����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
һ.���ʽ��ͣ�
Coordinator:
Presto����ɫ����һ�ڵ㣬������ܿͻ�������SQL������������ִ�мƻ�������worker�ڵ㣻
Worker:
prestoʵ�ʴ���������������Ľڵ㣬������Դ��ȡ���ݣ��������������ݣ���coordinator���ȣ�
��������ظ�coordinator��������ͨ��������coordinator�е�discovery server�������ӡ�
Connector:
SPI�ӿڵ�ʵ�֣���SPIΪ������������Դ��ͳһ�ӿڹ淶�������ж���connector��ʵ�֣�
����hive,mysql,redis,kudu,kafka,monodb�ȵ�
Catalog:
����Դ���ã�ÿ��һ������Դ����һ��catalog��ͨ��connector����catalog;
Schema:
һϵ�б�����ϣ���ͬ��database�ĸ��
Table:
��ͬ�ڱ��ĸ�����presto����һ������ȫ��Ϊ select * from catalog.schema.tablename;
Statement:
�ͻ����ύ��ANSI SQL��䣬����ֻ�ı����ݣ�
Query:
queryΪ����sql֮���ִ�мƻ�������stage,tasks,splits,connectors��ִ��sql��Ҫ���������ϣ�
Stage:
Presto��ִ�мƻ����ϲ��Ϊ�����ε�stage,������״�ṹ������single stage(����ۺϣ����ؽ����coordinator)��fixed stages (�м����) ��
source stages������scan����ȡ����Դ)��stage��ֳɶ��task����ִ�У�
Task:
����������worker�ϵ����������������ÿ��stage���Ϊ���task�����Բ���ִ��;
Split:
Task�������������ݷ�Ƭ��ÿ��task����һ������split;
Driver:
split��һϵ�в����ļ��ϣ�һ��driver����һ��split��ӵ�����������
Operator:
��split��һ��������������ˣ���Ȩ��ת���ȵȣ�
Exchange:
���tasks֮������ݽ�����
��.�ܹ����
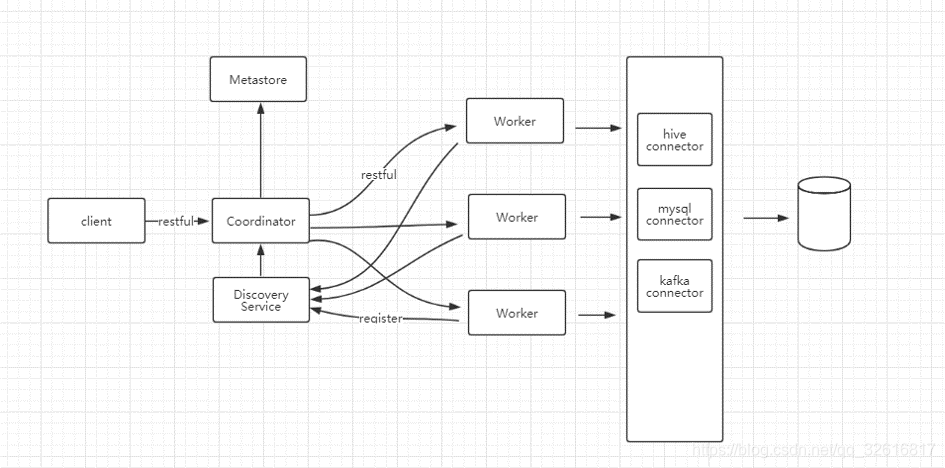
prestoΪ���ڴ����������в�ѯ���棬��ͬ��hive��mapreduce�����ݴ��������о�����δ���IO��presto������ȫ�ڴ���㣬�����ڵ��ڲ����˾ۺϵȵIJ������Լ��ڵ�֮������ݽ��� ��presto���Ϊ����ģʽ�ļܹ���coordinatorΪ���ڵ㣬������ܿͻ�������SQL������������ִ�мƻ�������worker�ڵ㡣workerΪ�ӽڵ㣬ʵ��ִ�в�ѯ����Ľڵ㣬֧�ֺ�����չ��worker������֮����ڵ���Ϣע�ᵽDiscovery Service����ͨ�������������ӣ��㱨����״̬��coordinator��Discovery Server��ȡ��Ⱥ�еĽڵ���Ϣ��Discovery Servery��Ƕ��Coordinator�����У����ʵ������£�ֻ����������ɫ����coordinator��worker��
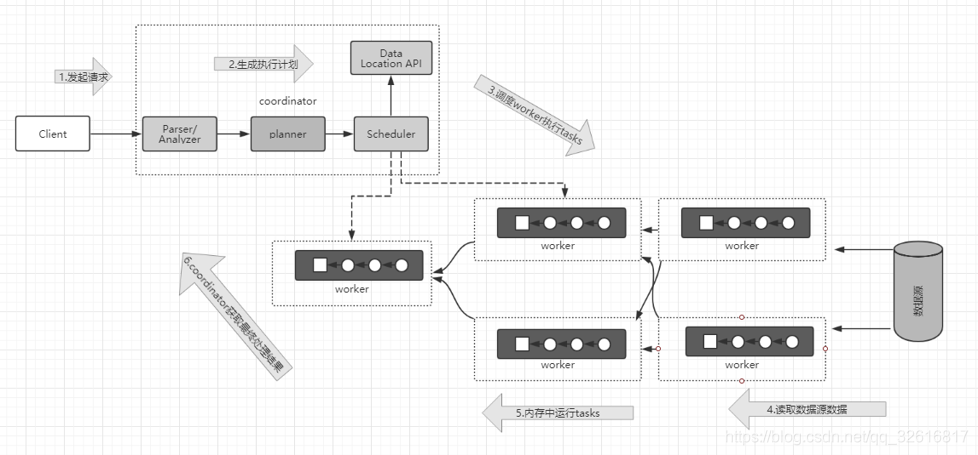
�ͻ����ύSQL��coordinator����coordinator�������SQL������ִ�мƻ������Ұ����ض��ĵ��Ȳ��ԣ����������ɵ�ִ�мƻ���Ӧ������tasks�ַ���worker��ִ�С��������ε�task������Դ��ȡ����Ҫ�����ݣ����ҽ��к����ļ���ʹ�����Coordinator�ӷַ�Task֮����һֱ���ϵĴ������ε�task��ȡ�������������������浽Buffer�У�ֱ�����м��������
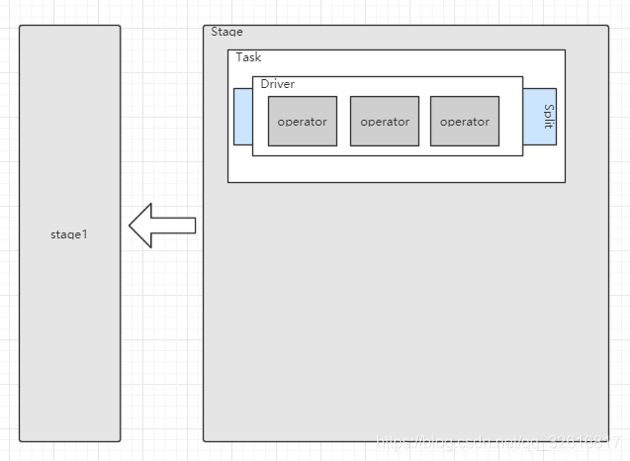
ʵ����Presto��ִ�в�ѯ��ʱ�������ǽ���ѯ���Ϊ���в㼶��ϵ�Ķ��Stage��һ��Stage������ѯִ�мƻ���һ���֡�Stage��������Ҫ�����֣�
Single: �������͵�Stage���ھۺ���Stage��������ݣ��������ս�������coordinator;
Fixed:�������͵�Stage���ڽ�������Stage���������ݼ����ڼ�Ⱥ�ж���Щ���ݽ��зֲ�ʽ�ۺϻ�������㣻
Source:�������͵�Stageֱ������Դ��������Դ��ȡ���ݣ���ȡ����ʱ��Ҳ�������ص��������ˡ�
Stage���������ڼ�Ⱥ�����У�ÿ��Stage���Բ��һϵ��Task����ЩTaskʵ�ʲ���������Worker��ÿ��Task����һ�����߶��Split��TaskҲʹ����ͬ�Ļ��Ʒֽ�Ϊһ�����߶��Driver,ÿ��Driverʱһϵ�в�������ϣ�����������һ�������IJ�ѯ��
��.Prestoʹ��
presto֧�����ֿͻ������ͣ�ͨ��Shell-cli�����пͻ��ˣ�����JDBC/ODBC�ͻ��ˡ�Prestoʹ��ANSI SQL�����Hiveʹ�õ�ʱHiveQL�����ʹ���ϴ���һЩ���
show databases;
presto ÿ��connector ��һ��catalog������hive;
���ݿ��Ϊschema, ����hive��
show databases
presto��
show schemas;
presto�в�ѯ�������ݣ�
select * from [catalog].[schema].[tableName];
presto֧�ֶ�̬�����±�
presto֧�ֶ�̬�����±�����HiveQLֻ֧�ֳ��������±꣬ANSI SQL�������£�
SELECT my_array[CARDINALITY(my_array)] as last_element FROM ...
presto�����
��һ��Ԫ�ص������±��1��ʼ��
SELECT my_array[1] AS first_element FROM ...
