����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
��������� 168���� �� 2020-4-1 13:37 �༭
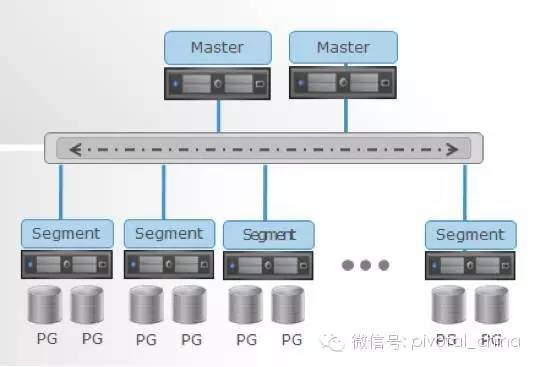
Greenplum���ݿ�ܹ� Greenplum���ݿ������PostgreSQL������ǿ���ݿ�ʵ����ϲ��νӳɵ����ݿ����ϵͳ����Greenplum������PostgreSQL��������չ������ÿ��Greenplum���ݿ���1��masterʵ����2����2������segmentʵ����ɣ��ͻ���ʹ��PostgreSQL�淶��Master���������ϵIJ�ͼ��չʾGreenplum���ݿ�ʵ����1��master��8 segementʵ����� Master Host��Masterʵ������GreenPlum���ݷ���ˣ������ͨ���˿�(Ĭ�϶˿�5432)�����ͻ������ӡ� 8��Segement������4��Segement Host��ÿ��Segement Host��һ̨������������в���ϵͳ���ڴ桢CPU���洢������ӿڡ���Master Host ���ƣ�Segement HostҲ�Ƕ�����������������
ÿ��Segement�����ݿ����˷��䲢����һ�������ݴ洢��ÿ��Segement��Segement Host���ö����˿ڼ����� Masterʵ��Э���������ݿ�ʵ�����ֲ�ʽ����Segement���Һϲ���Segement���صĽ����
Shared Nothing vs. Shared Disk GreenPlum���ݿ���Shared Nothing�ܹ�����Ϊÿ��Segementӵ���Լ���CPU���ڴ桢Ӳ���������������ݿ⡣�෴�����ڹ������̵�Shared Disk(��Shared Everything)�ܹ��ķֲ����ݿ����ϵͳӵ�ж�����ݿ����ʵ�������������ݿ�ʵ����Shared Nothing��Shared Disk�ܹ��в�ͬ����ȱ�㡣 �ڴ��̹���ϵͳ���������ݴ洢�ڱ������ݿ����ˣ�����Ҫͨ�����緢�����ݵ���һ������ִ��������ѯ��Ȼ��������̴洢������������� ���̹����������������ݿ�������������ӵ����ݿ⼯Ⱥ����������������總���洢������Ҫ���������ͱ��ֿɽ��ܵIJ�ѯ��Ӧʱ�䡣
Shared Disk�ܹ���, ÿ��CPU�����Լ����ڴ�, ��������CPU����һ��Ӳ��, ��ЩӲ����SAN����NAS����ʽ��֯��һ��
SD�ܹ���ȱ��
1. ����CPU��Ӳ�����������ӻ��Ϊϵͳ��ƿ��.
2. ��Ϊ����CPU�����Լ����ڴ�, ����û��һ���ط����Է�������(lock table)�������(buffer pool). Ϊ��������, ֻ����һ��CPU������һ��������������������ʹ�ø��ӵķֲ�ʽ��Э��. ��CPU������ �� ʱ, �����������ַ����Ŀ���չ�Զ����Ǻܺá�
Shared Nothing�ܹ���, ÿ��CPU���Լ����ڴ��Ӳ��. ���ݰ��б�ˮƽ����, ������ͬ�ڵ��ϴ洢���Dz�ͬ�е�����. ÿ���ڵ�ֻ�������Լ� Ӳ���ϵ�����. ÿ���ڵ����Լ��������ͻ����, �����ͱ����˸��ӵķֲ�ʽ�����ƣ�SN�Ŀ���չ�Էdz��á� GreenPlum��Ҫ�Ĺ��ܺ�����
SQL��
ͨ��SQL 2003 OLAP���ƹ���ȫ��֧��SQL-92��SQL-99�����в�ѯ��Ϣ�����е�������ϵͳ��ִ�С� ͳһ��������
������ͬһ������������������ִ�����в�ѯ�ͷ�����SQL��MapReduce��R�ȣ��������Ӷ�����������Ա��������Ա��ͳ����Աʹ��ͬһ���������ܽ������ݷ����� �ɱ�̲��з���
Ϊ���������ͳ�ƹ�������Ա�ṩ�˸��Ƚ��IJ��з������ܣ�֧��R�����Դ����ͻ���ѧϰ���ܡ� ���ݿ���ѹ��
������ҵ�����ȵ�ѹ��������������ܵ�ͬʱ�������ؼ��ٴ洢��������Ŀռ䡣�ͻ����Խ����ÿռ����3-10�����������Ч��I/O���ܡ� ǧ�����ֽڹ�ģ�����ݼ��ز���
�����ܵIJ�������װ�������������нڵ���ͬ��ִ�в�����װ���ٶȳ���4.5TB/Сʱ�� ��ط�������
�������ݵ�λ�á���ʽ��洢������Σ������Դ����ݿ����ⲿ����Դִ�в�ѯ���������������ݿⷵ�����ݡ� ��̬��չ
������˾�����ݲֿ���б�ݵ�С��ģ����ģ��չ��ͬʱ����߳ɱ����豸��SMP������������ �������ع���
����������Ա�������ڽ�ɫ����Դ���У��Ա㻮����Դ����ϵͳ���ء� ���й���
�ṩ��Ⱥ���������ߺ���Դ������������Ա�����һ̨������һ����������Greenplum���ݿ�ƽ̨�� ���ܼ��
ͨ��ͼ�λ������ܼ�ع��ܣ��û�����ȷ����ǰ���е��������ʷ��ѯ��Ϣ��������ϵͳʹ���������Դ��Ϣ�� ֧������
Greenplum֧�ֶ�������������ϣ��λͼ��GiST��GIN���Ӷ��ܹ�ʵ�ֶ����������ܣ��ṩ�����ݼܹ�ʦʵʩ�Ż����������Ĺ��ߡ� ��ҵ���ӿ�
֧�ֱ����ݿ�ӿڣ�SQL��ODBC��JDBC��DBI�������ҿ������г����Ƚ����������ܺͳ�ȡ/ת��/���أ�ETL�������������
����GreenPlum��һЩ����
��ƪ��������������gp��һЩ���������Ǹ������߰˰˵Ķ��������ǵ�����һЩsql��ʹ�á� 1��gp�Ƿֲ�ʽ�����ݿ⣬��hadoop�е����ƣ�Ҳ����master��slave�ļܹ���ϵ ժ�����ߵĻ���Greenplum���еIJ�����������Segment���ݽڵ�����ɺ�Masterֻ�������ɺ��Ż���ѯ�ƻ����ɷ�����Э�����ݽڵ���в��м��㣬Master�ϵ���Դ���ĺ����г���20%�����������ΪSegment���Ǽ���ͼ��ط����ij�������Ȼ����HA���棬Greenplum�ṩStandby Master���ƽ��б�֤���� ȱ�ݣ�����hadoopһ����֧�ֶಢ����Ҳ����˵sql�����ʱ��ִ���ٶȻ�ܿ죬��������ж��sqlһ�����У��ͻ������ޱȣ� 2��������ѹ���� ������GreenPlum���������ģ�����ʵ���ϣ��Ҳ�û�ж�GP�������ж��ٵIJ��ԣ���������£� -1.����Ǵӳ����������з��طdz�С�Ľ������������5%��������ʹ��BTREE�������ǵ������ݲֿ������ -2.����¼�Ĵ洢˳�����������һ�£����Խ�һ������IO���õ�index cluster�� -3.where�����е�����or�ķ�ʽ����join�����Կ���ʹ������ -4.��ֵ�����ظ�ʱ���Ƚ��ʺ�ʹ��bitmap���� ѹ������ʵѹ��Ҳ��Ϊ�˼ӿ��ѯ�ٶȣ��������£� -1.����Ҫ�Ա����и��º�ɾ������ -2.���ʱ���ʱ���������ȫ��ɨ�裬����Ҫ�������� -3.���ܾ����Ա������ֶλ������ֶ����� ʵ�ʲ��ԣ� -
