����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
��һ���õ�����ģ�ͣ�ͨ��������Ӧ���˽����ĺ����ʹ�÷������� |0x00 ΪʲôҪ���ݽ�ģΪʲôҪ���ݽ�ģ�� ����һ����������ʱ����Ҳ����������ʱ�������ݵļ�ֵ���Զ�������Ȼ��Ҷ�֪�����ݺ���Ҫ����������ݲ��ܵõ��ܺ�Ӧ�ã���ô���ݾ�û�м�ֵ�����ݽ�ģ����Ϊ���ܹ������ݵļ�ֵ���õ��ھ�����������е�һϵ�й����� ���ݽ�ģ������һ����֯���������洢��Ӧ�����ݵķ����ۣ���Ȼ��һ�ַ����ۣ���ô���к����û��ı������ܡ��ɱ���Ч�ʡ���������ˣ����ݽ�ģ�Ĺ���������Χ�����ĸ�ָ���������Ž�����е�Ŭ���� ���ݽ�ģ�������з���λ�ĺ������ݣ������ݲɼ� - ���ݽ�ģ - ���ݿ��� - BIӦ������з������ϵĹؼ����衣 ���ݽ�ģ���ճ�����������ͨ�����ģ�� + �ֲ�ģ�ͣ����ñ�����ģ�ͽ��裬�������������ӿڵȲ�Ʒ����������ݼ�ֵ�� ��ˣ����պ��ĵ����ݽ�ģ���ۣ����������з�����ʦ�ĺ��ľ������� ���ڣ����ݽ�ģ�����۲��������⣬������ѧ�ᡣ�����ѵ��ǣ���Ҫ����������Ӧ�õĵ���Ӧ�ã���Ҫ�dz����ѵ���������ա�������ڻ�������ҵ�������������㹻��ҵ���㹻���ӣ����������㹻�õ����ݽ�ģʦ���� |0x01 ���ݽ�ģ���������������������������ݽ�ģ���ۡ� �����ڱ仯���ٵ���ҵ�����ҵ����̬���ֶ�����Ϊ���ܹ���������ԵĽ������ݽ�ģ��������ʱ���������ҵ�����γ������ݽ�ģ���IJ�����ҵ��ģ->����ģ->����ģ->������ģ������������ȷ����ҵ����ʵ���ϵ����Ͼ���Ľ�ģ������ȷ�����йؼ��ɷֺ����ԣ�������ݱ��������ݵĴ洢�ͼ��㡣 Ŀǰ���ݽ�ģ�ķ�������������Ӫ��һ���ǻ��ڹ�ϵ�����ݿ�������Ƴ����ģ��������3NF�ķ�ʽ��ģ����ȻĿǰҲ�в��ٷǹ�ϵ�����ݿ��Լ����ٰ�ṹ���ͷǽṹ�����ݡ�������ṹ��/�ǽṹ������ת��Ϊ�ṹ�����ݣ�Ȼ�������ù�ϵ�����ݿ����Ȼ��һ��ͨ�õ��������ݴ�����������һ���ǻ������ݲֿ�֮��Bill Inmon�����ά�Ƚ�ģ���ۣ��Ǵ�ȫ��ҵ�ĸ߶�����ʵ���ϵ������ҵҵ����������� �Ƚ�����ʽ��ģ������E-Rģ�͡�DATA Vaultģ�ͺ�Anchorģ�͡� E-Rģ���ǵ��͵ķ�ʽ���ֽ�ģ������3NF��ͨ��ʵ���ϵ��������ҵҵ��֮��Ĺ�ϵ��ͨ������������ģ�����������ҵ����������н�������Ϊһ�ֱ������ݽ�ģ������E-Rģ�͵�����һ���Ժ���չ�Զ��ȽϺã��Ҿ�����ʱ��Ŀ��飬���ڴ����ݶ�����ͳ��������£���ѯ���ܺͱ�ݶȶ�����һ���IJ��㣬�����ʵ��ҵ���У�����ֻӦ����DWD�㡣 DATA Vaultģ����ERģ�͵������汾����ʵ����������ֲ�ֿ���������������һ�����ִ��ڡ�DATA Vaultģ�Ͳ���ֱ������ҵ��������ݷ������ߣ���Ҫ��������֮����ܽ�����Ӧ����ָ���ͳ�ƣ�������չ�Ը��ã���ͬʱ���ܺͱ�ݶȸ�� Anchorģ���Ƕ�DATA