����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
��������� 168���� �� 2019-12-2 10:23 �༭
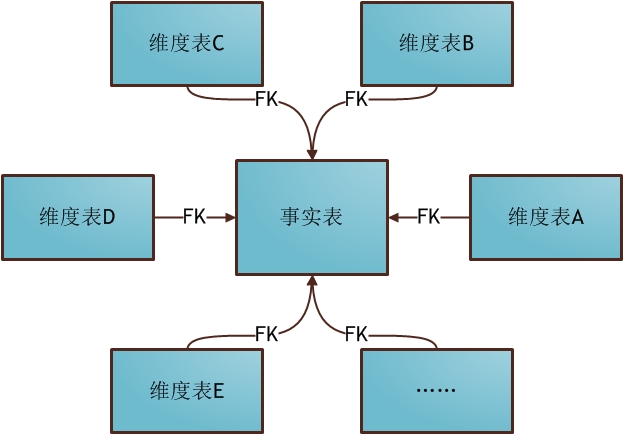
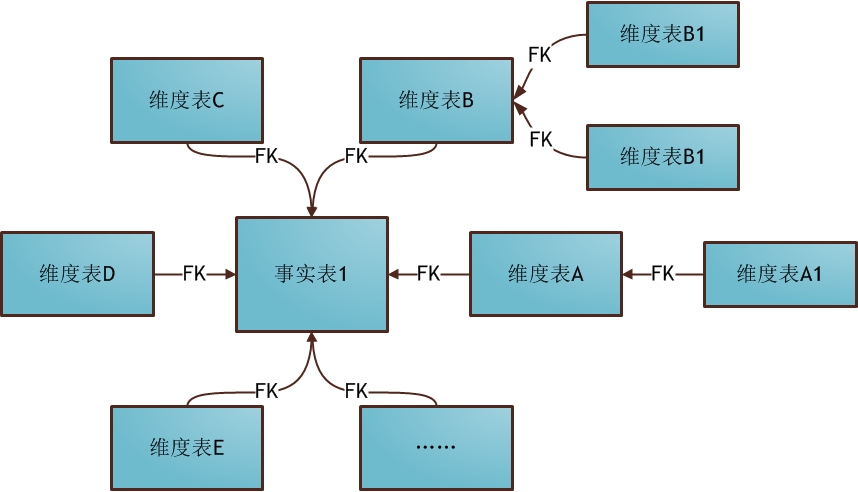
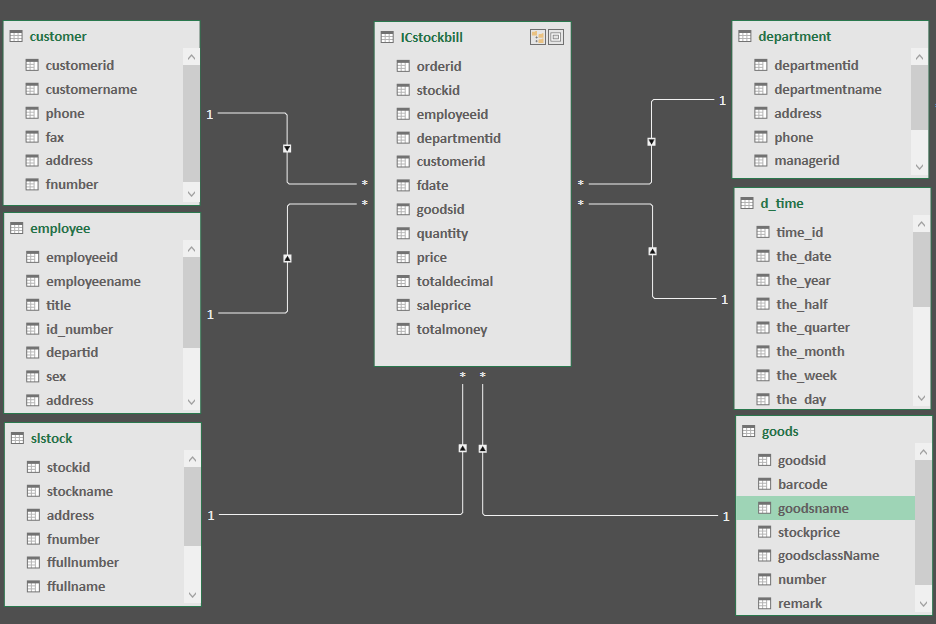
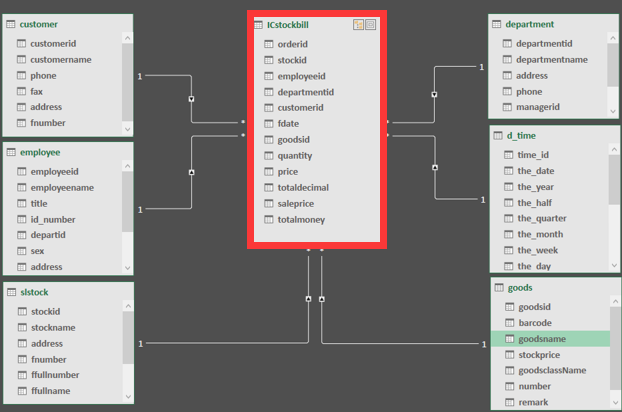
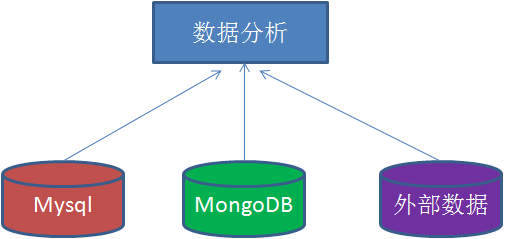
��һƪ�������Ѿ����������ݷ�����ΪɶҪ�������ݲֿ⣬�ӱ��ܿ�ʼ���ǿ�ʼһ��ѧϰ���ݲֿ⡣ѧϰ���ݲֿ⣬��һ�����˽�����ˣ����ݲֿ�֮���ȶ������ţ�Bill Inmon�������ݲֿ�Ȩ��ר��Ralph Kimball��Inmon��Kimball����DW�ܹ�֧�������ݲֿ��Լ���ҵ���ܽ���ʮ��ķ�չ������Inmon�������϶��µļܹ�����ͬ��OLTP���ݼ��е��������⡢���ɵġ�����ʧ�ĺ�ʱ��仯�Ľṹ�У������Ժ�ķ���;�����ݿ���ͨ�����굽��ϸ�㣬�����Ͼ������ܲ�;���ݼ���Ӧ�������ݲֿ���Ӽ�;ÿ�����ݼ�������Զ�������������Ƶġ���Kimball������Inmon�෴��Kimball�ܹ���һ�����¶��ϵļܹ�������Ϊ���ݲֿ���һϵ�����ݼ��еļ��ϡ���ҵ����ͨ��һϵ��ά����ͬ�����ݼ��е����ع������ݲֿ⣬ͨ��ʹ��һ�µ�ά�ȣ��ܹ���ͬ������ͬ���ݼ����е���Ϣ�����ʾ����ӵ�й��������Ԫ�ء� ��������Ҫ����ά�Ƚ�ģ��������һ������Kimball��������ģ�������������ǰ�����ʵ����ά�ȱ����������ݲֿ⡢���ݼ��С���ά�Ƚ�ģ������ϵ�У�ά����������ʵ�ĽǶȣ������ڡ��ͻ�����Ӧ�̵ȣ���ʵ��Ҫ������ָ�꣬��ͻ��������۶�ȡ�����һ���鼮�Ľ��ܣ�ά�Ƚ�ģ�����Ϊ����ģ�͡�ѩ��ģ�͵ȣ�������ȱ�㣬������ֱ�ӻش�һ�����⣬Ҳ�������ݲֿ�ΪʲôҪ����ά�Ƚ�ģ�� ����ģ�� ѩ��ģ�� ���ݲֿ���������ݺܶ࣬���������ܹ�����ģ�ͷ����ۡ���Ӧ�����幤���еĻ������������������Щ���ݣ� 