CREATE TABLE "���ݿ�"."��" ( -
"�ֶ�1" varchar(20), -
"�ֶ�2" int4, -
"�ֶ�3" int8, -
"�ֶ�4" numeric, -
.... -
) -
WITH (APPENDONLY=true, COMPRESSLEVEL=1, ORIENTATION=column, COMPRESSTYPE=rle_type) -
DISTRIBUTED randomly;
�����ǵļ�Ⱥ�����£����´���һ�������������ܻ�ȴ��������úܶࣨ��ѯ8s�Ż���1.5s����ԭ������Ϊ�������ϴ���IO��������������cpuͦ���еģ�����ѹ���Ƶ�cpu����ȥѹ���ͽ�ѹ�����������io��ѹ�� 3���ֲ��� ���˾��÷ֲ�����һ��ͦ��Ҫ�Ķ�������Ϊ�ֲ������Ⱦͻᵼ��ʵ�ֲ��˲��У��Ӷ�Ӱ���ѯ���ٶȡ� -
CREATE TABLE "���ݿ�"."��" ( -
"�ֶ�1" varchar(50), -
"�ֶ�2" varchar(500), -
"�ֶ�3" varchar(500), -
.... -
"ʱ��" timestamp(6) DEFAULT now() -
) -
distributed by(�ֶ�1,�ֶ�2) -
;
-1.distributed by(�ֶ�1, �ֶ�2) �������������һ���ֶΣ�Ҳ�����Ƕ���ֶΣ�һ����˵����ͨ���û�id���豸mac�����ֺ������ֵ�������ֲ����� ����ڽ�����ʱ�����ֲ�������ô�ֲ����ͻ������ű��������������ǵ�һ���ֶΡ� Ҳ���Ը�������ֲ�����distributed by(�ֶ�1, �ֶ�2)�滻��DISTRIBUTED randomly -2.�ķֲ�����alter table "���ݿ�"."����" set distributed randomly; -3.�鿴�ֲ������ select gp_segment_id,count(*) from "���ݿ�"."����" group by gp_segment_id;-4.�ٸ����ӣ����������һ���ֲ�������flag��Ȼ������ֶ�ֻ������ֵ0��1������һ��20̨������ɵ�GreenPlum�������ű�ֻ��ֲ�����̨�����ϣ��ڼ����ʱ��Ҳֻ�ᶯ������̨������������������18̨��Χ�ۣ����Էֲ���Ҫ�������䣡 4���㼶��ϵ -1.���ݿ����� -2.�������ݿ� -3.����ģʽ��Ҳ��schema�� -4.������ ����������һ�����ģʽ�Ķ���������ͼ�� 5������sql -1.���ں����ܺ��ã� row_number() over(partition by XXX order by XXX desc) max() over(partition by XXX order by XXX) avg() over(partition by XXX order by XXX) .... -2.���л�ת -
--��ת�У�GP�� -
SELECT uid,String_agg(DISTINCT tag) as tag FROM (SELECT uid,tag FROM ���ݿ�.�� -
WHERE create_time BETWEEN '20180601' AND '20180701') tagtb GROUP BY uid; -
-
--��ת�У�pg postgresql�� -
SELECT string_agg(name,',') from test; -
-
--��ת�У�pg postgresql�� -
SELECT regexp_split_to_table(name,',') from test; -
-
--��ת�е�ȥ��(ʵ������) -
SELECT * FROM (SELECT -
regexp_split_to_table(tag_name,',') as tag -
FROM -
��A )tb -
WHERE -
tag IS NOT NULL -
GROUP BY -
tag -
ORDER BY -
1 ASC; -
-
ʹ�õ�ʱ��ע���£���ͬ��sql���л�ת�ĺ��������������ƿ��ܲ�̫һ����Ȼ���������ת�������Ҫ�и��ָ������������ķִʲ�ѯ�� -3.update��b���������ijһ���ֶ����õ���Ҫ�����ֶεı��У�ͨ��uid�������� -
update ���ݿ�.��Ҫ�����ֶεı� tb set ��Ҫ���µ��ֶ�=b.��һ�ű�����ͬ�ֶ� -
from (SELECT uid,String_agg(DISTINCT tag) as tag -
FROM (SELECT uid,tag FROM ���ݿ�.��һ�ű� WHERE ����) tagtb -
GROUP BY uid) b -
where tb.uid=b.uid; -
-
-
--1�����±���ǰ10�����ݣ�����Ϊ�̶�ֵ���� -
-
update BranchAccount -
set AccountNumber = '10010' -
from (select top 10 *from BranchAccountorder by ID)as t1 -
where BranchAccount.ID = t1.ID -
-
-
--2����һ�������ֶ�ֵ������һ������ij�ֶ�ֵ�� -
-
update BranchAccount -
set BranchAccount.AccountNumber = t1.AccountNumber -
from TEMPBranchAccount as t1 -
where BranchAccount.ID = t1.ID -
-
-
--3�����±�ǰ10�����ݣ�����Ϊ��һ���������ݣ��� -
-
update BranchAccount -
set BranchAccount.AccountNumber = t1.AccountNumber -
from (select top 10 *from TEMPBranchAccount)as t1 -
where BranchAccount.ID = t1.ID
��ʱд����ɣ��о���ûд�꣬����Ժ��뵽ʲô�ټӽ����ɣ����ߴ�������ʲô���ʵģ����Ը������ԣ�ϣ�����ܹ�����æ~ ============================================================================ ����һ�� ��¼�����������ڵĴ���sql -
--ע��gmt_modified ����ֶ��� default now() -
--��ǰ5������� -
select * from ����.���� WHERE gmt_modified >= (SELECT now() - interval '5 D') -
-
--�ڶ����������ģ���A�ͱ�C�ж�Ӧ������ݼ������֮����ȷ����B��û�м��㵱�������֮�ͷ���Ҫ��������ڣ���Ҫ��˵���ǿ���ͨ�����ַ�ʽ�������ڵķ�Χto_char((SELECT now() - interval '5 D'),'yyyyMMdd') ��date_id��int���� -
-
select *from ( -
select rc.date_id::VARCHAR as date_id,'${date_type}' as date_type from ( -
select date_id,status_flag from ��A where date_id>='${date_id}' and status_flag='Completed' ORDER BY date_id desc -