��˫���źͷ����ŵ�ʹ��
presto �ַ����õ����ţ���ʶ����˫����(���߿գ��������ı�ʶ��������˫���ż�����������ı���)������ ��
select "user_id" as "�û�ID" from "temp_table" where name='����';
hiveQL�ַ����õ����Ż���˫���ţ���ʶ���÷����ţ����磺
select `user_id` as `�û�ID` from `temp_table` where name="����";
���ֿ�ͷ�ı�ʶ��
presto�����ֿ�ͷ�ı�ʶ��������˫���ŷָ������磺
select * from "1_test";
�ַ�������
presto ʹ�� || ��Ϊ�ַ������Ӳ�������
select 'abc' || 'def';
ǿ������ת��
hiveQL ����ʽ����ת����presto����ʹ��ǿ������ת�������ұ����DZ����ͣ��ַ���ʹ��varchar�������磺
SELECT CAST(x AS
) , CAST(x AS
) , CAST(x AS double) , CAST(x AS
) FROM ...
��������
hive������������� 7/2��õ�3.5�Ľ������presto��ʹ�ñ����� 7/2 = 3�������Ҫ������ת���������ӻ��߷�ĸת��Ϊdouble �ͣ����磺
SELECT CAST(5 AS DOUBLE) / 2
�Ӳ�ѯʹ��
presto������ʹ���Ӳ�ѯ�취��
select * from
(select substr(name,1,3) as x from table1)
where x='foo';
����
with a AS (select substr(name,1,3) as x from table1)
select * from a where x='foo';
Ϊ�˱���ijЩ�û��Ĵ��ѯ�����¼�Ⱥ��Դ�ݽߣ�presto֧�ֻ��ֶ��У����Կ��Ʋ�ѯ�IJ������Ϳɽ��յ�SQL��������������û����ύ��Դ��Session����Ϣ���и��Ի����á�
���е������������£�

����ƥ���������£�
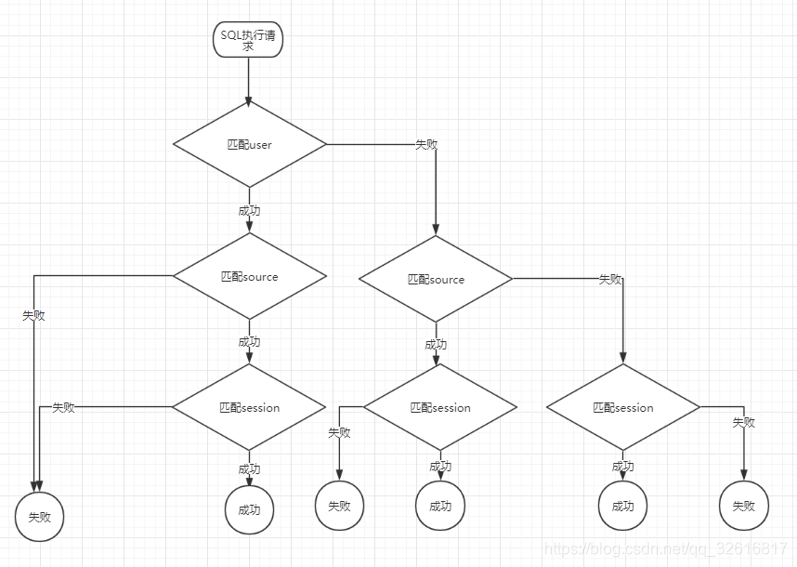
ƥ��ɹ����ֵ����������Ķ��У�����ж����������������Ĭ��ѡ���һ��ƥ���ϵġ�
���ڹ�˾�ڲ�����ʹ�õ�impala��Ҳ�ǻ���MPP�IJ�ѯ���棬presto�Ա�impala��������ȱ�㣺
�ŵ㣺
presto ���� CDH��
֧�ֶ�����Դ������ִ��refresh ���� invalidate metadata ��ˢ��Ԫ����
��ȫjava���������ڷ���ά���Ͷ��ο���
Ŀǰ������������˾��ʹ��presto��Ϊ������ʵʱ�����ͼ�ϯ��ѯ����
ȱ�㣺
Coordinator���ڵ������
Ϊ��ͳһ����ջ�ͺ���ά������Ҫ���������ڿ��Ǵ�impala���ȵ�presto����ӭ����Ȥ��ͬѧ��������һ�ν�����
������https://blog.csdn.net/qq_32616817/article/details/86512797
|

 /1
/1 

 |������������
|������������
 ������ 2019-7-3 12:01:01
������ 2019-7-3 12:01:01
 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������