2���������ݽ�ģ��������ά�Ƚ�ģ����ʽ��ģ����ʵ�彨ģ���� 3������ϵͳ������ϵͳ��Ԫ����ϵͳ��ETLϵͳ�����ӻ�ϵͳ���ศ��ϵͳ�� �������Ҳ������ݲֿ�ķ�Χ�����ж�������ݲֿ���ϵ�У�����ģ�͵ĺ��ĵ�λ�Dz�������ġ���ˣ�����Ľ���ϸ�ز������ݽ�ģ�еĵ��ʹ�����ά�Ƚ�ģ�������ĵ���������Լ�ʵ��ʹ��������ķ����� Ϊ���ܸ����е�����ʲô��ά�Ƚ�ģ���ҽ��ں�����������ģ��һ����Ҷ�ʮ����Ϥ�ĵ��̳��������ý��������۽��н�ģ�����ۺ���ʵ�Ĺ��������Ͼ���������࣬��һ�飬�һ����һ����ҵ��ʵ�ʵ�Ӧ������������ȡ�ᡣ�������������˽�ά�Ƚ�ģ һ��ʲô��ά�Ƚ�ģ ά��ģ�������ݲֿ������ʦRalph Kimball �����������ġ����ݲֿ���䡷�������ݲֿ�����������е����ֽ�ģ���䡣ά�Ƚ�ģ�Է������ߵ������������ģ�ͣ�����������ģ��Ϊ�����������������ص����û���θ�������ɷ�������ͬʱ���нϺõĴ��ģ���Ӳ�ѯ����Ӧ���ܡ� ���ǻ�һ�ַ�ʽ������ʲô��ά�Ƚ�ģ��ѧ�����ݿ��ͯЬӦ�ö�֪������ģ�ͣ�����ģ�;�������һ�ֵ��͵�ά��ģ�͡������ڽ���ά�Ƚ�ģ��ʱ��Ὠһ����ʵ���������ʵ����������ģ�͵����ģ�Ȼ�����һ��ά�ȱ�����Щά�ȱ��������ⷢɢ�����ǡ���ôʲô����ʵ����ʲô����ά�ȱ��������ר�������͡� ����ģ�� ����ά�Ƚ�ģ�Ļ���Ҫ�� ά�Ƚ�ģ����һЩ�Ƚ���Ҫ�ĸ����������Щ�������Ҳ��������ʲô��ά�Ƚ�ģ�� 1. ��ʵ�� ��������ʵ�����еIJ������¼������������Ŀɶ�����ֵ���洢����ʵ���С�����͵����ȼ�����������ʵ���ж�Ӧһ�������¼�����֮��Ȼ����̫����ٸ����ӡ�����һ�ι�����Ϊ���ǾͿ�������Ϊ��һ����ʵ����ҿ�һ������ģ��ʾ���� ͼ�еĶ�������ICstockbill������һ����ʵ�����������������������ʵ�з�����һ�β������¼�������ÿ���һ���������ͻ��ڶ���������һ����¼�����ǿ��Իع�ͷ�ٿ�һ����ʵ��������������ʵ����û�д��ʵ�ʵ����ݣ�����һ�������ļ��ϣ���ЩID�ֱ��ܶ�Ӧ��ά�ȱ��е�һ����¼�� 2. ά�ȱ� ÿ��ά�ȱ���������һ�������С�ά�ȱ�������������Ϊ��֮�������κ���ʵ�����������Ȼ��ά�ȱ��е���������Ӧ����ʵ������ȫ��Ӧ�� ά�ȱ�ͨ���ȽϿ����DZ�ƽ�ͷǹ淶�������������ĵ����ȵ��ı����ԡ�ͼ�е�customer���ͻ�������goods(��Ʒ��)��d_time(ʱ���)��Щ������ά�ȱ�����Щ������һ��Ψһ��������Ȼ���ڱ��д������ϸ��������Ϣ�� ���˵һ��ά��ģ�͵���ȱ�㣺 1����������С����Ϊ�ܶ�������Ϣ��������Ӧ��ά�ȱ����ˣ�����ͻ���Ϣ��ֻ��һ�ݣ� 2���ṹ���������ṹһĿ��Ȼ�� 3��������OLAP���������ݷ�����������ܷ��㣩 4������ʹ�óɱ��������ѯʱҪ�������ű� 5�����ݲ�һ�£������û���������Ϊ��ʱ������ݣ�������ά�ȱ������ŵ����ݲ�һ�� ��˵û�����ݲֿ�Ŀ���ʵ������ȱ�㣺 1��ҵ��ֱ�ۣ�����ҵ���ʱ�����ֱ��ر㣬ֱ���ܶԵ�ҵ���С� 2��ʹ�÷��㣬дsql��ʱ��ܷ��㡣 3�������������ĺܴ��ڼ��ڵ��û���ģ�£����Ķ�����Ϊ��ֲܿ������Ƚ�Ӳ��ʲô��д���ˣ����ű��Ŀɸ�����̫�͡� ���ݲֿ�Ľ�ģ�����кܶ��֣���Ŀǰ��Ҫѧϰ�˽��ά�Ƚ�ģ��������ʼ����д���ݲֿ�ϵ�����£��������д�����ĵط���ӭ���ָ�������� ϣ����ƪ�����ܹ�����Ҵ�������������л��ҵ��Ķ���
| 
 /1
/1 

 |������������
|������������
 ������ 2019-12-1 20:34:34
������ 2019-12-1 20:34:34

 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������