����ע�ᣬ�ύ�������ݴ���ȡ����֪ʶ�ɻ���������ת������
����Ҫ ��¼ �ſ������ػ�鿴��û���ʺţ�����ע��

x
��������� 168���� �� 2016-1-27 22:15 �༭
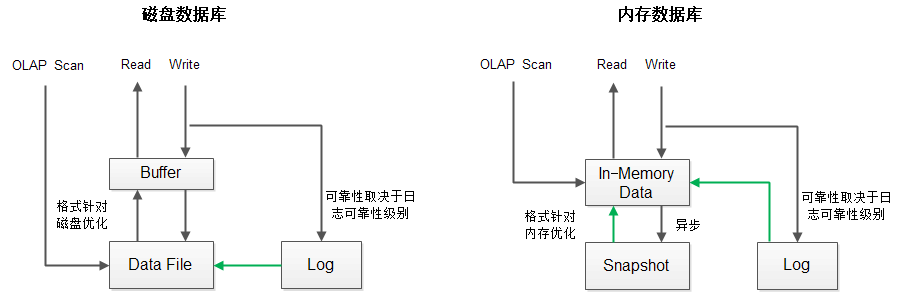
����������Ҫ�����ԡ��ڴ����ݹ������ڶ��棬�Լ������ᵽ�IJο����ס��ܶ�ͼƬҲ�����Ľ�ͼ�����������ͼƬ���»��ơ�˳��˵һ�䣬�ⲿ�����ݺܺã��ṩ���ڴ����ݿ��ѧ����ҵ��ʵ����ȫò���ܣ�����������������ϸ�ڣ��������ķ�������е�ࡣ �ڴ����ݿ�Ϊʲô�ڴ���㣨���ݿ⣩�����ƣ� ��Ҫ���߲�������
1����������ȫ�����ݣ��ڴ滺���ȵ㣺MySQL
2���ڴ洦������������������ʷ���ݣ�OceanBase��HANA
3����������ǿһ�£�ֻ���ڴ����ݿ�������� ʵʱ��������ҵ��ֵ��
1�����ں��ľ����ߣ����ٱ��������ڿ��پ��ߣ����������ڣ����ۣ�
2������һ��Ա�������ٳ����������������������������Ա��ҽ����
3�����ڹ�˾����ʡIT���������Ӳ����������Դ
���з���ϵͳ�����⣺
1�����ݾۺϣ�����ʱ������ȷ�����ȵ�
2������hadoop����ʱ�ߣ��˷���Դ
3��Ӧ�ò���㣬�˷���Դ���������� �ڴ����ݿ���Ҫ���������Ҫ����
- �ڴ���������
- ��ʹ100G-1T������ڴ����������ȻС���������ҵ���������
- �ڴ�ܴ�һ������Ҫ������ʱ���㣨Join������ȣ�
- ��Ч���ö��CPU
- �ڴ��IO����Զ���ڴ��̣�CPU�����׳�Ϊ��Դƿ������ͳ���ݿ��У�CPU�Ż����ûᱻ����ƿ���ڸǣ�
- ����ϵͳ�����������ɴ����������л�����
- ����
- �ϵ������Ƿ��ָܻ�
- ���ݻָ��ٶ�����
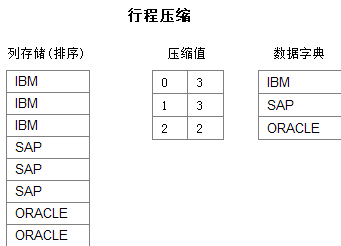
����ڴ���������������ѹ�� �ֵ�ѹ����Hana��Ĭ��ѹ�����������ƱȽϼ����ṩһ��ͼƬ˵�����ֵ�ѹ���ĺô��������ڽ�ʡ�ڴ�ռ䣬�����ڿ��Գ������CPU������������������������ݻ����˵����
�г�ѹ����RLE������������е��ֵ�ѹ���Ż��������������ִ�����ֵͬ�����㷨ʹ����ֵͬ���ظ���������ظ��ļ�¼�����⣬�г̱���ɨ��һ��ֵ���൱��ɨ���������Ķ��ֵ�������ܹ���һ����ʡCPU�ļ��㿪����
�����ϻ� HANA�����ݰ�����ҵ���������ڷ�Ϊ�����ͱ������࣬����פ�ڴ����ݣ��Լ����־û������̣�SSD�����ࡣ����趨�Ļ����ǣ�SAP��Ϊ������ҵ��洢��10������ݣ�Ȼ���������ݶ�������Ҫ���»�����ʵʱ��ѯ���ϻ����Կ�����Ӧ�ó����壬����HanaΪSQL��������ṩ��������չ CREATE TABLE lead{
id INT,
name VARCHAR(100),
description TEST,
priority INT,
create_at DATETIME,
origin INT,
result_reason INT,
status INT,
unpdated_at DATETIME),
AGING :=(
status == 4|5 &&
updated_at < SUBSTR_YEAR(Time.now, 1)
); �ý�����䶨����ϻ����ԣ�AGING���֣��ǣ�������������ʱ���Ѿ�����1�꣬�Ҷ������ڽ��ջ�ܾ�״̬����������ݿ����ϻ������������ڴ�ֻ��Ҫ�洢δ��ɣ������ʱ����һ�����ڣ��Ķ������������ݽ����ٱ���ͨ��SQL���ɨ�衣Ӧ�ó��������SQL�м��������ʶ��ǿ��Ҫ�����ݿ�ɨ�豻�����ݡ���������SQL�����ܸ��²��ֱ������ݣ�ʹ�䲻�������ϻ����ԣ���ô�������ݻ�ת��Ϊ�������ݡ� ��������˵Hana���ϻ����ƣ������ڴ�ͳ���ݿ�����DBA�ֶ�����ˮƽ�ֱ�������Ǩ�ƻ�浵����ͬ���ڣ��������౾���Ϳ�����ҵ��ģ���Ƶ����Ĺ鵵��ת�������Զ����Ĺ�����������ݿ�Ŀ�ά���ԡ� �����Ż��д洢 Ϊʲô�������ݿ�Ƚ���ʹ���д洢��
- ��ͨ��OLTP��������Ҫ���У��ֲ��ڴ��̷�����λ�ã�����ɨ��
- �������к������λij�е�һ��ֵ��IO���ۺܴ�
Hanaͬʱ֧���д洢���д洢���������ص����д洢���д洢�ɻ�����¼������ƣ�
- �ϸߵ�����ѹ����
- ͬһ���µ����ݵ����ݺ�ʽ��������ģ�ѹ��һ������ͬ�е����ݿ������������ѹ����
- ��̬��ɾ�ֶΣ��У�
- �����д洢������ɾ���У���Ҫ����ԭ�е������ڴ棬�Ա�֤�µ�������ɵ����������洢
- �����д洢������ɾ���У�����Ҫ���ٻ����һ���������ڴ�ռ�
- ����ijЩ��ѯ��CPU����������ʸ���
- ����һ�ೣ�õIJ�ѯSQL��SELECT * FROM test_table WHERE name = 'john'��ʵ����ҪCPU����ν��ƥ����н�Ϊname��
- �����д洢������һ�������������������洢��ÿ�μ��ظ����Ե�CPU����ν��ƥ��ʱ������������������������ֵ��CPU���棬�Ӷ�������CPU�Ļ��������ʡ�
- �����д洢�����е�nameֵ�������洢��CPU������ֵ����á�
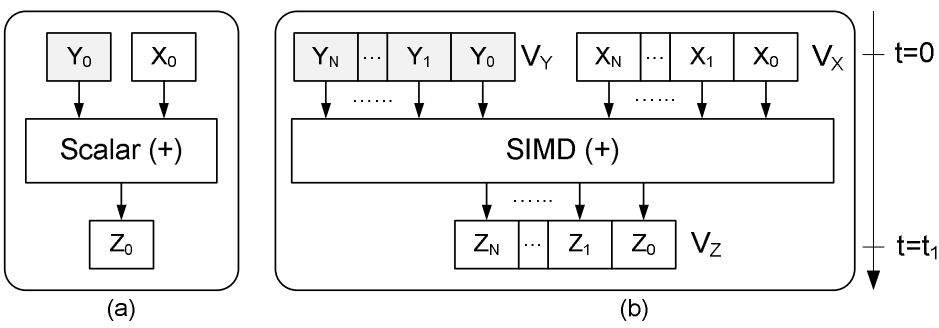
