����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
���� �� Spark �Ѿ���Ϊ��桢�����Լ��Ƽ�ϵͳ�����������㳡������ѡϵͳ����Ч�ʸߣ������Լ�ͨ����Խ��Խ�õ���ҵ����������Լ���������ڽӴ�spark�Լ�spark streaming֮��spark������ʹ����һЩ�Լ��ľ�������Լ��ĵ���ᣬ�ڴ˷�������ҡ��������δ�spark��̬��ԭ�����������spark streamingԭ����ʵ��������spark�����Լ�������ȷ�����н��ܣ�ϣ���Դ������������
spark ��̬������ԭ��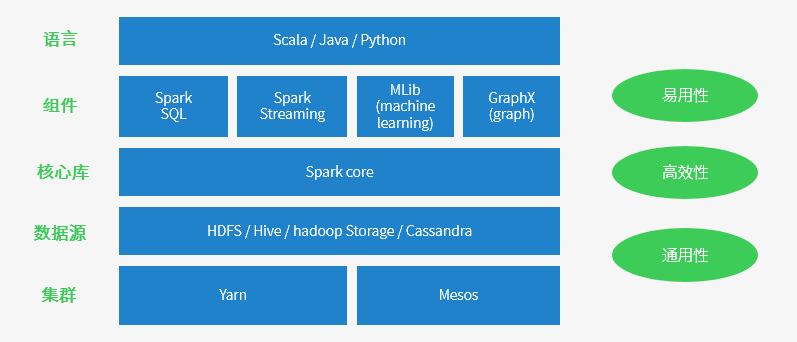
Spark �ص� - �����ٶȿ� => Sparkӵ��DAGִ�����棬֧�����ڴ��ж����ݽ��е������㡣�ٷ��ṩ�����ݱ�������������ɴ��̶�ȡ���ٶ���hadoop MapReduce��10�����ϣ�������ݴ��ڴ��ж�ȡ���ٶȿ��Ըߴ�100���
- ���ó����㷺 => �����ݷ���ͳ�ƣ�ʵʱ���ݴ�����ͼ���㼰����ѧϰ
- ������ => ��д��֧��80�����ϵĸ����ӣ�֧�ֶ������ԣ�����Դ�ḻ���ɲ����ڶ��ּ�Ⱥ��
- �ݴ��Ըߡ�Spark�����˵��Էֲ�ʽ���ݼ�RDD (Resilient Distributed Dataset) �ij������Ƿֲ���һ��ڵ��е�ֻ�����ϣ���Щ�����ǵ��Եģ�������ݼ�һ���ֶ�ʧ������Ը��ݡ�Ѫͳ�������������������������̣������ǽ����ؽ���������RDD����ʱ����ͨ��CheckPoint��ʵ���ݴ�����CheckPoint�����ַ�ʽ��CheckPoint Data����Logging The Updates���û����Կ��Ʋ������ַ�ʽ��ʵ���ݴ���
Spark�����ó��� Ŀǰ�����ݴ������������¼������ͣ� - ���ӵ�����������Batch Data Processing����ƫ�ص����ڴ����������ݵ����������ڴ����ٶȿ����ܣ�ͨ����ʱ�����������ʮ���ӵ���Сʱ��
- ������ʷ���ݵĽ���ʽ��ѯ��Interactive Query����ͨ����ʱ������ʮ�뵽��ʮ����֮��
- ����ʵʱ�����������ݴ�����Streaming Data Processing����ͨ�������ٺ��뵽����֮��
Spark�ɹ�����Ŀǰ�������ڻ�������˾��ҪӦ���ڹ�桢�������Ƽ�ϵͳ��ҵ���ϡ��ڹ��ҵ������Ҫ��������Ӧ�÷�����Ч�������������Ż��ȣ����Ƽ�ϵͳ��������Ҫ�������Ż�������������Ի��Ƽ��Լ��ȵ��������ȡ���ЩӦ�ó������ձ��ص��Ǽ�������Ч��Ҫ��ߡ���Ѷ / yahoo / �Ա� / �ſ����� spark���мܹ�spark�������мܹ�������ʾ�� 
spark���yarn��Ⱥ�������������������ʾ�� 
