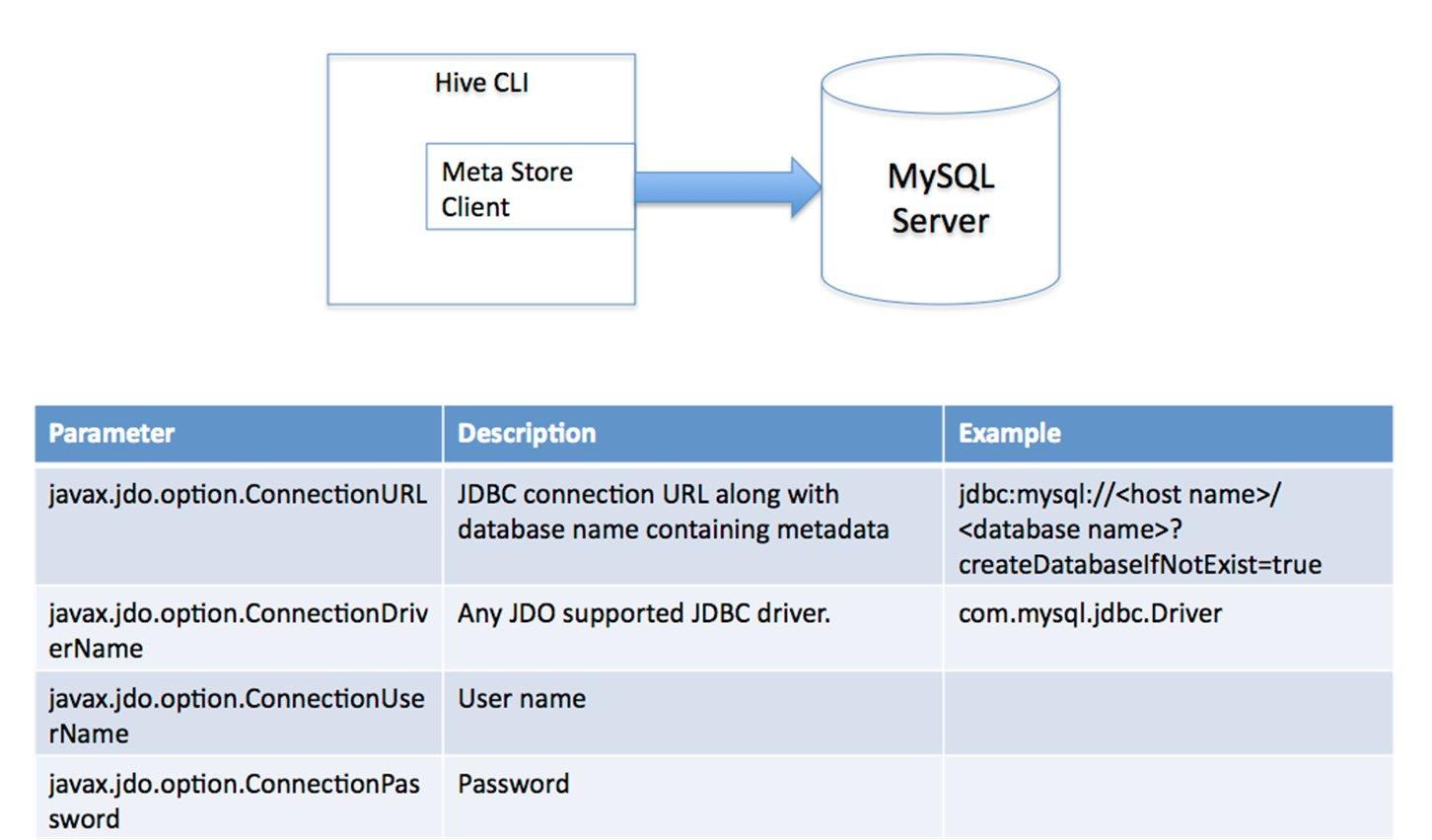 ��3�� Զ�̷�����ģʽ�����ڷ�Java�ͻ��˷���Ԫ���ݿ⣬�ڷ�����������MetaStoreServer���ͻ�������ThriftЭ��ͨ��MetaStoreServer����Ԫ���ݿ⡣ 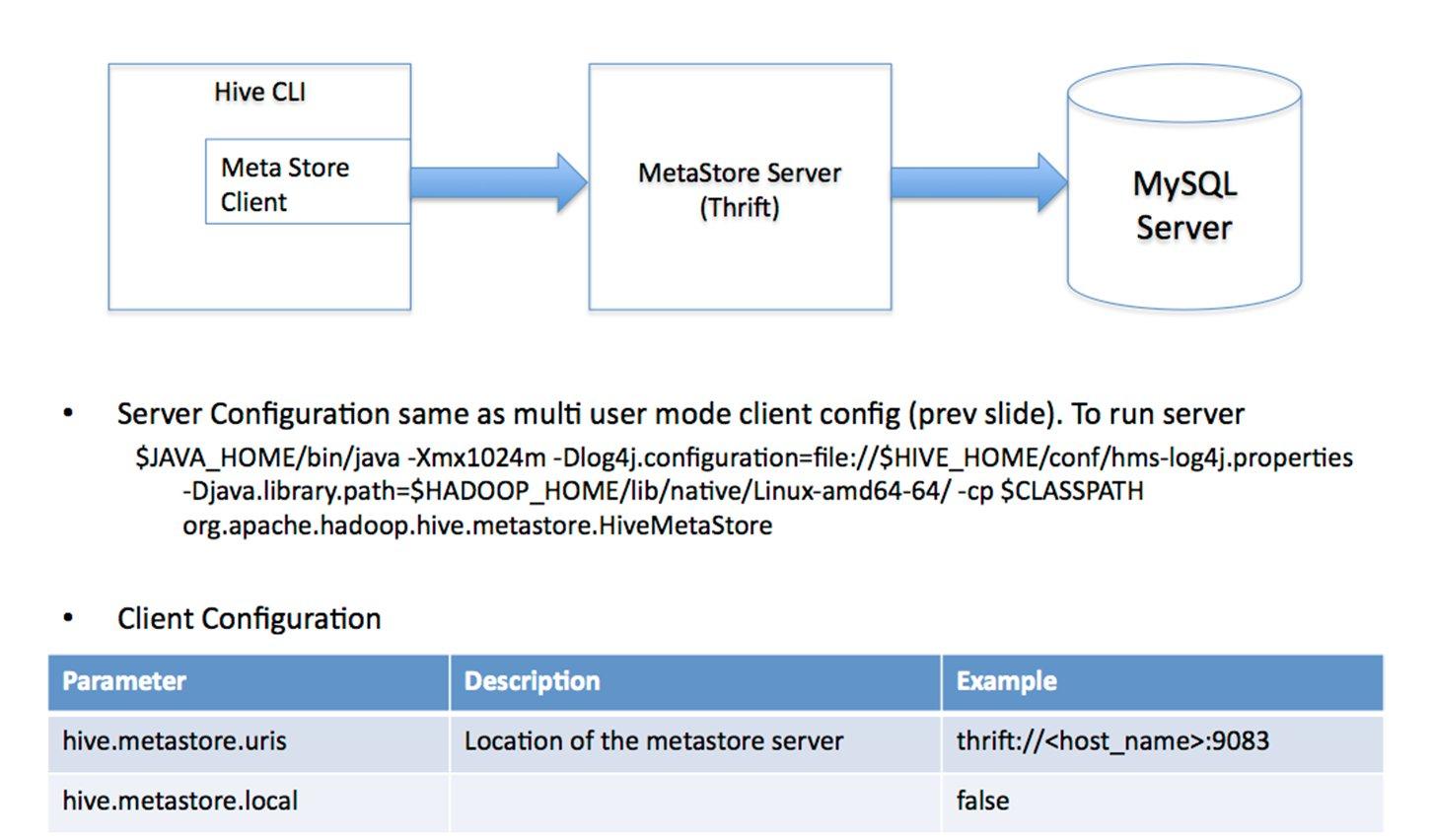 �������ݴ洢��Hiveû��ר�ŵ����ݴ洢��ʽ��Ҳû��Ϊ���ݽ����������û����Էdz����ɵ���֯Hive�еı���ֻ��Ҫ�ڴ�������ʱ�����Hive�����е��зָ������зָ�����Hive�Ϳ��Խ������ݡ�Hive�����е����ݶ��洢��HDFS�У��洢�ṹ��Ҫ�������ݿ⡢�ļ���������ͼ��Hive�а�����������ģ�ͣ�Table�ڲ�����External Table�ⲿ����Partition������BucketͰ��HiveĬ�Ͽ���ֱ�Ӽ����ı��ļ�����֧��sequence file ��RCFile�� �����������������������Ż����� 1)��������parser��������ѯ�ַ���ת��Ϊ����������ʽ�� 2)�����������semantic analyzer����������������ʽת��Ϊ���ڿ飨block-based�����ڲ���ѯ����ʽ�� 3)��������������logical plan generator�������ڲ���ѯ����ʽת��Ϊ�����ԣ���Щ����������������ɡ� 4)�Ż�����optimizer����ͨ�������Թ����;�����Բ�ͬ��ʽ��д��
Hive �ļ���ʽ hive�ļ��洢��ʽ�������¼��ࣺ 1��TEXTFILE 2��SEQUENCEFILE 3��RCFILE 4��ORCFILE(0.11�Ժ����) ����TEXTFILEΪĬ�ϸ�ʽ������ʱ��ָ��Ĭ��Ϊ�����ʽ����������ʱ��ֱ�Ӱ������ļ�������hdfs�ϲ����д����� SEQUENCEFILE��RCFILE��ORCFILE��ʽ�ı�����ֱ�Ӵӱ����ļ��������ݣ�����Ҫ�ȵ��뵽textfile��ʽ�ı��У� Ȼ���ٴӱ�����insert����SequenceFile,RCFile,ORCFile���С� ��һ��TEXTFILE ��ʽ Ĭ�ϸ�ʽ�����ݲ���ѹ�������̿��������ݽ��������� �ɽ��Gzip��Bzip2ʹ��(ϵͳ�Զ���飬ִ�в�ѯʱ�Զ���ѹ)����ʹ�����ַ�ʽ��hive��������ݽ����з֣� �Ӷ��������ݽ��в��в����� ʾ���� create table if not exists textfile_table(site string,url string,pv bigint,label string)row format delimitedfields terminated by '\t'stored as textfile;�������ݲ�����set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table textfile_table select * from textfile_table; ������SEQUENCEFILE ��ʽ SequenceFile��Hadoop API�ṩ��һ�ֶ������ļ�֧�֣������ʹ�÷��㡢�ɷָ��ѹ�����ص㡣 SequenceFile֧������ѹ��ѡ��NONE��RECORD��BLOCK��Recordѹ���ʵͣ�һ�㽨��ʹ��BLOCKѹ���� ʾ���� create table if not exists seqfile_table(site string,url string,pv bigint,label string)row format delimitedfields terminated by '\t'stored as sequencefile;�������ݲ�����set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; SET mapred.output.compression.type=BLOCK;insert overwrite table seqfile_table select * from textfile_table; ������RCFILE �ļ���ʽ RCFILE��һ�����д洢���ϵĴ洢��ʽ�����ȣ��佫���ݰ��зֿ飬��֤ͬһ��record��һ�����ϣ������һ����¼��Ҫ��ȡ���block����Σ���������ʽ�洢������������ѹ���Ϳ��ٵ��д�ȡ�� RCFILE�ļ�ʾ���� create table if not exists rcfile_table(site string,url string,pv bigint,label string)row format delimitedfields terminated by '\t'stored as rcfile;�������ݲ�����set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table rcfile_table select * from textfile_table;���ģ��ٿ�TEXTFILE��SEQUENCEFILE��RCFILE�����ļ��Ĵ洢�����[hadoop@djt01 ~]$ hadoop dfs -dus /user/hive/warehouse/*hdfs://hadoop@djt01:19000/user/hive/warehouse/hbase_table_1 0hdfs://hadoop@djt01:19000/user/hive/warehouse/hbase_table_2 0hdfs://hadoop@djt01:19000/user/hive/warehouse/orcfile_table 0hdfs://hadoop@djt01:19000/user/hive/warehouse/rcfile_table 