limit 9999 ) rc -
where not EXISTS (select date_id from ��B b where rc.date_id=b.date_id and rc.status_flag=b.status_flag) -
and EXISTS (select date_id from ��C b where rc.date_id=b.date_id) -
) tb -
where tb.date_id <=(to_char((SELECT now() - interval '5 D'),'yyyyMMdd')) -
ORDER BY date_id; -
-
--�������������ݿ��е��������ڵ�ǰ���� -
select count(1),gmt_modified,next_gmt_modified from ( -
select to_char(freshtime,'yyyyMMdd') as gmt_modified,(to_char(((select max(freshtime) from ��A) - interval '3 D'),'yyyyMMdd')) as next_gmt_modified from ��A -
where freshtime is not null -
) tb -
where gmt_modified >= next_gmt_modified -
GROUP BY gmt_modified,next_gmt_modified ORDER BY 2 desc; -
-
--���ǵ������и�ȱ�㣬ȱ����gmt_modified����ʱ��һ����˵����������ʲô�ģ����Ҫ������ֶε����ֵ�����п��ܲ�ѯ�ٶ������ޱȣ���˾���Ҫ�õ�������ʽ������������ -
--���磬����ñ�������������id����ô��ֻҪ�õ�id�����������ݵĸ���ʱ�䣬�������µ�ʱ�䣬����ʵ�����У�������sql�����ݶ������£���Ҫ��ѯ��Сʱ��������������sqlֻ��Ҫ����1���ӣ��� -
select * from ��A where -
freshtime >= -
( -
select next_gmt_modified::TIMESTAMP from ( -
select to_char(freshtime,'yyyyMMdd'),to_char((freshtime - interval '3 D'),'yyyyMMdd') as next_gmt_modified from ��A where ���� in (select max(����)from ��A ) -
) tb )
������� pg�ϵ���ص�Ԫ����sql -
--��ѯ��ռ�ÿռ��С -
select pg_size_pretty(pg_relation_size('����')); -
-
--��ѯij�ű�����ij��schema���Ƿ���� -
select * from pg_class where relname='����'::name and relkind='r' ) a INNER JOIN -
pg_namespace b on a.relnamespace = b.oid -
WHERE nspname = 'schema��' -
-
--ɱ��ij��sql -
select pg_terminate_backend(����sqlid); -
-
--��ѯ��ǰ����ִ�е�sql�������������ͼ�� -
SELECT (( 'select pg_cancel_backend(' :: TEXT || pg_stat_activity.procpid ) || ');' :: TEXT -
), -
( now() - pg_stat_activity.query_start ) AS cost_time, -
pg_stat_activity.datid, -
pg_stat_activity.datname, -
pg_stat_activity.procpid, -
pg_stat_activity.sess_id, -
pg_stat_activity.usesysid, -
pg_stat_activity.usename, -
pg_stat_activity.current_query, -
pg_stat_activity.waiting, -
pg_stat_activity.query_start, -
pg_stat_activity.backend_start, -
pg_stat_activity.client_addr, -
pg_stat_activity.client_port, -
pg_stat_activity.application_name, -
pg_stat_activity.xact_start, -
pg_stat_activity.waiting_reason, -
pg_stat_activity.rsgid, -
pg_stat_activity.rsgname, -
pg_stat_activity.rsgqueueduration -
FROM -
pg_stat_activity -
WHERE -
( -
pg_stat_activity.current_query <> ALL ( ARRAY [ '<IDLE>' :: TEXT, '<insufficient privilege>' :: TEXT ] )) -
ORDER BY -
( now() - pg_stat_activity.query_start ) DESC
����������ݲֿ��п��ٲ�ѯ���������ʹ��greenplum�� Greenplum���ݿ�Ҳ���GPDB����ӵ�зḻ�����ԣ� ��һ�����Ƶı�֧�֣�GPDB��ȫ֧��ANSI SQL 2008����SQL OLAP 2003 ��չ����Ӧ�ñ�̽ӿ��Ͻ�����֧��ODBC��JDBC�����Ƶı�֧��ʹ��ϵͳ������ά����������Ϊ���㡣�����ڵ� NoSQL��NewSQL��Hadoop �� SQL ��֧�ֶ������ƣ���ͬ��ϵͳ��Ҫ������������������ֲ�Բ��á� �ڶ���֧�ֲַ�ʽ����֧��ACID����֤���ݵ�ǿһ���ԡ� ��������Ϊ�ֲ�ʽ���ݿ⣬ӵ�����õ�������չ�������ڹ������û����������У������ϰٸ������ڵ��GPDB��Ⱥ���кܶస���� ���ģ�GPDB����ҵ�����ݿ��Ʒ��ȫ������ǧ����Ⱥ�ڲ�ͬ�ͻ��������������С���Щ��ȺΪȫ��ܶ��Ľ��ڡ����������������۵ȹ�˾�Ĺؼ�ҵ���ṩ���� ���壬GPDB��Greenplum�����ڵ�Pivotal����˾ʮ�����з�Ͷ��Ľ����GPDB����PostgreSQL 8.2��PostgreSQL 8.2�д�Լ80����Դ���룬��GPDB������130����Դ�롣���PostgreSQL 8.2��������Լ50���е�Դ���롣 ������Greenplum�кܶ������飬GPDB�����Ƶ���̬ϵͳ��������ܶ���ҵ����Ʒ���ɣ�Ʃ��SAS��cognos��Informatic��Tableau�ȣ�Ҳ���Ժܶ��ֿ�Դ�������ɣ�Ʃ��Pentaho,Talend �ȡ� greenplum��ԴGreenplum��������10����ǰ����Լ��2002�꣩���ֵģ������Ϻ�Hadoop��ͬһʱ�ڣ�Hadoop Լ��2004��ǰ�����ڵ�Nutch���ݵ�2002�꣩����ʱ�ı����ǣ� - ��������ҵ����֮ǰ��10�����������ķ�չ���ۻ��˴�����Ϣ�����ݣ������ڱ���ʽ��������Щ�������ݼ����µļ��㷽ʽ����Ҫһ�����㷽ʽ�ĸ�����
- ��ͳ����������ģʽ�ں���������ǰ��������۰����⣬�ڼ�����Ҳ�����������ݼ�������ָ�꣬��ͳ������Scale-upģʽ������ƿ����SMP���Գƶദ�����ܹ�������չ��������CPU�����IO�����ϲ������㺣�����ݵļ�������
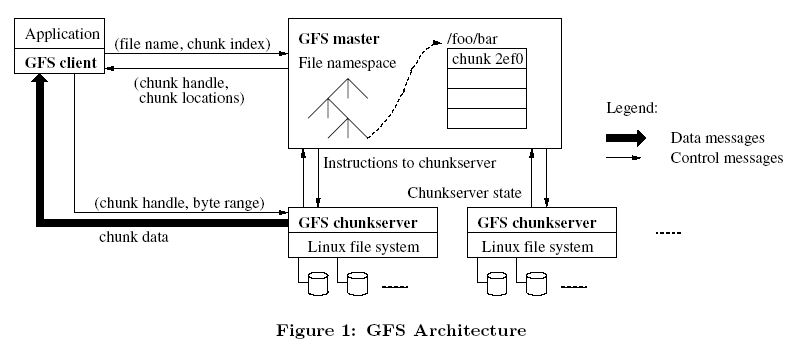
- �ֲ�ʽ�洢�ͷֲ�ʽ�������۸ոձ��������Google����ƪ�������ķ���������ҵ��Ĺ�ע��һƪ�ǹ���GFS�ֲ�ʽ�ļ�ϵͳ������һƪ�ǹ���MapReduce ���м����ܵ����ۣ��ֲ�ʽ����ģʽ�ڻ�������ҵ�ر�����������ͷִʼ����ȷ������˾�ɹ���
��ͼ����GFS�ļܹ�
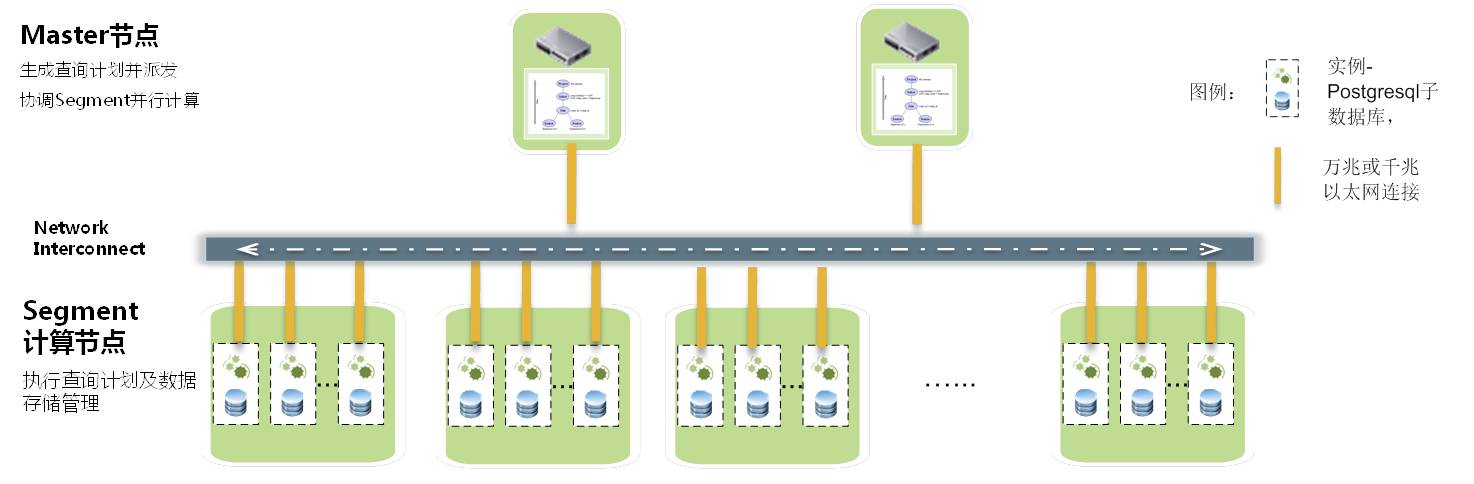
����ܹ� greenplum������ܹ����£� ���ݿ���Master Severs��Segment Seversͨ��Interconnect������ɡ� Master�������𣺽�����ͻ��˵����Ӻ�����SQL�Ľ������γ�ִ�мƻ���ִ�мƻ���Segment�ķַ��ռ�Segment��ִ�н����Master���洢ҵ�����ݣ�ֻ�洢�����ֵ䡣 Segment��������ҵ�����ݵĴ洢�ʹ�ȡ���û���ѯSQL��ִ�С�
greenplumʹ��mpp�ܹ���
������ϵ�ܹ�
master�ڵ㣬�������ɸ߿��õļܹ�
master node�߿��ã�������hadoop��namenode��second namenode��ʵ�������ĸ߿��á�
segments�ڵ�
�����

�������ݵ�װ�غ����ܼ�ء� ���б��ݺͻָ���
���ݷ������̣����ݷֲ�����ͬ��ɫ�Ľڵ���
��ѯ���̷�Ϊ��ѯ�����Ͳ�ѯ�ַ������������ء� ���ڴ洢�����洢�����ݷֲ�����������ϡ� �������ݵķֲ�����Ϊhash�ֲ�������ֲ����֡� ���ȷֲ�������� �ܽ� GPDB�ӿ�ʼ��Ƶ�ʱ��ͱ���������ݲֿ⣬�����olap��Ӧ�ã����Գ���ʹ��GPDB��
����Greenplum������https://dbaplus.cn/news-21-341-1.html
��ʱ����ĸ�̾�������´Ҵң��ر��ǵ�һ��IT�˳�����ij����������ʮ�������Ȼ���ף�����˵��������ǧ�п���
�������Ҵ�04��Ϳ�ʼ���´��ģ���ݼ������ع�����08����ΪGreenplum ����Ա������Greenplum�Ŷӣ���ʱ�Ĺ����ǡ�005�������������ǵõ�ʱ����һ��Greenplum�ļܹ����ţ��������ڴ�Ҷ���������Ǹ��ö��X86����ͼ�����������˵ؼ����ˣ�ת��֮�䣬�Ѿ����˵�8����ͷ��
�������Ŀ����������Greenplum�ڹ��ڵ�������ѿ�����ٷ�չ���ٵ�����ӵ��һ�ٶ����ҵ���û��Ĺ��̡�Ҳ��֤��Greenplum�����ڵ�2.1�汾����ǰ��4.37�汾������NB���ܵIJ�����ǿ��ϵͳ�ȶ��ԵIJ��ϴ����ߣ���Greenplum�ķ�չ׳���У�IT��ҵҲ�����ž�ı仯��ҵ�糱�����ſ��š���Դ�ķ������������������Ƽ���ʱ�����ɴ˿�����Greenplumʮ����Ŀ��ٷ�չ����żȻ�����ģ��������ڼ���·����ʼ�ձ���������IT��ҵ�ļ����ݽ��߶�һ���ܲ��ɷֵġ�
���������нӴ������СС��ʮ����������Ŀ����Щdz����ֹ����̵IJ���һ����������Զ��֧�֣�����Щ�����������ƣ����ڳ����ֳ�������������������˵�� ÿ����Ŀ�������һ���ĵ��ص㣬ֻҪ���ģ��������������Ŀ��ѧ��Щʲô�����������Ҿ��ð���Щ����һ�£�����ʵķ�ʽд�����������Լ��������⣬Ҳ����Դ�Ҹ������ȥ�˽�GP����һЩ������Ҳ������ij��������������Ŀǰ���������⣬��������ô���أ��칹���ݿ����Ǩ�ƣ���Ⱥ����θ��ٸ������ݣ������C API��չʵ�ָ�Ч���ݻָ��ȡ�ϣ���ҵ���ƪ�����ܹ�����Ҵ���������ͬʱҲϣ����Ҷ���ש��
Greenplum����Դ
Greenplum��������10����ǰ����Լ��2002�꣩���ֵģ������Ϻ�Hadoop��ͬһʱ�ڣ�Hadoop Լ��2004��ǰ�����ڵ�Nutch���ݵ�2002�꣩����ʱ�ı����ǣ�
1��������ҵ����֮ǰ��10�����������ķ�չ���ۻ��˴�����Ϣ�����ݣ������ڱ���ʽ��������Щ�������ݼ����µļ��㷽ʽ����Ҫһ�����㷽ʽ�ĸ����� 2��ͳ����������ģʽ�ں���������ǰ��������۰����⣬�ڼ�����Ҳ�����������ݼ�������ָ�꣬��ͳ������Scale-upģʽ������ƿ����SMP���Գƶദ�����ܹ�������չ��������CPU�����IO�����ϲ������㺣�����ݵļ������� 3�ֲ�ʽ�洢�ͷֲ�ʽ�������۸ոձ��������Google����ƪ�������ķ���������ҵ��Ĺ�ע��һƪ�ǹ���GFS�ֲ�ʽ�ļ�ϵͳ������һƪ�ǹ���MapReduce ���м����ܵ����ۣ��ֲ�ʽ����ģʽ�ڻ�������ҵ�ر�����������ͷִʼ����ȷ������˾�ɹ���
�ɴˣ�ҵ����ʶ�����ں���������Ҫһ���µļ���ģʽ��֧�֣�����ģʽ���ǿ���֧��Scale-out������չ�ķֲ�ʽ�������ݼ��㼼����
��ʱ�����ŵ�X86�����������Ѿ��ܺܺõ�֧�����ã������������磨��ʱ��ǧ����̫�����齨��X86��Ⱥ���������ṩ�ļ��������Ѵ�����ڴ�ͳSMP���������ҳɱ��ܵͣ��������չ�Ի��ɴ���ϵͳ���õijɳ��ԡ�
�������ˣ���X86��Ⱥ��ʵ���Զ��IJ��м��㣬�����Ǻ�����MapReduce�����ܻ���MPP���������д����������ܣ����ջ�����Ҫ������ʵ�֣�Greenplum��������һ�����²����ģ������ڷֲ�ʽ����˼�룬Greenplumʵ���˻������ݿ�ķֲ�ʽ���ݴ洢�Ͳ��м��㣨GoogleMapReduceʵ�ֵ��ǻ����ļ��ķֲ�ʽ���ݴ洢�ͼ��㣬���ǹ����Ƚ������ַ����������ԣ���
��˵����Greenplum����ʱ����һ��Startup��˾����ʼ�˼��ſ���һ����÷ ����greenplum����˶��������ټ���ʮ��λҵ�����˵����google��yahoo��ibm��TD����˵�ɾɣ�����1����ʱ���������İ汾��ƺͿ�����������ʵ�����ڿ���X86ƽ̨�ϵķֲ�ʽ���м��㣬���������κ�ר��Ӳ�����ﵽ������ȴԶԶ������ͳ�߰���ר��ϵͳ��
��Ҷ�֪��Greenplum�����ݿ�������ǻ��������Ŀ�Դ���ݿ�Postgresql�ģ���������Ϊʲô����Postgresql��������mysql�ȵȣ�������Postgresql�ǵ�ʵ�����ݿ⣬��ô���ڶ��X86�����������ж��ʵ����ʵ�ֲ��м����أ�Ϊ���⣬Interconnnect�����������ˡ�����1����ʱ��������Ǻܴ�һ���־������ڲ��ϵ���ơ��Ż�������Interconnect��������������������ʵ���˶�ͬһ����Ⱥ�ж��Postgresqlʵ���ĸ�ЧЭͬ�Ͳ��м��㣬interconnect�����˲��в�ѯ�ƻ�������Dispatch�ַ���QD����Э���ڵ���QEִ�����IJ��й������������ݷֲ���Pipeline���㡢�����ơ�����̽��ȵ��������
��Greenplum��Դ��ǰ����˵һЩ����Ҳ�п���MPP���ݿ�Ĵ��㣬�������ѵIJ��־�����Interconnect���������ϰ����ɼ�������Ĺؼ��ԡ�
GreenplumΪʲôѡ��Postgreeql������
˵���⣬Ҳ����ͬѧ���ʣ�ΪʲôGreenplum Ҫ����Postgresql? ����������������������⣺
1��Ϊʲô�������ݿ�ײ������������з���
�����Ƚϼ���ν��ҵ��ר�������������ܳ��IJ���������������һ��������ֻҪרע�ڷֲ�ʽ����������ĵIJ��д����������棬Э����������������ܵĸ�����Ȳ������ǵ�����Ŀ�ꡣ�����ݿ�ײ����������һ����������ʮ��ĥ�£����ݿ����漼���Ѿ��dz����죬��ɲ���ȥ������ƿ��������Ұ����ݿ�ײ㽻������רҵ����֯����������Ӧ��Postgresql���������������ɳ�����õ�������ԴԴ���ϵĴ�����������Դ���ò�Ʒ���ֳ�����ʢ����������
��Ҳ���������û�ѡ��ʱ��ͨ�������û�����һ�µײ�ļ���֧���Dz����кõ���֯������֧�ֵ�ԭ�����ȱ���ⷽ�������֧�ֻ���Ա������֣��Ǿ�������Ϊ�Ǹ�����ǰ;�е����ǣ�һ�����жϵı����ǿ��������Ǹ������ж�����ʹ�ã��ж�����Ϊ������������
2��Ϊʲô��Postgresql�����������ģ�
�����ҿ�����Ҫ����Ϊʲô��Postgresql������Mysql���Բ��𣬻��кܶԴ��ϵ�����ݿ⣬�����������������Դ�⣬������������ţ��������ʵ�ڲ���һ���������ϣ�����������ȥ����ϸ��������PK���������ݿ��������ӣ����Ϻܶ�Ƚϣ������������ǵĴ��ڶ��и��Ե��ص㣬���Ƕ��г���Ŀ�Դ������֧�֣��и��Ե��Ӵ��fansȺ�ڻ���������֮����Greenplumѡ��Postgressql�����¿��ǣ�
1��Postgresql�ų����Ƚ������ݿ⣨�ٷ���ҳ��The world��s most advanced open source database����,�Ҳ������Dz������ұ�ʹ�OLAP�����ͷ��������죬���¼���Postgresqlȷʵʤ��һ�
1PG�зdz�ǿ�� SQL ֧�������ͷdz��ḻ��ͳ�ƺ�����ͳ���֧�֣�����ANSI SQL��ȫ֧���⣬��֧�ֱ������������SQL2003 OLAP window���������������ö���������д�洢���̣�����Madlib��R��֧��Ҳ�ܺá���һ����MYSQL�Ͳ�ĺ�Զ���ܶ�������ܶ���֧�֣���Greenplum��ΪMPP���ݷ���ƽ̨����Щ���ܶ��DZز����ٵġ� 2Mysql��ѯ�Ż��������Ӳ�ѯ�����Ʋ�ѯ�����������������֧�ֵȽ������ر����ڹ���ʱ��������join������hash join��merge join��nestloop join��֧�ַ��棬Mysqlֻ֧�����һ��nestloop join����˵δ����֧��hash join��������������������ʱhash join�DZر���������ȱ����Щ�ؼ����ܷdz���������������OLAP����䵱���Ρ���������Ի���MYSQL��ij�ڴ�ֲ�ʽ���ݿ����ԱȲ���ʱ���������ŵ���OLTP�dz��죬TPS�dz��ߣ����ɸ㶨��ʮ����һ�����Ӷ���������ܾ������½�����ʹ������ڴ����Ĺ���Ҳ����Ϊ������������ƻ����ܵ�mysql���ⷽ�����ơ�
2����չ�Է��棬Postgresql��mysqlҲҪ��ɫ���࣬Postgres��������Ϊ��չ�����ģ��������PG����Python��C��Perl��TCL��PLSQL�ȵ���������չ���ܣ��ں����½��У��ҽ�չ��������չ����εķ��㣬���⣬�����µĹ���ģ�顢�µ��������͡��µ��������͵ȵȷdz����㣬ֻҪ����API�ӿڿ����������PG���±��롣PG��contribĿ¼�µĸ���������ģ�飬��GP�е�postgis�ռ����ݿ⡢R��Madlib��pgcrypto��������㷨��gptextȫ�ļ�������ͨ�����ַ�ʽʵ�ֹ�����չ�ġ�
3��������ACID���ﴦ��������ǿһ���Ա�֤����������֧�֡����ص�MVCC������Ч���ݸ��������Ȼ��кܶ�棬Postgresql�ƺ�����ЩOLAP�����϶���mysql����һ�
4�����Postgresql�����Ƿ���BSD����ģʽ�ģ�û�б���˾���ƣ������Ƚϴ��࣬�汾��·�߿��Ʒdz��ã�����Postgresql�����û�ӵ�и��������ԡ�����Mysql��������״���ڶ��֧����MariaDB����ȷʵ���ҵġ�
�ðɣ����ٹ����о��ˣ���Щ�ص��Ѿ��㹻�ˣ���˵�ܶ������˾����Mysql����OLTP��ͬʱ��ȴ����Postgresql�����ڲ���OLAP�������ݿ⣬�������µ�OLTPϵͳҲֱ�Ӳ���Postgresql��
���֮�£�Greenplum��ǿ������Postgresql��Ϊʵ����ע����ʵ����Oracleʵ���������ָ����һ���ֲ�ʽ�ӿ⣩�ܹ���Interconnect�£���Interconnect��ָ��Э���£���ʮ��������ǧ��Sub Postgresql���ݿ�ʵ��ͬʱ��չ���м��㣬���ң���ЩPostgresql֮�����share-nothing�����ܹ����Ӷ��������ֲ��м����������ӵ����¡�
����֮�⣬MPP���������ύ��ȫ�����������������֤��Ⱥ�Ϸֲ�ʽ�����һ���ԣ�Greenplum��Postgresqlһ�������ϵ�����ݿ�İ���ACID���ڵ�����������
����ͼ�������Կ�����Greenplum����С���е�Ԫ���ǽڵ�㼶��������ʵ���㼶����װ��Greenplum��ͬѧӦ�ö�����ÿ��ʵ�������Լ���postgresqlĿ¼�ṹ�����и��Ե�һ��Postgresql���ݿ��ػ����̣���������ͨ��UTģʽ���е���ʵ���ķ��ʣ�������Ϊ��ˣ�����һ�������ڵ��ڵ��ϵ�GreenplumDBҲ��һ��С�͵IJ��м���ܹ���һ��һ���ڵ�����6~8��ʵ�����൱����һ���ڵ�����6~8��Postgresql���ݿ�ͬʱ���й������������ڿ��Գ�����õ�ÿ���ڵ������CPU��IO ������
Greenplum�����ڵ��������������������ݿ�Ҳ��ܶ࣬��������ڶ�ڵ��ϣ����ṩ���ܼ��������Ե�����������һ����Ⱥ�ṩ�������ܹ������Ĵﵽ��ͳ���ݿ�����ٱ�������ǧ�������������ݴ洢��ģ�ﵽ100TB~��PB��������Ӳ���ϵ�Ͷ�룬��������̨һ���X86����������ͨ������������
Greenplum����Postgresl��Ϊ�ײ����棬���õļ�����Postgresql�Ĺ��ܣ�Postgresql�еĹ���ģ��ͽӿڻ�����99%��������Greenplum��ʹ�ã�����odbc��jdbc��oledb��perldbi��python psycopg2�ȣ�����Greenplum����������ߡ�BI�������ɵ�ʱ��dz����ף�����postgresql��contrib�е�һЩ����ģ��Greenplum�ṩ�˱�����ģ�鿪�伴�ã���oraface��postgis��pgcrypt�ȣ���������ģ�飬�û��������н�contrib�µĴ�����Greenplum��includeͷ�ļ��������̬so���ļ��������нڵ�Ϳɽ��в���ʹ���ˡ���Щģ�黹�Ƿdz����õģ�����oraface�������ϼ�����Oracle���õĺ�����Greenplum�У�������һ��PoC�����У��û��ṩ��22��Oracle SQL��䣬�����κθĶ�����������Greenplum�ϡ�
����ر���ʾ��Greenplum��������ֻ�Ǽĵ�ͬ�ڡ�Postgresql+interconnect���е���+�ֲ�ʽ���������ύ����Greenplum���з��˷dz���ĸ����ݷ����������ܺ���ҵ������ģ�飬��Щ���ܶ���Postgresqlû���ṩ�ģ�
Greenplum��������һ�нԲ��У�Parallel Everything��
ǰ�������Greenplum�ķֲ�ʽ���м���ܹ�������ÿ���ڵ�������Postgresqlʵ�����Dz��й����ģ����ֲ��е�Style�ᴩ��Greenplum������Ƶķ������棺�ⲿ�����ݼ����Dz��еġ���ѯ�ƻ�ִ���Dz��еġ������Ľ�����ʹ���Dz��еģ�ͳ����Ϣ�ռ��Dz��еġ����������������е��طֲ���㲥���������㣩�Dz��еģ�����ͷ���ۺ϶��Dz��еģ����ݻָ�Ҳ�Dz��еģ��������ݿ���ͣ��Ԫ���ݼ���ά������Ҳ���ղ��з�ʽ����ƣ������������������ڵIJ��У�Greenplum�����ݼ��غ����ݼ����б��ֳ�ǿ�������ܣ�ij��ҵ�ͻ��������:ͬ��2TB���ҵ����ݣ���Greenplum�в���һ��Сʱ�ͼ�������ˣ������û���ͳ���ݲֿ�ƽ̨�Ϻ�ʱ�������ϡ�
�ڸ��û������������У�1�������ڱ���2��10��������¼����ȫ�������У�ֻ��on��������������where��������������һ��10�����ı���������Ҫ�طֲ�����Greenplum����ʱ�����Ӿ�����ˣ���������ͳ����ƽ̨����Ϊǧ���ڼ���ģ�ı��������ܷ���ʱ��Greenplum�Ѿ�һ��������ڰ��ڼ���ģ���ϱ�������չʾ���ϼѵı��֡�
Greenplum������Share-nothing�����ܹ��ϣ���ÿһ��CPU��ÿһ�����IO����ת�����������ܹ������ֲ��д������ӵ����¡����һЩ������ͳ���ݲֿ��Sharedisk�ܹ����������ƿ��������IO�����ϣ��ڴ��ģ���ݴ���ʱ��IO����ʱfeed���ݸ���CPU��CPU��Դ����wait ��ת״̬�����������ϵͳ��Դ������SQLЧ�ʵ��£�
һ̨����16��SAS�̵�X86��������ÿ���IO����ɨ������Լ��2000MB/s���ң���������20̨�����ķ��������ɵĻ�ȺIO������40GB/s�����������IO�����Ǵ�ͳ�� Storage���Դﵽ�ġ�
(MPP Share-nothing�ܹ�ʵ�ֳ���IO��������)
���⣬Greenplum���ǽ�����ʵ�������ϵIJ��м��㣬����һ��SQL���������õ�ÿ���ڵ��ϵĶ��CPU CORE�ļ�����������X86��CPU���߳��кܺõ�֧�֣��ṩ���õ�������Ӧ�ٶȡ���PoC�нӴ�������һЩ��������ڿ���ƽ̨��MPP���������ǽ����ڽڵ㼶�IJ��У�����������������ʱ�����������Դ������ϵͳ���غ�SQLִ�����ܲ��ߡ�
��������һ��PoC���������У��г���Ҫ���ڲ����йر�CPU���̣߳����ƺ����ԭ���йأ���Ϊû�а취���õ����CPU core�ļ���������������ص����߳�����ߵ�core��������������ʹ�����������Ǹ������У���������Ҳ�������Greenplum���Ǹ������У������̻��ڿͻ��ṩ����ȫ��ͬ��Ӳ��������Greenplum��Ψһһ��������в��Եģ��ر��ڻ�ϸ��ز����У�Greenplum��80������ʱ3����Сʱ�ͳɹ�����ˣ��������̴�û����ɴ�����ԣ�Ψһ��ɵ�һ�Һ�ʱ40��Сʱ��
ǰ���ᵽ��������Postgresql��������չ�ԣ�������extension������scalability����Greenplum ���Բ��ø��ֿ�����������չ�û��Զ��庯����UDF�����Ҹ�����Python��C��fans�������½����ҷ���������Щ�Զ��庯������Greenplum����ó�����ܵ�ʵ������IJ����������ƣ�����ǿ�ҽ����û�������Ĵ�������������MPP���ݿ��UDF����In-Database�ķ�ʽ���������㽫������벻�������ܺͷ����ԣ�����������ij�ͻ�ʵ�ֵ�����ת�롢���������ȣ�ֻ��Ҫ�ĸ�дԭ�д������GP�У�ͨ�����м�������ʮ��������ߡ�
���⣬GPTEXT��lucentȫ�ļ�������Apache Madlib����Դ�ھ��㷨����SAS algorithm��R����ͨ��UDF��ʽʵ����Greenplum��Ⱥ�зֲ�ʽ���𣬴Ӷ���ÿ��ڼ���IJ���������������Է������ǣ�SAS�����������ԣ���1������¼�����ع飬����һ̨С�ͻ���ʱԼ4����Сʱ��ͨ������Greenplum��Ⱥ�У���ʱ����2���Ӿ�ȫ������ˡ���GPEXTΪ������ͼչ����Solrȫ�ļ�����Greenplum�еIJ��л����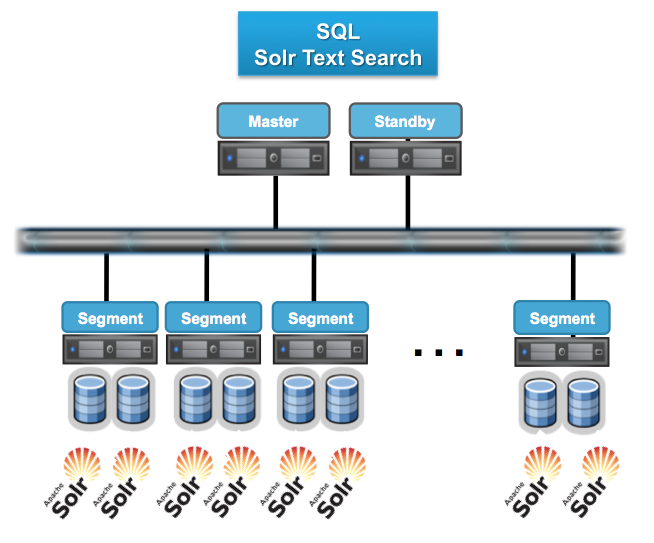
���Ҳ����ͬѧ�������⣬Greenplum����Master-slave�ܹ���Master�Ƿ���Ϊƿ������ȫ���õ��ģ�Greenplum���еIJ�����������Segment���ݽڵ�����ɺ�Masterֻ�������ɺ��Ż���ѯ�ƻ����ɷ�����Э�����ݽڵ���в��м��㡣
�����������û��ֳ��۲쵽�ģ�Master�ϵ���Դ���ĺ����г���20%�����������ΪSegment���Ǽ���ͼ��ط����ij�������Ȼ����HA���棬Greenplum�ṩStandby Master���ƽ��б�֤����
�ٽ�һ������Master-Slave�ܹ���ҵ��Ĵ����ݷֲ�ʽ������Ƽ�����ϵ�б��㷺Ӧ�ã���ҿ��Կ��������������ֲ�ʽϵͳ���Dz���Master-Slave�ܹ���������Hadoop FS��Hbase��MapReduce��Storm��Mesos������һ���ⶼ��Master-Slave�ܹ����෴������Multiple Active Master ������ϵͳ����Ҫ���ĸ�����Դ�ͻ�������֤Ԫ����һ���Ժ�ȫ������һ���ԣ��ر����ڽڵ��ģ�϶�ʱ�������������½�������ʱ���ܵ��¶�Master֮���������������ϵͳ���ϡ�
Greenplum������ʲô��
Greenplum�����ص��ܽ��һ�仰�����ڵͳɱ��Ŀ���ƽ̨�������ṩǿ��IJ������ݼ������ܺͺ������ݹ������������������Ҫָ���Dz��м����������ǶԴ�����������Ŀ��ٸ�Ч���㣬�������ָ��MPP�������ݿ��ܹ���OLTP���ݿ�һ�����ڼ��̵�ʱ�䴦�������IJ���С�����������MPP���ݿ����������μǣ����кͲ�����������ȫ��ͬ�ĸ��MPP���ݿ���Ϊ�˽�����������ƵIJ��м��㼼���������Ǵ�����С����ĸ߲�������
��ͨ��˵��Greenplum��Ҫ��λ��OLAP��������Greenplum MPP���ݿ��������ݼ�������ƽ̨�dz��ʺϣ�����:���ݲֿ�ϵͳ��ODSϵͳ��ACRMϵͳ����ʷ���ݹ���ϵͳ��������������ϵͳ���ƶ��������ϵͳ��SANDBOX��������ɳ�䡢���ݼ��еȵȡ�
��MPP���ݿⶼ���ó���OLTP����ϵͳ����ν����ϵͳ�����Ǹ�Ƶ�Ľ�����С��ģ���ݲ��롢�ġ�ɾ����ÿ��������������������ÿ���Ӷ��ᷢ����ʮ���������ٴ����Ͻ��������� ������ϵͳ�ĺ���ָ����TPS�����õ�ϵͳ��OLTP���ݿ������Gemfire���ڴ����ݿ⡣
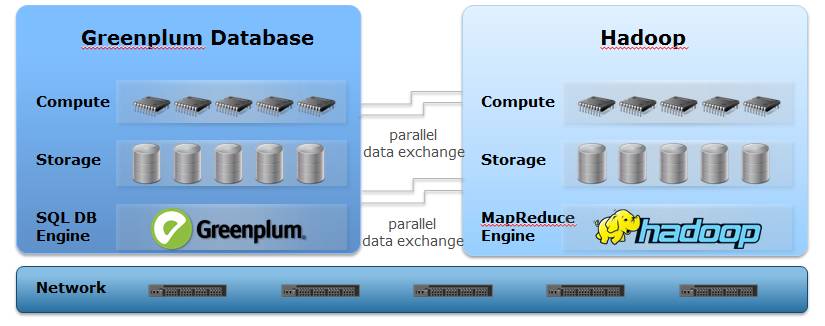
Greenplum MPP �� Hadoop
MPP��Hadoop����Ϊ�˽�����ģ���ݵIJ��м�������ֵļ��������ּ��������Ƶ����ڣ�
�����ּ��������ݴ洢�ͼ��㷽���ϣ�Ҳ���ںܶ��Զ����IJ��죺
MPP���չ�ϵ���ݿ����б���ʽ�洢���ݣ���ģʽ����Hadoop�����ļ���Ƭ��ʽ�ֲ�ʽ�洢����ģʽ�� ���߲��õ����ݷֲ����Ʋ�ͬ��MPP����Hash�ֲ�������ڵ�ʹ洢������ϣ����ݷֲ������ڼ�¼���ĸ�С���ȣ�һ����1k���£���Hadoop FS�����ļ��п��������䣬�ڵ����������ϣ����ݷֲ��������ļ��鼶��ȱʡ64MB���� MPP����SQL���в�ѯ�ƻ���Hadoop����Mapreduce���
�������ϲ�ͬ��������Ч�ʡ����ܵ����Է���Ҳ����ͬ��
1.����Ч�ʱȽϣ�
��˵˵Mapreduce������Mapreduce��ȶ�����һ�ֽ�Ϊ�������㷽ʽ��ҵ��������������������MapReduce�Ƿ������ģ������ݴ������̷ֳ�Map-��Shuffle-��Reduce�Ĺ��̣����MPP ���ݿⲢ�м�����ԣ�Mapreduce�������ڼ���ǰδ����������֯��ֻ�����˼����ݷֿ飬������ģʽ������MPPԤ�Ȼ��������Ч����֯����ģʽ�������磺���б���ϵ��Hash�ֲ����������������д洢�ȡ�ͳ����Ϣ�ռ��ȣ���;������ڼ��������Ч�ʴ�Ϊ��ͬ��
1MAPЧ�ʶԱȣ�
Hadoop��MAP����Ҫ�����ݵ��ٽ�������MPP���ݿ�ֱ��ȡ���б���Ч�ʸ� Hadoop����64MB�ֲ��ļ����������ݲ��ܱ�֤�����нڵ���ȷֲ������MAP���̵IJ��л��̶ȵͣ�MPP���ݿⰴ�����ݼ�¼��ֺ�Hash�ֲ������ȸ�ϸ�����ݷֲ������нڵ��зdz����ȣ����л��̶Ⱥܸ� Hadoop HDFSû�������������������д洢�ȼ���֧�֣���MPPͨ��������Щ�������������ݵļ���Ч�ʣ�
2ShuffleЧ�ʶԱȣ���Hadoop Shuffle �Ա�MPP�����е��طֲ���
����Hadoop������ڵ�����ԣ����Shuffle�ǻ������ⲻ�˵ģ���MPP���ݿ������ͬHash�ֲ����ݲ���Ҫ�طֲ�����ʡ���������CPU���ģ� Mapreduceû��ͳ����Ϣ������������cost-base���Ż���MPP���ݿ�����ͳ����Ϣ���ԺܺõĽ��в��м����Ż������磬���ڲ�ͬ�ֲ������ݣ������ڼ����л���Cost��̬�ľ�������ִ��·����������طֲ�����С���㲥
3ReduceЧ�ʶԱȣ����Ա���MPP���ݿ��SQLִ����-executor��
Mapreduceȱ������Join����֧�֣�MPP���ݿ���Ի���COST���Զ�ѡ��Hash join��Merger join��Nestloop join������������Hash joinͨ��COSTѡ��С����Hash����Nestloop Join��ѡ��index���join���ܵȵȣ� MPP���ݿ����Aggregation���ۺϣ��ṩMultiple-agg��Group-agg��sort-agg�ȶ��ּ������ṩ�������ܣ�Mapreuce��Ҫ������Ա�Լ�ʵ�֣�
4���⣬Mapreduce������MAP->Shuffle->Reduce������ͨ���ļ����������ݣ�Ч�ʺܵͣ�MapReduceҪ��ÿ�����������ݶ�Ҫ���л������̣�����ζ��MapReduce��ҵ��I/O�ɱ��ܸߣ����½��������͵����㷨�����ܴ�MPP���ݿ����Pipline��ʽ���ڴ��������д������ݣ�Ч�ʱ��ļ���ʽ�ߺܶࣻ
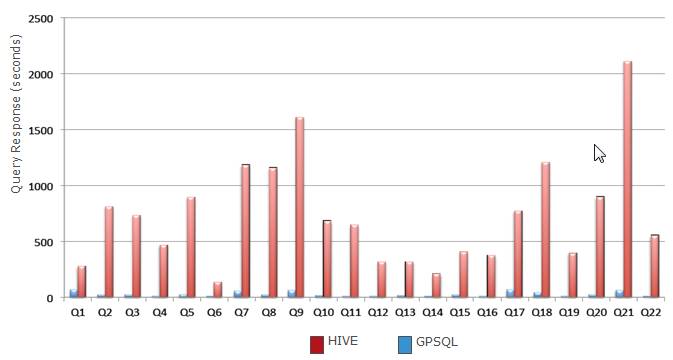
�ܽ����ϼ��㣬MPP���ݿ��ڼ��㲢�жȡ������㷨�ϱ�Hadoop����SMART��Ч�ʸ��ߣ��ڿͻ��ֳ��IJ��ԶԱ��У�Mapreduce���ڵ����ļ����пɣ������ڸ��Ӳ�ѯ�����������ȣ����ܺܲ��������ֻ��MPP���ݿ�ļ�ʮ��֮һ�������ٷ�֮һ����ͼ�ǻ���MapReduce��Hive��Greenplum MPP��TPCH 22��SQL�������ܱȽϣ�����ͬӲ�������£�
���У�ij����֪�������������ݷ���ƽ̨������֤��ͬ��Ӳ�������£�MPP���ݿ��Hadoop���ܿ�12�����ϡ�
2.�����ϵĶԱ�
MPP���ݿ����SQL��Ϊ��Ҫ����ʽ���ԣ�SQL���Լ���ѧ�����к�ǿ���ݲ��������������Ե����̿���������SQL������ר��Ϊͳ�ƺ����ݷ������������ԣ����ֹ��ܺͺ���������Ŀ��SQL���Բ����ʺϿ�����Ա��Ҳ�����ڷ���ҵ����Ա������������ݵIJ����ͽ������̡�
����MapReduce������������ѵģ���ԭ����Mapreduce������ܻ����ϵĿ�������Ҫ������Ա������JAVA�����Ͳ���ԭ��������ҵ�������Ա��ʹ�ã�����������ԱҲ����ѧϰ�Ͳٿء�Ϊ�˽�������Ե����⣬������SQL-0N-HADOOP��������ӿ�ֳ�����������Ϊ��ǰHadoop����ʹ�õ�һ�������ȵ����ơ�
��Щ����������Hive��Pivotal HAWQ��Spark SQL��Impala��Prest��Drill��Tajo�ȵȺܶ࣬��Щ������Щ����Mapreduce�������Ż�������Spark�����ڴ��е�Mapreduce�������ų����ܱȻ����ļ��ĵ�Mapreduce���10�����е������C/C++�������Java�����ع�Hadoop��Mapreuce����MapR��˾������ij֪�����̵Ĵ�����ƽ̨��������Щ��ֱ���ƿ���Mapreduce����¯���Impala��hawq���ý��MPP����˼��������ѯ�Ż����ڴ�����Pipeline���㣬�Դ���������ܡ�
��ȻSQL-On-Hadoop��ԭʼ��Mapreduce��Ȼ��������������ߣ�����SQL����Ⱥ�ϵ������Ŀǰ����MPP���ݿ��нϴ��ࣺ
3.�ܹ�����ԶԱȣ�
ǰ���ᵽ��Ϊ��֤���ݵĸ����ܼ��㣬MPP���ݿ�ڵ������֮���ǽ���ϵģ��෴��Hadoop�Ľڵ��������û����Ϲ�ϵ�ġ���;�����Hadoop�ļܹ��������-�洢�ڵ�ͼ���ڵ�����ԣ�������������2�����棺
1��չ�Է���
Hadoop�ܹ�֧�ֵ����������ݽڵ�����ڵ㣬������Hadoop��SQL-ON-HADOOPϵͳ������HAWQ��SPARK���ɵ������Ӽ����Ľڵ�����ݲ��HDFS�洢�ڵ㣬HDFS���ݴ洢�Լ������˵�����ģ� MPP���ݿ���չʱ��һ��������Ǽ���ڵ�����ݽڵ�һ�����ӵģ������ӽڵ����Ҫ���������طֲ����ܱ�֤������ڵ�Ľ���ϣ�����hash���ݣ���������֤ϵͳ�����ܣ�Hadoop�����Ӵ洢��ڵ����ȻҲ��ҪRebalance���ݣ������MPP���ԣ�������ô���ȡ�
2�ڵ��˷�����
Pivotal��GPDB ��MPP������Hadoop�ֲ�ʽ�洢������ϣ��Ƴ���HAWQ�����ݷ�������ϵͳ��ʵ����Hadoop�ϵ�SQL-on-HADOOP����������SQL-on-HADOOPϵͳ��ͬ��HAWQ֧����ȫ��SQL� ��SQL 2003 OLAP ���Cost-Base���㷨�Ż������û�����ʹ�ù�ϵ�����ݿ�һ��ʹ��Hadoop���ײ�洢����HDFS��HAWQʵ���˼���ڵ��HDFS���ݽڵ�Ľ������MR2.0��YARN��������Դ���ȣ�ͬʱ����Hadoop����������ļܹ����Ժ�MPP�ĸ�Ч�ܼ�������.
��Ȼ���е�Ҳ����ʧ��HAWQ�ļܹ���Greenplum MPP���ݿ����ڻ�üܹ���Խ�Ե�ͬʱ�������ܱ�Greenplum MPP���ݿ�Ҫ��һ�����ң���������MPP�㷨�ĺ�����HAWQ�����Դ�����������Ļ���MapReduce��SQL-on-HADOOPϵͳ��
4.ѡ��MPP����Hadoop
�ܽ�һ�£�Hadoop MapReduce��SQL-on-HADOOP����Ŀǰ�����������죬���ܺ����϶��кܶ�������Ŀռ䣬���֮�£�MPP���������ݴ����ϸ���SMART��Ҫ��ƽ����С��MPP���ݿ�֮������ܺ����ϵ�GAP��Hadoop���кܳ���һ��·Ҫ�ߡ�
��Ŀǰ������������Ϊ������ϵͳ���������õij���������˵��������������ҪƵ���ı������ͳ�ơ�������ϣ�����и��õ�SQL����ʽ֧�ֺ���������ܼ�����SQL���֧�֣���ô��Ӧ��ѡ��MPP���ݿ⣬SQL-on-Hadoop������û��Ready���ر������ݲֿ⡢���С�ODS������ʽ��������ƽ̨��ϵͳ��MPP���ݿ������Ե����ơ�
�����������ݼ��غ�ֻ�ᱻ���ڶ�ȡ�����ε���������������εķ��ʣ�������Ҫ����Batch������Ҫ����ʽ�����Լ������ܲ��Ǻ����У���HadoopҲ�Dz�����ѡ����ΪHadoop����Ҫ�㻨�ѽ϶�ľ�����ģʽ��������ݣ���ʡ����ģ����ƺ����ݼ�����Ʒ����Ͷ�롣��Щϵͳ��������ʷ����ϵͳ��ETL��ʱ�����������ݽ���ƽ̨�ȵȡ�
��֮��Bear in mind��ǧ��ҪΪ�˴����ݶ������ݣ��ͺ���ҪΪ�˴��¶�����һ������������������Ŀ���IJ�����������������ܽ���֮ǧ���ҵ�ڲ���ʧ�ܰ�����
�����һ�£�Greenplum MPP���ݿ�֧���á�Hadoop�ⲿ������ʽ�����ʡ�����Hadoop FS�����ݣ���ȻGreenplum��Hadoop�ⲿ�����ܴ������MPP�ڲ���������Hadoop ������HIVEҪ�ߺܶࣨ��ij���ڿͻ��IJ��Խ������HIVE��8�����ң�����˿��Կ�������Ŀ��ͬʱ����MPP���ݿ��Hadoop��MPP���ڽ���ʽ�����ܷ�����Hadoop��������Staging��MPP�����ݱ��ݻ�һЩETL batch��������ϴ���������ศ��ɣ��ڸ������ó��ij����з��������Ժ����ơ�
 5.δ��GP��չ֮·
��ȥʮ�꣬IT���������䷢����ʱ�̲�ͣ�ı仯��������仯�еIJ���������źͿ�Դ�ĵ�·������������ΰ�������Ƽ���ʱ���ĵ������κ�IT��������Ӳ���������������Ӳ���Ҫ�����Ƽ����ϴ���ܸ���ʱ�������ļ�����˾�������������̭��������ҲҪӵ���Ƽ��㣬�����ݽ���Ϊһ�����ݷ������ṩ��DaaS-Data as A Service�����������ṩ�����ġ����ԡ��������Ĵ����ݼ���ʹ洢�ķ���
Greenplum MPP���ݿ����һ��ʼ���ǿ��ŵļ�����������2015������Ѿ���Դ�ͳ����������ڿ�Դ��һ�������ǧ��Download��������˵��Greenplum�Ѿ�������ֻ��Pivotal��˾һ�ҵIJ�Ʒ����������Խ��Խ����֯���˻��ΪGreenplum��Contributor�����ߣ����������ķ�չ���ƶ�Greenplum MPP���ݿ������µĸ��ٷ�չ�ó̡�������һ�¿�Դ��ֱ�Ӻô����������ij�û���һ�������������������лس��������ַ�������������GP�ⲿ��gpfdistԴ���룬����һ������ɸ㶨���⣩
GreenplumҲ���ڻ�����ӵ���Ƽ��㣬Cloud Foundry��PaaS��ƽ̨���ڼ������ǰ�Greenplum MPP��ΪDaaS�������ṩ������Mesos�������Ƽ��㼼���İ����ߣ�Ҳ���Կ��Dz�������������+��Ⱥ��Դ��ܹ�������������Greenplum,�Ӷ�����ʵ���ڹ���������Դ��Ⱥ�ϵ�MPP���ݲ������Դ��������䡣 ��֮���������ſ��š���Դ���Ƽ����·����ǰ�У�Greenplum MPP���ݿ����µ�ʱ����������ʢ�����������������ٷ�չ��
| 
 /1
/1 

 |������������
|������������
 ������ 2020-4-1 13:23:52
������ 2020-4-1 13:23:52















 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������