spark �������̣� Spark�ܹ������˷ֲ�ʽ�����е�Master-Slaveģ�͡�Master�Ƕ�Ӧ��Ⱥ�еĺ���Master���̵Ľڵ㣬Slave�Ǽ�Ⱥ�к���Worker���̵Ľڵ㡣Master��Ϊ������Ⱥ�Ŀ�����������������Ⱥ���������У�Worker�൱�ڼ���ڵ㣬�������ڵ����������״̬�㱨��Executor���������ִ�У�Client��Ϊ�û��Ŀͻ��˸����ύӦ�ã�Driver�������һ��Ӧ�õ�ִ�С�Spark��Ⱥ�������Ҫ�����ڵ�ʹӽڵ�ֱ�����Master���̺�Worker���̣���������Ⱥ���п��ơ���һ��SparkӦ�õ�ִ�й����У�Driver��Worker��������Ҫ��ɫ��Driver ������Ӧ����ִ�е���㣬������ҵ�ĵ��ȣ���Task����ķַ��������Worker������������ڵ�ʹ���Executor���д���������ִ�нΣ�Driver�ὫTask��Task��������file��jar���л��ݸ���Ӧ��Worker������ͬʱExecutor����Ӧ���ݷ�����������д����� - Excecutor /Task ÿ���������У���ͬ��������룬task���̲߳��У�
- ��Ⱥ��Spark����SparkֻҪ�ܻ�ȡ��ؽڵ�ͽ���
- Driver ��Executor����ͨ�ţ�Э������
���ּ�Ⱥģʽ�� 1.Standalone ������Ⱥ 2.Mesos, apache mesos 3.Yarn, hadoop yarn ������� Application =>Spark��Ӧ�ó�����һ��Driver program������Executor SparkContext => SparkӦ�ó������ڣ�������ȸ���������Դ��Э������Worker Node�ϵ�Executor Driver Program => ����Application��main()�������Ҵ���SparkContext Executor => ��ΪApplication������Worker node�ϵ�һ�����̣��ý��̸�������Task�����Ҹ������ݴ����ڴ���ߴ����ϡ�ÿ��Application����������Ե�Executor���������� Cluster Manager =>�ڼ�Ⱥ�ϻ�ȡ��Դ���ⲿ���� (���磺Standalone��Mesos��Yarn) Worker Node => ��Ⱥ���κο�������Application����Ľڵ㣬����һ������Executor���� Task => ������Executor�ϵĹ�����Ԫ Job => SparkContext�ύ�ľ���Action����������Action��Ӧ Stage => ÿ��Job�ᱻ��ֺܶ���task��ÿ������ΪStage��Ҳ��TaskSet RDD => ��Resilient distributed datasets�ļ�ƣ�����Ϊ���Էֲ�ʽ���ݼ�;��Spark����ĵ�ģ����� DAGScheduler => ����Job��������Stage��DAG�����ύStage��TaskScheduler TaskScheduler => ��Taskset�ύ��Worker node��Ⱥ���в����ؽ�� Transformations => ��Spark API��һ�����ͣ�Transformation����ֵ����һ��RDD�����е�Transformation���õĶ��������ԣ����ֻ�ǽ�Transformation�ύ�Dz���ִ�м���� Action => ��Spark API��һ�����ͣ�Action����ֵ����һ��RDD������һ��scala���ϣ�����ֻ����Action���ύ��ʱ�����ű������� Spark���ĸ���֮RDD