102638073hdfs://hadoop@djt01:19000/user/hive/warehouse/seqfile_table 112497695hdfs://hadoop@djt01:19000/user/hive/warehouse/testfile_table 536799616hdfs://hadoop@djt01:19000/user/hive/warehouse/textfile_table 107308067[hadoop@djt01 ~]$ hadoop dfs -ls /user/hive/warehouse/*/-rw-r--r-- 2 hadoop supergroup 51328177 2014-03-20 00:42 /user/hive/warehouse/rcfile_table/000000_0-rw-r--r-- 2 hadoop supergroup 51309896 2014-03-20 00:43 /user/hive/warehouse/rcfile_table/000001_0-rw-r--r-- 2 hadoop supergroup 56263711 2014-03-20 01:20 /user/hive/warehouse/seqfile_table/000000_0-rw-r--r-- 2 hadoop supergroup 56233984 2014-03-20 01:21 /user/hive/warehouse/seqfile_table/000001_0-rw-r--r-- 2 hadoop supergroup 536799616 2014-03-19 23:15 /user/hive/warehouse/testfile_table/weibo.txt-rw-r--r-- 2 hadoop supergroup 53659758 2014-03-19 23:24 /user/hive/warehouse/textfile_table/000000_0.gz-rw-r--r-- 2 hadoop supergroup 53648309 2014-03-19 23:26 /user/hive/warehouse/textfile_table/000001_1.gz �ܽ ���TEXTFILE��SEQUENCEFILE��RCFILE������ʽ�洢��ʽ�����ݼ���ʱ�������Ľϴ��Ǿ��нϺõ�ѹ���ȺͲ�ѯ��Ӧ�����ݲֿ���ص���һ��д�롢��ζ�ȡ����ˣ�����������RCFILE����������ָ�ʽ���н����Ե����ơ�
���Ͼ��Dz���Ϊ��ҽ��ܵ���һ������Ҫ���ݣ��ⶼ�Dz����Լ���ѧϰ���̣�ϣ���ܸ���Ҵ���һ����ָ�����ã����õĻ�����ҵ��֧�֣��������û��Ҳ���������д�����ָ���������ڴ��ɹ�ע�����Ե�һʱ���ȡ����Ŷ��лл����
| 
 /1
/1 

 |������������
|������������
 ������ 2019-6-20 20:22:33
������ 2019-6-20 20:22:33
 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������