����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
����Bigtable��(����)���ݿ�Ӧ��Խ��Խ�㣬����Ҳ�dz�ǿ�� ���Ƿdz����˻��ǰ���������ϵ�����ݿ���ʹ�ã���ԭ����ϵ�����ݿ��˼ά�������洢����ѯ�� ������hbase������������ģʽ�ı仯��
��ͳ��ϵ�����ݿ�(mysql��Oracle)���ݴ洢��ʽ��Ҫ�������£� ![]()
ͼһ ��ͼ�Ǹ��dz����͵����ݴ��淽ʽ���Ұ�ÿ����¼�ֳ�3����:��������¼���ԡ������ֶ������ǻ�������ֶν����������ﵽ����������Ч���� ��������ҵ��ķ�չ����ѯ����Խ��Խ���ӣ���Ҫ�ܶ������������ֶΣ��ҷdz���ֵ�������ڣ���������ͼ�� ![]()
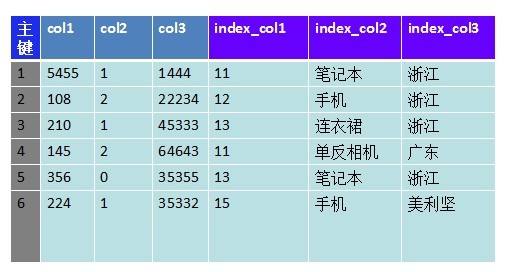
ͼ�� ��ͼ��6�������ֶΡ�ʵ������������ϰٸ������ܶ����������һ���Ҫ���ݶ�������ֶ�ˢѡ�� ��ѯ����Խ��Խ�ͣ������������ѯҪ��ϵ��������ľ���Ҳ�_ʼ���֡����Ƿdz������_ʼ�Ӵ�NoSQL�� �������ݿ�dz�ǿ�dz����˾�������ݴ�mysqlǨ��hbase���洢�ķ�ʽ���Ǹ�ͼһ����ͼ��һ��������Ϊrowkey�����������ֶε����ݡ��洢һ�������µIJ�ͬ�С� ������������ֶβ�ѯ��û�а취�����»�û�б��^�õĻ���bigtable�Ķ��������������������������ֶ�����ѯ�� ��ʱ����ʵ���ܹ�ת����˼ά���ܹ������ݵ���������������ͼ�� ![]()
ͼ�� �Ѹ��������ֶε�ֵ��Ϊrowkey��Ȼ��Ѽ�¼������������ֵ����һ��˳�������Ӧrowkey��value���ͼ������һ�����塣����ķ�ʽ�� Value��ļ�¼�ܹ����óɶ�����byte[]�������¼����ͨ����λ���ٲ�ѯ����
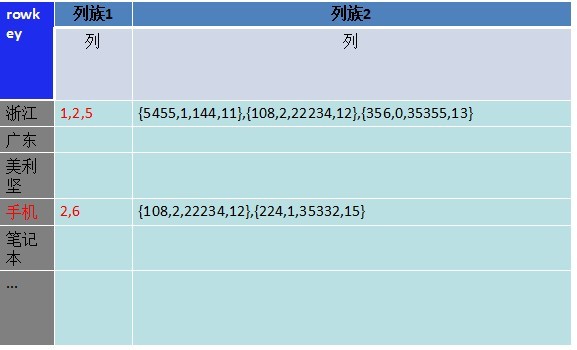
������������ʺϵ��������ֶεIJ�ѯ������Ҫͬһʱ��Զ�������ֶβ�ѯ��ͼ���ķ�ʽ��Ҫ��ȡ��ȫ��valueֵ���ȷ���ѯ���㽭��and���ֻ�������Ҫȡ������value���ٽ��������Ե�����������ÿ����¼���������ϰٸ���������Ӱ��dz��� �������ı仯�ǽ���������ֶβ�ѯ�����⡣���ǽ������ֶκ������ֶηֿ��洢�������ڲ�ͬ�������£���������ѯ������Ҫȡ������1�µ����ݣ���ȥ��С���ϵ�����2��ȡ����Ҫ��ֵ��������ͼ�ģ� ![]()
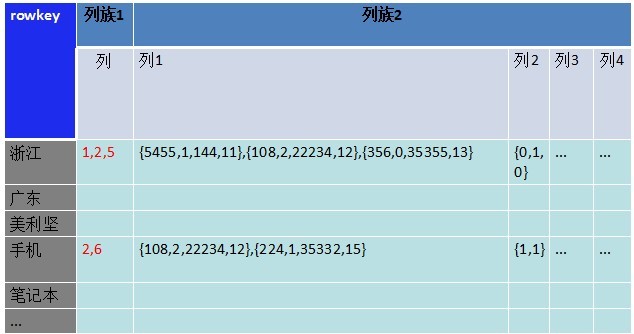
ͼ�� Ϊʲô�Dz�ͬ���壬������һ�������µ������У� �������ݿ������ļ�����������ֵġ� ��ȡ����ʱ�������һ�������ȫ�������ݶ�ȡ��������ʵ���Dz�����Ҫ�Ѽ�¼��ϸȡ�����������ⲿ�����ݷŵ��˻���һ�������¡� �������Ƕ�����2��չ������2����ܶ��������У�����������ˢѡ�����㴦������������ͼ�� ![]()
ͼ�� �����Ҹо�������Խ��Խ�������ˡ�����
| 



 /1
/1 

 |������������
|������������

 ������ 2020-12-28 14:50:40
������ 2020-12-28 14:50:40



 QQ���Ѻ�Ⱥ
QQ���Ѻ�Ⱥ QQ�ռ�
QQ�ռ� ��Ѷ��
��Ѷ�� ��Ѷ����
��Ѷ���� �ղ�
�ղ� ת��
ת�� ����
���� ����
���� ��
�� ��
�� ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������