Spark���ĸ���֮Transformations / Actions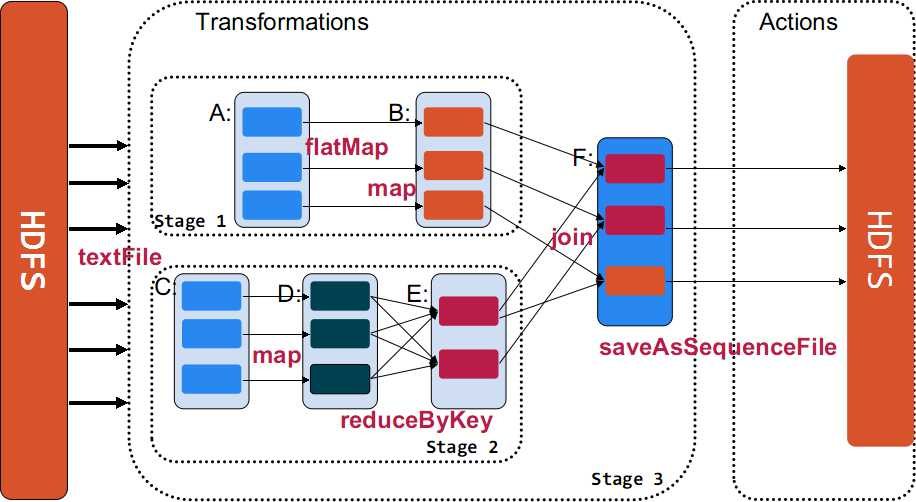
Transformation����ֵ����һ��RDD����ʹ������ʽ���õ����ģʽ����һ��RDD���м���任������һ��RDD��Ȼ�����RDD�ֿ��Խ�������һ��ת������������Ƿֲ�ʽ�ġ� Action����ֵ����һ��RDD����Ҫô��һ��Scala����ͨ���ϣ�Ҫô��һ��ֵ��Ҫô�ǿգ����ջص�Driver�����RDDд�뵽�ļ�ϵͳ�С� Action�Ƿ���ֵ���ظ�driver���ߴ洢���ļ�����RDD��result�ı任��Transformation��RDD��RDD�ı任�� ֻ��actionִ��ʱ��rdd�Żᱻ�������ɣ�����rdd����ִ�еĸ������ڡ� Spark���ĸ���֮Jobs / StageJob => �������task�IJ��м��㣬һ��action����һ��job stage => һ��job�ᱻ��Ϊ����task��ÿ�������Ϊһ��stage����shuffle���л��� 
Spark���ĸ���֮Shuffle��reduceByKeyΪ������shuffle���̡� 
��û��task���ļ���Ƭ�ϲ��µ�shuffle������������spark.shuffle.consolidateFiles=false�� 
fetch �������ݴ�ŵ���� �� fetch ���� FileSegment ����� softBuffer ����������������������ݷ����ڴ� + �����ϡ�����������Ҫ���۴���������ݣ��������������Щ�����ǡ�ֻ���ڴ桱���ǡ��ڴ棫���̡������spark.shuffle.spill = false��ֻ���ڴ档���ڲ�Ҫ����������shuffle write ������ܼ������� partition �ã����־û���֮����Ҫ�־û���һ������Ҫ�����ڴ�洢�ռ�ѹ������һ����Ҳ��Ϊ�� fault-tolerance�� shuffle֮������Ҫ���м����ŵ������ļ��У�����Ϊ��Ȼ��һ��task�����ˣ���һ��task����Ҫʹ���ڴ档���ȫ�������ڴ��У��ڴ���������һ����Ϊ���ݴ�����ֹ����ҵ��� �����������£� - ������ FileSegment ���ࡣÿ�� ShuffleMapTask ���� R��reducer �������� FileSegment��M �� ShuffleMapTask �ͻ���� M * R ���ļ���һ�� Spark job �� M �� R ���ܴ���˴����ϻ���ڴ����������ļ���
- ������ռ���ڴ�ռ��ÿ�� ShuffleMapTask ��Ҫ�� R �� bucket��M �� ShuffleMapTask �ͻ���� MR �� bucket����Ȼһ�� ShuffleMapTask ������Ӧ�Ļ��������Ա����գ���һ�� worker node ��ͬʱ���ڵ� bucket �������Դﵽ cores R ����һ�� worker ͬʱ�������� cores �� ShuffleMapTask����ռ�õ��ڴ�ռ�Ҳ�ʹﵽ��cores R 32 KB������ 8 �� 1000 �� reducer ��˵��ռ���ڴ���� 256MB��
Ϊ�˽���������⣬���ǿ���ʹ���ļ��ϲ��Ĺ��ܡ� �ڽ���task���ļ���Ƭ�ϲ��µ�shuffle������������spark.shuffle.consolidateFiles=true�� 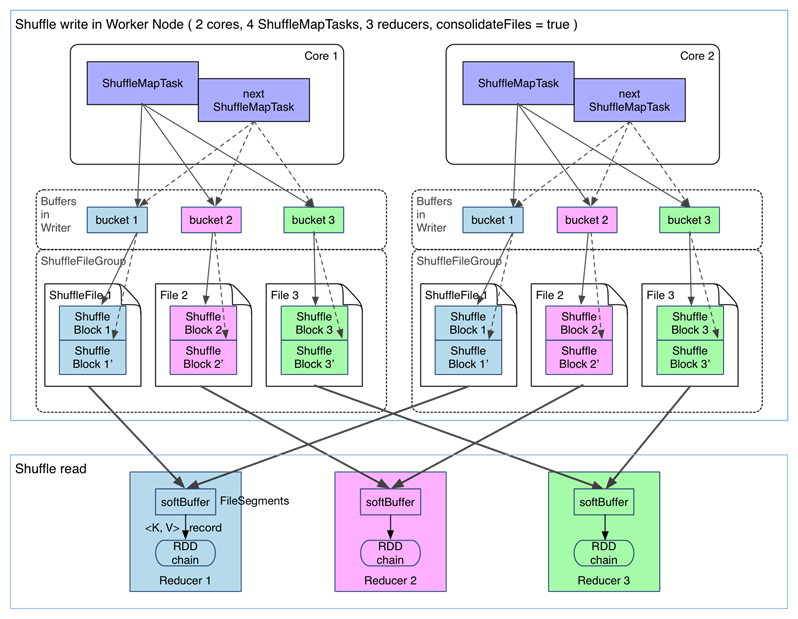
�������Կ�������һ�� core ������ִ�е� ShuffleMapTasks ���Թ���һ������ļ� ShuffleFile����ִ����� ShuffleMapTask �γ� ShuffleBlock i����ִ�е� ShuffleMapTask ���Խ��������ֱ���ӵ� ShuffleBlock i ���棬�γ� ShuffleBlock i'��ÿ�� ShuffleBlock ����Ϊ FileSegment����һ�� stage �� reducer ֻ��Ҫ fetch ���� ShuffleFile �����ˡ�������ÿ�� worker ���е��ļ�����Ϊ cores * R��FileConsolidation ���ܿ���ͨ��spark.shuffle.consolidateFiles=true�������� Spark���ĸ���֮Cacheval rdd1 = ... // ��ȡhdfs���ݣ����س�RDDrdd1.cacheval rdd2 = rdd1.map(...)val rdd3 = rdd1.filter(...)rdd2.take(10).foreach(println)rdd3.take(10).foreach(println)rdd1.unpersistcache��unpersisit���������Ƚ����⣬���ǼȲ���actionҲ����transformation��cache�Ὣ�����Ҫ�����rdd�������������ڵ�һ�α����action���ú�Ż��棻unpersisit��Ĩ���ñ�ǣ����������ͷ��ڴ档ֻ��actionִ��ʱ��rdd1�ŻῪʼ���������к�����rdd�任���㡣 cache��ʵҲ�ǵ��õ�persist�־û�������ֻ��ѡ��ij־û�����ΪMEMORY_ONLY�� persist֧�ֵ�RDD�־û��������£� 
��Ҫע������⣺Cache��shuffle�������л�ʱ�� spark���л���֧��protobuf message����Ҫjava ����serializable�Ķ���һ�������л��õ���֧��java serializable�Ķ���ͻ������������SparkֻҪд���̣��ͻ��õ����л�������shuffle�κ�persist�����л�������ʱ��RDD���������ڴ��У������õ����л��� Spark Streaming����ԭ��spark������ʹ��һ��sparkӦ��ʵ��һ���Զ�һ����ʷ���ݽ��д�����spark streaming�ǽ��������������������ת���ɶ��batch��Ƭ��ʹ��һ��sparkӦ��ʵ�����д����� 
��ԭ���Ͽ����Ѵ�ͳ��spark������������streaming����spark��Ҫ����ʲô�� 