Vault����һ���ķ�ʽ����������չ�Ը��ã����ɷ������ܸ�� �ٽ���ά�Ƚ�ģ�� ά��ģ����ҪΧ��һ��ȷ����ҵ�����չ������ȷ�������Ⱥ�ά�����ԣ��ټ�������ָ�ꡣά��ģ�͵ĵ��ͽṹ������ģ�ͣ�Ҳ�����ݱ�Ϊѩ��ģ�͡�������������ҵ�����̽����֤ʵ��Ƴ��õ�ά��ģ�ͱ�E-Rģ�����٣�����ȱ��Ҳ�Ƚ����ԣ���������̫��ά�����ԣ�����һ���Ժ���չ�Ͷ���Խϲ�Թ���ҵ��仯�ij��������Ѻá�����ά�Ƚ�ģ���ʺϴ���������OLAP�����µ����ݽ�ģ�����������ʵ��ҵ���У�ͨ��Ӧ�����м��DWS��ADS�ϲ�����ݼ��С� �������ݣ������д������鼮��������ϸ���ܣ������Ƽ��Ķ��������㹻�ˣ�һ����Kimball��ԭ�顶���ݲֿ��������ڹ����䡷��һ���ǡ�����Ͱʹ�����ʵ��֮·���� |0x02 ���ݽ�ģ�еĺ��ģ�������˻��������ݽ�ģ���ۣ����������ճ��������Ƚ�һ�º��ģ�͡� ���ݲֿ�Ķ�����ʲô����һ���������⡱�ġ����ɵġ�����ȶ��ġ���ӳ��ʷ�仯�ġ����ݼ��ϡ�������֧�ֹ������ߡ����ݲֿ��ָ��˼���ǣ��ԡ�ά�Ƚ�ģ��Ϊ�����������߾����ա������͡�ҵ����̡����С�����ģ�͡���ƣ�����һ���Ե�ά�Ⱥ���ʵ�� ����ģ����ָ����ʹ���û����ص���Ĵ������ݣ���һ����ҵ�������漰�����з��������硰���۷����������û���������ͨ�������ҵ��ϵͳ��������ϵͳ����������������ж�����⣬������Ի��ֳɸ���������⡣ ��һ�����ݲֿ����˺�����з֣�����˵����ҵ�Ķ��ҵ������зֳɲ�ͬ������ģ�ͣ��ֿɼ���ϸ��Ϊ��ͬ����������γ���һ�����й���ǰ�����νṹ���������ǰͨ�������淶���ֳ�������Ҳ��Ϊʲô����Ҫǿ�����������淶��ԭ�� ����ͼ��ʾ������DB������Log��־��ͨ����ͬ��������оۼ�����������ͬһ���������С� 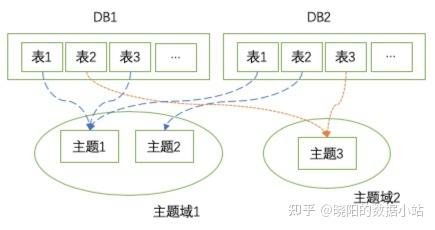  �Ӻ�۵Ķ���������������ǵ�����ģ��Ӧ��������������Ƶģ�����ҵ����ϵ�Ӵ�Ϊ���ܹ������������������ݱ���ְ�����ǽ�����ģ����ƽ�ϸ��Ϊ�������ҵ����̡� ������ҵ����̻�ά�Ƚ��г�����ҵ����̡���ά�ȡ��ļ��ϣ������ɻ��ֶ༶������������ָ����ҵ���������ҵ����̽��г���ļ��ϡ���������Ҫ�������������ҳ���ά�����£��������ױ䶯��������Ļ��ֶ���ά�Ƚ�ģ�����ڲ�����ֽ�ģ���������Ҫ���壬һ�����ҵ����������Խ�ͬ��ҵ�����ݻ��ֵ�һ���������У��ײ����ݵļӹ�����۽���ͬһ���������н��У����ϲ�Ӧ��ʱ�Ż�ӹ��������������ģ�͡� ҵ����̣�ָ��ҵ���һ�����ɲ�ֵĵ���Ϊ�¼������µ���֧�����˿����Ϊ�¼��� ��ˣ����ǿ��Լ���Ϊ������ģ�� = ������ + ҵ����̡� ����ͨ��������ģ����ƣ���۲����ϣ����Ǻ����Ļ����������ҵ����̣������ֻ��ֵĽ�����Ա�������ʽ���ֳ����ģ���˺��������ֽṹ�У�ͨ��������Ӧ���ܹ������ķֱ�����ű��������������ҵ����̣����빤������ǿ���ġ���������֮����������ͬ��֮� |0x03 ���ݽ�ģ�еķֲ������������˴�ĸ����������ʵ�ʿ���������Ҫ���Ƿֲ���ƣ���Ҳ��ά�Ƚ�ģ����꣬Ҳ�ǻ�������˾���������̽�����ó������ʵ���� �ڽ��ֲܷ�֮ǰ�������������ĸ��  ���������ֲ�����ݡ� ���ݷֲ� = ODS + CDM��DIM + DWD + DWS��+ ADS����ҵ����ʱ��Ҳ���Ժ���ijЩ�㣬����DB��Ƶ��㹻������ҵ��Ƚϼ�ODS�Ϳ��Բ��ý��衣 ODS����ETL������ƣ�ͨ�����ı����ݵ����ݣ��ص㿼��������μ�ʱ�ɿ���ͬ�������� ODS��Ϊԭʼ���ݴ洢�㣬���鱣��ȫ��������ԭʼ��¼�����������κ���ϴ������ODS��Խӵ�ϵͳ������һ��Ϊ��ϸ���ݣ��������ʵʱ���ݣ���������һ��Ϊ�յ��Ȼ�Сʱ���ȡ��������ݵ�ͬ����ʽ��ODSֻ��¼�ᷢ�����±�������ݣ������ۼƿ�����ʵ������������ʵ�����������ʱ���ϵ�ȫ��ͬ�������ᷢ������ɾ�������ݣ�����������ʵ�����������ʱ������ͬ����ODS���ı������ڣ�һ��Ϊȫ��7�졢�������á� CDM = Common Data Model���ò㲻�����Ʒ�������������ҵ����̵ij���Ͷ��壬������ģ�͵ĺ��IJ㣬һ����Ҫ�dz��ϸ�Ĺ淶������ÿ���������϶���Ҫ����CodeReview�� DIM��Ϊά���ĸ������ά�Ƚ�ģ���ۣ�����ֻ������ODS�㣬������һ���ӹ�����������DIM���ĵ�������һ��Ϊ�յ��ȣ�ͬ��DBȫ���Ŀ������ݣ�ͨ�������������������ͬ���������ǿ��ձ�����˽������ñ�������������������鱣��7�졣DIM����һЩ����Ŀ������أ����Ƿ����仯ά�ȣ�ѡ����ջ���������Ҫ���ݱ仯Ƶ�κ�ҵ����ȷ���������ά�ȴ��ڲ�ι�ϵ������ͨ��_ext������_tree������_graph�ĺ����б�ע�� DWD��Ϊ���ݲֿ���ϸ�㣬����˼·��ҪΧ��������ʵ������������ʵ�����ۼƿ�����ʵ���ȵ���ϸ������н��裬���ڶ��������ʵ�����Խ��кϲ�Ϊ��������ʵ�����ڸ���ҵ�����н��ҵ�����ѡ��һ��Ӧ�ý�Ϊͨ�õ����Ƚ���һ����ϸ������ͬʱ����Ҫ����ԭʼ���ݵ���ϴ������DWD���ĵ�������һ��Ϊ�յ��ȣ�ʱ���Ͻ���ȫ�����ձ������ٲ��ֲ�����������Ҫ���������Ƿ����Ļ�ɾ��������������Ҫʹ��ȫ��������������ͬ��Ϊȫ��7�졢�������á��������ϴ���ݵ�����ͨ������DWD�㣬���˻�����ά�����ԣ�����ά�ȡ���Ϊά�ȡ���ά�ȵ�ֱ���˻�����ʵ���У�������ϸ�����ῼ�����ಿ�ֳ�������������ѯЧ�ʡ� DWS��Ϊ���ݲֿ����㣬���ǽ������Ƶ����ݷ�����ϵ�����ݼ��У�ͳһָ��ھ�����Ҫ������ڿ�����ʵ�����ۼ�����ʵ���Ȼ�������ָ�����ݱ������Ҹ����Ƿ���������Ϊ�������ֽ��н��衣ͳ�������ϣ�DWS��DWD��ODS��ͬ��ͳ������ͨ��Ϊ��1d�����һ�죩��nd�����n�죩��cm����Ȼ�£��ȷ�ʽ�������Ҫ�趨ͨ�õĹ淶����ODS/DWD�������֡�DWS�㲻����ʱ���ϵ�ȫ����ֻ�ܸ��ݻ��ܵ�ά�Ƚ�������ͳ�ơ�DWS��Ϊ��������Ͳ���������������ܱ�����ͬһ��ҵ������н���ָ����ܼ������ȷ������ά�ȵ�ͳһ�Ҹ�Ч������������DWS�������㣬������Ӧ��ʹ�ò��Ѻã����������ADS���п�ҵ������ںϻ����ӷ�ף���˿�����DWS����ͬһҵ������ڻ��ܵ�ͬʱ��Ҳ����һ����ͨ�õĿ�ҵ����̻��ܱ��� ADS������Ӧ�á���������������������淶�������ĺ��ϸ���Ϊ���ںܶ��ֹ������������������������ADS��Ҫ�ϸ����������ȣ���ֹ��Ƶ�̫���ӵ���ά���ɱ��ܸߡ� ADS��ΪӦ�����ݴ洢�㣬����˼·�Ǹ���ҵ����������ṩ���ݷ�����ͨ��ָ�꾡����DWS���ȡ����ϸ������������ҵ����Դ�DWD���ȡ��������ֱ�Ӵ�ODS���ȡ���ݡ�ADS����չʾ������ԭ��ָ�꣨���磺�н��껨�Ѻ�ȥ�껨������ָ�꣬Ӧ���������������£�ͬ��ָ��ɲ��ṩ���� |0x04 ���ݽ�ģ�ı������������ݽ�ģ�dz���Ҫ��һ�����е��ǣ���������ݶ��Ǵ���ģ���ôҵ�����������ȷ�ľ����أ������������벻���˵Ŀ���������ͨ�����ǻ᷸����ģ��������������IJ��ã��������������������׳��������Һ����ױ����� ��ô���ݽ�ģ��α������������㣺 ��һ�㣬���ݱ��������DZ��ġ����磺�ֲ�_������_����������_ҵ�����_ҵ������_����_ͳ������_ˢ�����ڣ�ͨ��û�о��Եı���ֻ����Եı���������ݱ��������淶���ĺã����ÿ�ע�ͣ������˶���ֱ���á� �ڶ��㣬��ָ�궨���DZ��ģ������Եġ������ֶ�ͨ�������������֣�ʵ��&���ԡ�����ָ�ꡢʱ�䶨�壬ʵ�����DWS��ADS��ͳ�����ȣ��������Ǵ����ǵ�ά���й��������ģ�����ָ�꣬�ǻ���ԭ��ָ�ꡢҵ��������ϳ����ģ�ʱ�䶨�壬ͨ�����졢Сʱ�����ӵȡ����ֱ����ij̶ȣ��ܴ�һ���־��ǿ�����ָ���Ƿ�淶���Ƿ�ͳһ���ܶ˾���ġ�ָ��⡱�����ʾ�������ָ�궨��ı����� �����㣬ģ���������Dz������Ƶġ�ǰ�������У������ֶζ��������С�����ˣ�����ģ�����ÿ����С���ȶ������˶��壬�����Ĺ����У����������ֶ��������ֶοھ���Ӧ�ô���Щģ�����ܹ�ȡ������ ���ĵ㣬�����������б��ϵġ��ο�����֮ǰ����ƪ���£���ϵͳ˼����������������dz̸���ݲ��ԡ���������̽�����ݲ��ԡ��� ����㣬ͨ������������ģ�͵Ĺ淶�ԡ������Ǿ仰���˶��ǻ᷸����ģ���ô���������������ݣ������ɹ������������㣬��Ŀǰ��˾�Ƚ�ͳһ��˼·���ο�����֮ǰ�����£��������ʲ�������Ҫ�����������������ݡ��� |0xFF ���ݽ�ģ�е�Ӧ�ü�ֵ���ǹ���������ģ��ʵ������һ����Ϣ��������ϸ -> ��Ȼ��� -> �߶Ȼ��ܵ���·��ϸ������ʧ��Я������Ϣ�����١�����ϸ���ǿ��Կ���ҵ��ϸ�ڣ��ڻ�������ֻ�ܿ���һЩ�����Ե����ݣ���ô�ײ��ģ����ƶ�����ʵ�Dz��ɼ��ģ���ô����ͨ���߶Ȼ��ܵ�������ô�����ݼ�ֵ�أ� ����һ�ַ�ʽ������������̨���ṩ���ݲ�Ʒ�����ݷ��������һЩ���ݻ�����ʩ�����ḻ���ݵ�Ӧ�ó������Դ����ϴ��������ֵ�� ����һ�ַ�ʽ�������������ݵ�ҵ����̨���ṩһЩ��ҵ���Ķ��졣����������ģ����ʵ���Ѳ�����ֵ��ͨ����Ҫ���������һЩҵ���������������ļ�ֵ��
| 
 /1
/1 

 |������������
|������������
 ������ 2021-6-5 17:33:03
������ 2021-6-5 17:33:03
 ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������