- ����SIMDָ���ü��ߵ�ɨ�����ܣ��ο�����SIMD-Scan���ִ�CPU֧�ֵ���������������������㣨��ָ���������SIMD��������ͨ��ʹ��Intel SSEָ�����ʵ�ֶ���������ͬһ���ں�cycle���������ӷ������յõ�ÿ�������ķֱ���͡�
- ����SIMD�Ľ�ѹ������һ���ֵ�ѹ�����ݿ飬��������Ϊԭʼ���ݿ顣 ������32bit����ѹ�����̶�9bit���ӣ�ʹ��4��ָ�����4��ֵ�Ľ�ѹ����
- loadָ�128bit���ص�CPU�Ĵ���
![]()
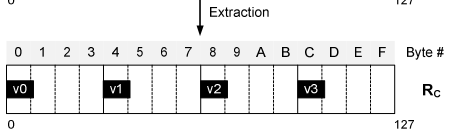
- maskָ���ǰ4��ѹ��ֵ�ֲ���4byteλ�ã�δbit���룩
![]()
- maskָ���ÿ��ѹ��ֵ��ͷ����4byteλ�ö���
![]()
- ����SIMD��ν��ƥ�䣺�����ѹ����ֱ�Ӹ���SQLν��ɸѡѹ�����ݿ飬ͨ�����ڵ�ֵ��Χ��ѯ��
- ѹ��ֵ����4�ֽڶ���
- �Ƚ�4�ֽڶ����min����
- �Ƚ�4�ֽڶ����max����
- ���ɽ������
![]()
![]()
�����ϲ�ģ�� �д洢д�������������⣺
- �����������
- Ϊ�˾����ܽ����ڴ�ռ�ã�Hanaʹ�þ������ٵĶ�����λ����ʾһ���ֵ�ֵ�������ֵ���ֻ��4��ֵ����ֻ��Ҫ��2bit��ʾ��������ֵ������ӵ�5��ֵ�������ݵ�λ����Ҫ����һλ����ᴥ��ɨ�貢�ؽ�һ�е�ȫ�����ݡ���������G���ڴ����ݴ���Ҳ�Ƿdz���ġ�
- ɾ��������������
- ɾ��һ�У���Ҫ��ȫ�������������Ⱥ��ڲ�ͬ���Ͻ���ɾ�����ܵ��¶������IJ�һ��
Ϊ�˽���������⣬�����ֻ���������������Ϊһ��д������������˼·���Ը���Ϊ��
- ������������ɾ��������������һ����С�����ݽṹ
- ������Χ�ı���������ɾ����������ͨ����̨���첽�ϲ����
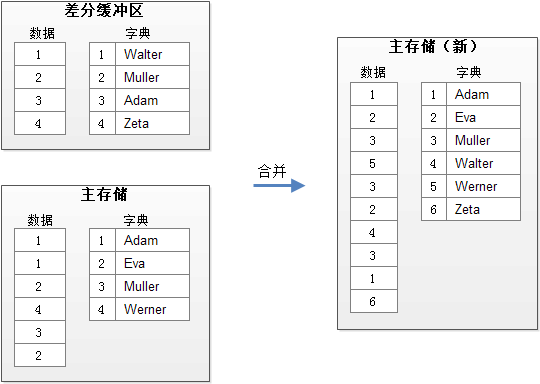
��ϤHBase��Cassandra��NoSQL���������ѣ��������֣�д������+��̨�ϲ�����ģ�Ϳ϶�����İ��������ͼƬ��ʾ����ֻ�����ά��һ�������������ڴ����ݽṹ������˳���append�µ�д�������������º�ɾ�����������еĶ���������Ҫͬʱɨ�����洢�Ͳ�ֻ����������ɺϲ��Ľ��������̨�ϲ����첽�ģ���Ӱ�����ݿ�Ķ�д��Ψһ������Ҫ�����ĵط��ںϲ���ɺ���������洢���ݵ�ʱ�̡� ���ֺ�̨�ϲ�����Ҳ�����ˣ�Hana����Ԥ���㹻���ڴ�ռ�ͬʱ�����¾����洢���ݣ���Ȼ������Ҳ������һ�����кϲ��IJ��ԣ�������Ч�Ľ��ϲ��������ʱ�ռ�������һ���е����������������
Ϊ��������ֻ����������ֵ�����Ч�ʣ����ֵ����ݽṹ�����洢��һЩ���죬��ʹ��CSB+����Cache Sensitive B+Tree�����Ǽ�������CSB+���������ǿ������ڴ��п�������Ҷ�ӽڵ㡣 ��Ҫע����ǣ���ֻ����������洢���������ֵ���ֵ��ţ�����Ҫ�ںϲ�ʱ�����µ��ֵ�
���ݿɿ��� �ڴ����ݿ����ݸ���ʧ��
- ��ͬ��
- д����ͬ���ύ����־ģ��
- ���ݿɿ���ȡ������־�ij־û����ԣ�������ݿɿ���û�б�������
- ��ͬ��
- �첽�����ڴ����ݿ���
- ���ݻָ����Ƚ����ռ��ص��ڴ棨��Ҫ��ע����Ч�����⣩���ٻط���־��
![]()
��־
��Hanaʹ���д洢ģ��ʱ���������־���log�IJ��лط����⣬ÿ�θ��¼�¼��ֵ���ֵ����������ο�����differential logging�����������ݿ�IJ���˳��Ϊ
- ����key������A
- ���и���ΪB
- ����ΪC
��ô��־��¼Ϊ
- key: A
- key: A xor B
- key: B xor C
���ջط���־�Ľ����
- A xor (A xor B) xor (B xor C) = C
������������ǿɽ����ģ������־����������˳���طţ��Ӷ�������־�طŵ����ܡ� ��Hanaʹ���д洢ģ�ͣ�ʹ�����¼��ɼ�����־�ط�
- ��־�ڴ������м�������Ӱ�����ݵ�������ƫ��λ�ã��Ӷ����ٻط�ʱ��ɨ��
- ֻ�б�ʵ���ĵ����ԲŻ�д����־�����Ǽ�¼��������
- ֧��ֻ��¼����ֵ����־���ԣ���Ĭ�ϲ��ԣ���ͬһ�е�ij������������¶�Σ�ֻ������־�д洢һ��
- ֧�ִ�����־���ֵ���գ������ֵ��ؽ�����
������Ϊ�ӿ��ջָ��ڴ����ݵ�������û������ģ�û���ᵽ�κ��Ż����������Ҷ���һ�㱣�����ʡ������2T�ĸ߶��ڴ������������512G�����ڴ����ݣ���ô��ʹ��������IO���ܴﵽ1GBps��SSD����Ҳ��Ҫ8�ֶ��ӵĻָ�ʱ�䡣 ���⣬Hana֧�ֶ�Master�ĸ���ģʽ����д����ͬ��д�뵽���������ء�
| 



 /1
/1 

 |������������
|������������

 ������ 2016-1-27 22:07:38
������ 2016-1-27 22:07:38









 QQ���Ѻ�Ⱥ
QQ���Ѻ�Ⱥ QQ�ռ�
QQ�ռ� ��Ѷ��
��Ѷ�� ��Ѷ����
��Ѷ���� �ղ�
�ղ� ת��
ת�� ����
���� ����
���� ��
�� ��
�� ������
������ �ö���
�ö��� ��Ĭ��
��Ĭ�� ������
������ ��ɫ��
��ɫ�� ǧ�ﶥ
ǧ�ﶥ ������
������