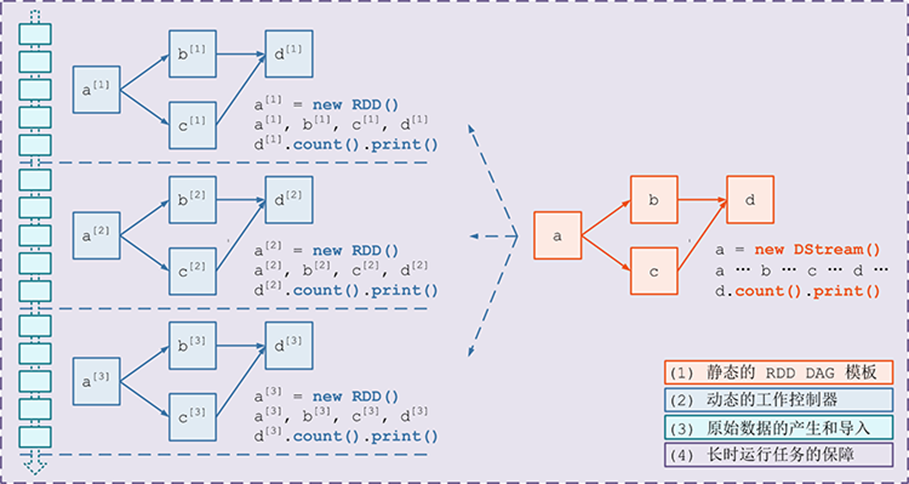
��Ҫ����4�������� - һ����̬�� RDD DAG ��ģ�壬����ʾ��������
- һ����̬�Ĺ������������������� streaming data �з�����Ƭ�Σ�������ģ�帴�Ƴ��µ� RDD 3. DAG ��ʵ����������Ƭ�ν��д���;
- Receiver����ԭʼ���ݵIJ����͵��룻Receiver�����յ������ݺϲ�Ϊ���ݿ鲢�浽�ڴ��Ӳ���У�������batch RDD��������
- �Գ�ʱ��������ı��ϣ������������ݵ�ʧЧ����ع������������ʧ�ܺ���ص���
����streaming����ϸԭ�����Բο����ͨ��Ʒ��Դ��������£� https://github.com/lw-lin/CoolplaySpark/blob/master/Spark%20Streaming%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E7%B3%BB%E5%88%97/0.1%20Spark%20Streaming%20%E5%AE%9E%E7%8E%B0%E6%80%9D%E8%B7%AF%E4%B8%8E%E6%A8%A1%E5%9D%97%E6%A6%82%E8%BF%B0.md#24 ����spark streaming��Ҫע���������㣺 - ������֤ÿ��work�ڵ��е����ݲ�Ҫ���̣�������ִ��Ч�ʡ�

- ��֤ÿ��batch�������ܹ���batch intervalʱ���ڴ�����ϣ�����������ݶѻ���

- ʹ��steven�ṩ�Ŀ�ܽ������ݽ���ʱ��Ԥ���������ٲ���Ҫ���ݵĴ洢�ʹ��䡣��tdbank�н��պ�ת��ǰ���й��ˣ���������task���崦��ʱ�Ž��й��ˡ�


Spark ��Դ�����ڴ������ 
Executor���ڴ���Ҫ��Ϊ���飺 ��һ������taskִ�������Լ���д�Ĵ���ʱʹ�ã�Ĭ����ռExecutor���ڴ��20%�� �ڶ�������taskͨ��shuffle������ȡ����һ��stage��task��������оۺϵȲ���ʱʹ�ã�Ĭ��Ҳ��ռExecutor���ڴ��20%�� ����������RDD�־û�ʱʹ�ã�Ĭ��ռExecutor���ڴ��60%�� ÿ��task�Լ�ÿ��executorռ�õ��ڴ���Ҫ����һ�¡�ÿ��task����һ��partiiton�����ݣ���Ƭ̫�٣�������ڴ治���� ������Դ���ã� 
������ſ��Բο����ŵ�����Ʒ�ĵ������£� http://tech.meituan.com/spark-tuning-basic.html http://tech.meituan.com/spark-tuning-pro.html Spark �����spark tdw�Լ�tdbank api�ĵ��� http://git.code.oa.com/tdw/tdw-spark-common/wikis/api
| 
 /1
/1 

 |������������
|������������
 ������ 2019-8-20 14:37:48
������ 2019-8-20 14:37:48
 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������